 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSR4ZCT: Self-supervised Through-plane Resolution Enhancement for CT Images with Arbitrary Resolution and Overlap
May 03, 2024Computed tomography (CT) is a widely used non-invasive medical imaging technique for disease diagnosis. The diagnostic accuracy is often affected by image resolution, which can be insufficient in practice. For medical CT images, the through-plane resolution is often worse than the in-plane resolution and there can be overlap between slices, causing difficulties in diagnoses. Self-supervised methods for through-plane resolution enhancement, which train on in-plane images and infer on through-plane images, have shown promise for both CT and MRI imaging. However, existing self-supervised methods either neglect overlap or can only handle specific cases with fixed combinations of resolution and overlap. To address these limitations, we propose a self-supervised method called SR4ZCT. It employs the same off-axis training approach while being capable of handling arbitrary combinations of resolution and overlap. Our method explicitly models the relationship between resolutions and voxel spacings of different planes to accurately simulate training images that match the original through-plane images. We highlight the significance of accurate modeling in self-supervised off-axis training and demonstrate the effectiveness of SR4ZCT using a real-world dataset.
Implicit Neural Representations for Robust Joint Sparse-View CT Reconstruction
May 03, 2024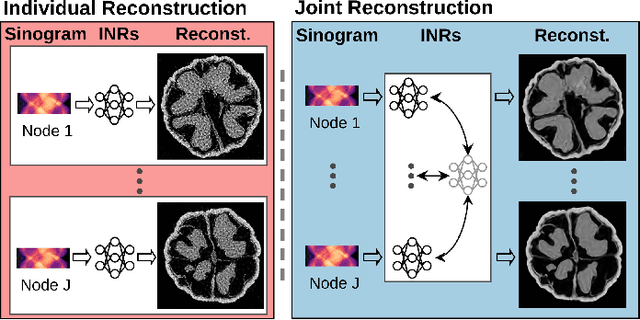
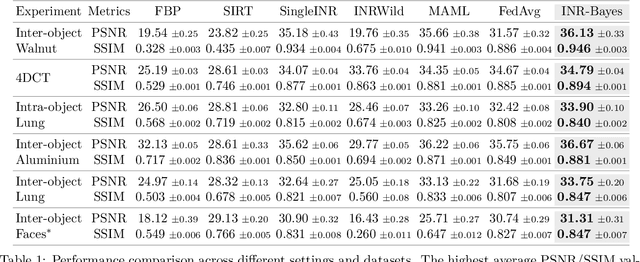
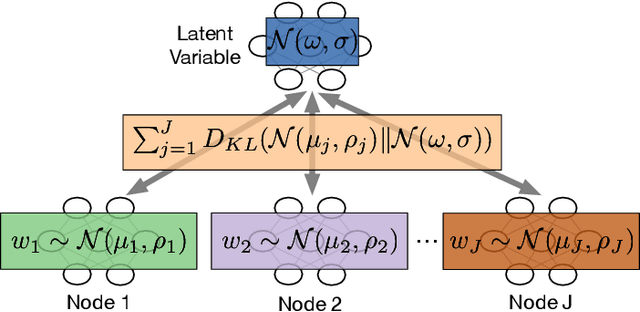
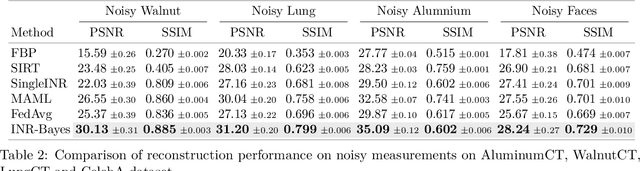
Computed Tomography (CT) is pivotal in industrial quality control and medical diagnostics. Sparse-view CT, offering reduced ionizing radiation, faces challenges due to its under-sampled nature, leading to ill-posed reconstruction problems. Recent advancements in Implicit Neural Representations (INRs) have shown promise in addressing sparse-view CT reconstruction. Recognizing that CT often involves scanning similar subjects, we propose a novel approach to improve reconstruction quality through joint reconstruction of multiple objects using INRs. This approach can potentially leverage both the strengths of INRs and the statistical regularities across multiple objects. While current INR joint reconstruction techniques primarily focus on accelerating convergence via meta-initialization, they are not specifically tailored to enhance reconstruction quality. To address this gap, we introduce a novel INR-based Bayesian framework integrating latent variables to capture the inter-object relationships. These variables serve as a dynamic reference throughout the optimization, thereby enhancing individual reconstruction fidelity. Our extensive experiments, which assess various key factors such as reconstruction quality, resistance to overfitting, and generalizability, demonstrate significant improvements over baselines in common numerical metrics. This underscores a notable advancement in CT reconstruction methods.
