 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTARMAC: A Taxonomy for Robot Manipulation in Chemistry
Oct 22, 2025Chemistry laboratory automation aims to increase throughput, reproducibility, and safety, yet many existing systems still depend on frequent human intervention. Advances in robotics have reduced this dependency, but without a structured representation of the required skills, autonomy remains limited to bespoke, task-specific solutions with little capacity to transfer beyond their initial design. Current experiment abstractions typically describe protocol-level steps without specifying the robotic actions needed to execute them. This highlights the lack of a systematic account of the manipulation skills required for robots in chemistry laboratories. To address this gap, we introduce TARMAC - a Taxonomy for Robot Manipulation in Chemistry - a domain-specific framework that defines and organizes the core manipulations needed in laboratory practice. Based on annotated teaching-lab demonstrations and supported by experimental validation, TARMAC categorizes actions according to their functional role and physical execution requirements. Beyond serving as a descriptive vocabulary, TARMAC can be instantiated as robot-executable primitives and composed into higher-level macros, enabling skill reuse and supporting scalable integration into long-horizon workflows. These contributions provide a structured foundation for more flexible and autonomous laboratory automation. More information is available at https://tarmac-paper.github.io/
Dynamic Angle Selection in X-Ray CT: A Reinforcement Learning Approach to Optimal Stopping
Mar 16, 2025In industrial X-ray Computed Tomography (CT), the need for rapid in-line inspection is critical. Sparse-angle tomography plays a significant role in this by reducing the required number of projections, thereby accelerating processing and conserving resources. Most existing methods aim to balance reconstruction quality and scanning time, typically relying on fixed scan durations. Adaptive adjustment of the number of angles is essential; for instance, more angles may be required for objects with complex geometries or noisier projections. The concept of optimal stopping, which dynamically adjusts this balance according to varying industrial needs, remains underutilized. Building on our previous work, we integrate optimal stopping into sequential Optimal Experimental Design (OED). We propose a novel method for computing the policy gradient within the Actor-Critic framework, enabling the development of adaptive policies for informative angle selection and scan termination. Additionally, we investigated the gap between simulation and real-world applications in the context of the developed learning-based method. Our trained model, developed using synthetic data, demonstrates reliable performance when applied to real-world data. This approach enhances the flexibility of CT operations and expands the applicability of sparse-angle tomography in industrial settings.
Sequential Experimental Design for X-Ray CT Using Deep Reinforcement Learning
Jul 12, 2023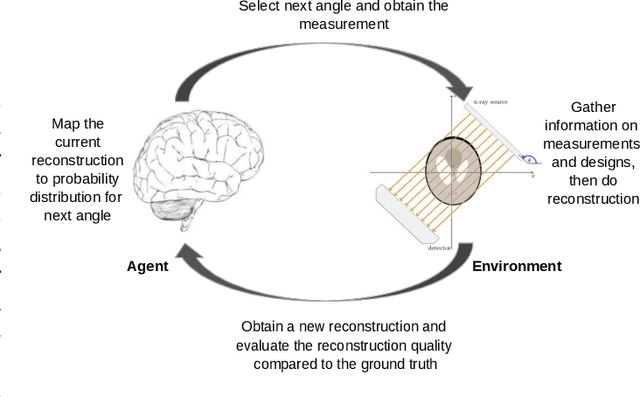
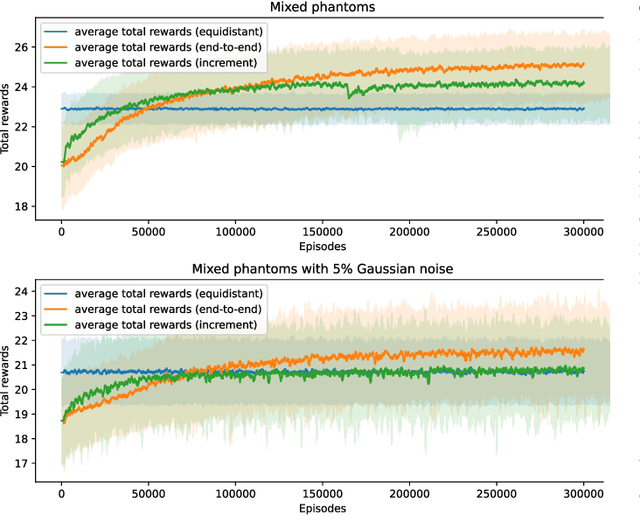
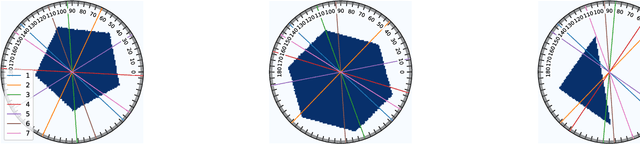
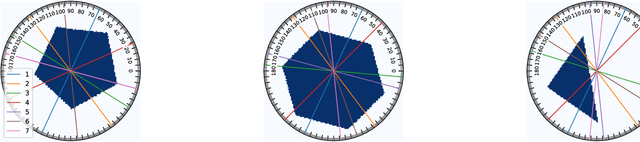
In X-ray Computed Tomography (CT), projections from many angles are acquired and used for 3D reconstruction. To make CT suitable for in-line quality control, reducing the number of angles while maintaining reconstruction quality is necessary. Sparse-angle tomography is a popular approach for obtaining 3D reconstructions from limited data. To optimize its performance, one can adapt scan angles sequentially to select the most informative angles for each scanned object. Mathematically, this corresponds to solving and optimal experimental design (OED) problem. OED problems are high-dimensional, non-convex, bi-level optimization problems that cannot be solved online, i.e., during the scan. To address these challenges, we pose the OED problem as a partially observable Markov decision process in a Bayesian framework, and solve it through deep reinforcement learning. The approach learns efficient non-greedy policies to solve a given class of OED problems through extensive offline training rather than solving a given OED problem directly via numerical optimization. As such, the trained policy can successfully find the most informative scan angles online. We use a policy training method based on the Actor-Critic approach and evaluate its performance on 2D tomography with synthetic data.