Multi-stage Deep Learning Artifact Reduction for Computed Tomography
Sep 01, 2023In Computed Tomography (CT), an image of the interior structure of an object is computed from a set of acquired projection images. The quality of these reconstructed images is essential for accurate analysis, but this quality can be degraded by a variety of imaging artifacts. To improve reconstruction quality, the acquired projection images are often processed by a pipeline consisting of multiple artifact-removal steps applied in various image domains (e.g., outlier removal on projection images and denoising of reconstruction images). These artifact-removal methods exploit the fact that certain artifacts are easier to remove in a certain domain compared with other domains. Recently, deep learning methods have shown promising results for artifact removal for CT images. However, most existing deep learning methods for CT are applied as a post-processing method after reconstruction. Therefore, artifacts that are relatively difficult to remove in the reconstruction domain may not be effectively removed by these methods. As an alternative, we propose a multi-stage deep learning method for artifact removal, in which neural networks are applied to several domains, similar to a classical CT processing pipeline. We show that the neural networks can be effectively trained in succession, resulting in easy-to-use and computationally efficient training. Experiments on both simulated and real-world experimental datasets show that our method is effective in reducing artifacts and superior to deep learning-based post-processing.
Noise2Inverse: Self-supervised deep convolutional denoising for linear inverse problems in imaging
Jan 31, 2020
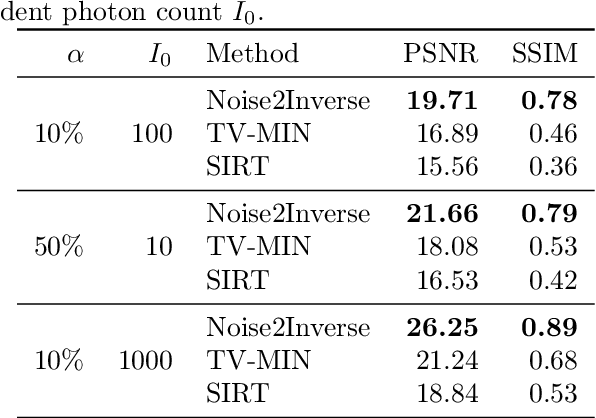
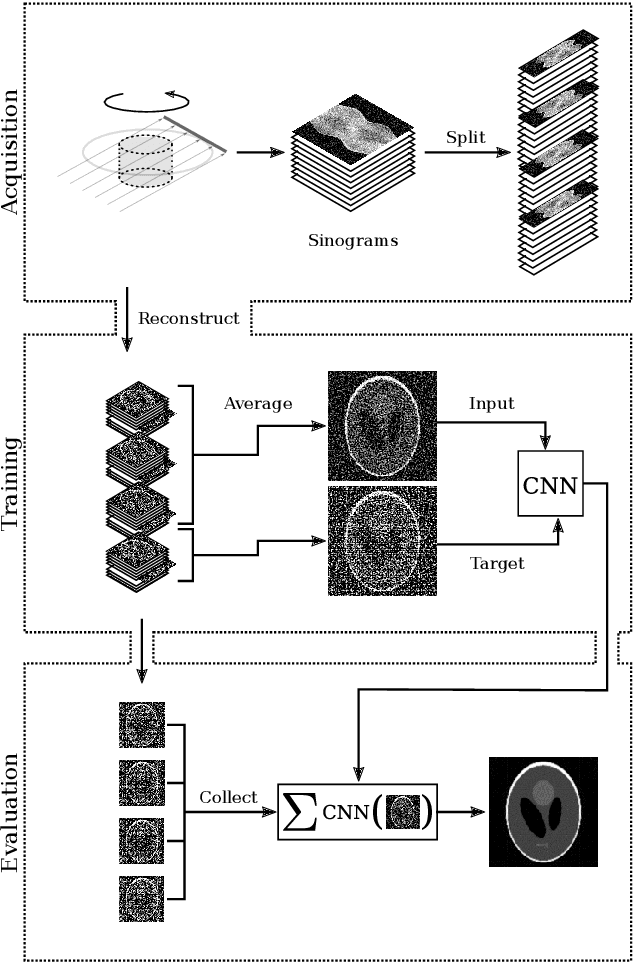

Recovering a high-quality image from noisy indirect measurement is an important problem with many applications. For such inverse problems, supervised deep convolutional neural network (CNN)-based denoising methods have shown strong results, but their success critically depends on the availability of a high-quality training dataset of similar measurements. For image denoising, methods are available that enable training without a separate training dataset by assuming that the noise in two different pixels is uncorrelated. However, this assumption does not hold for inverse problems, resulting in artifacts in the output of existing methods. Here, we propose Noise2Inverse, a deep CNN-based denoising method for linear inverse problems in imaging that does not require any additional clean or noisy data. Training a CNN-based denoiser is enabled by exploiting the noise model to compute multiple statistically independent reconstructions. We develop a theoretical framework which shows that such training indeed obtains a denoising CNN, assuming the measured noise is element-wise independent and zero-mean. On simulated CT datasets, Noise2Inverse demonstrates a substantial improvement in peak signal-to-noise ratio (> 2dB) and structural similarity index (> 30%) compared to image denoising methods and conventional reconstruction methods, such as Total-Variation Minimization. We also demonstrate that the method is able to significantly reduce noise in challenging real-world experimental datasets.