 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEAN: graph-based pruning for convolutional neural networks by extracting longest chains
Nov 13, 2020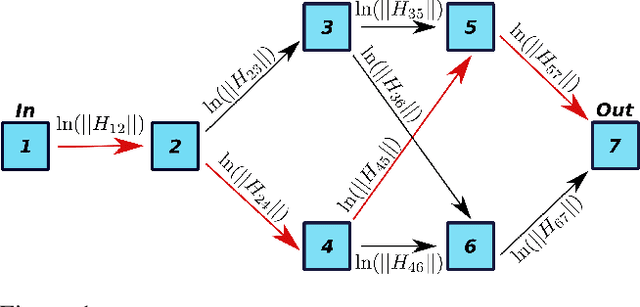
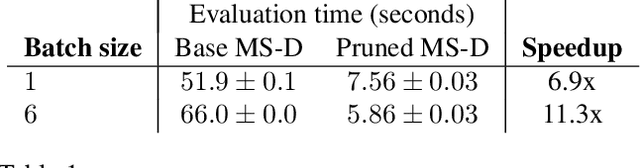
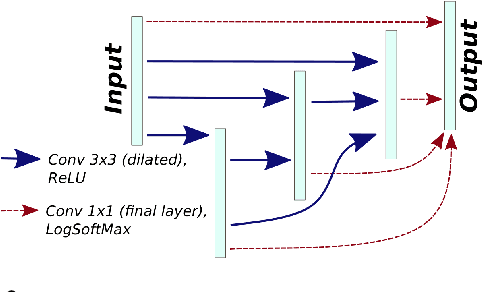
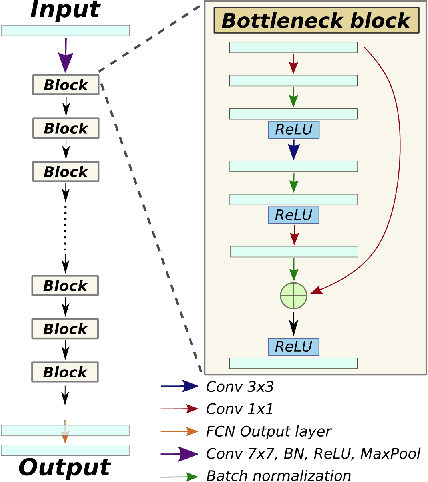
Convolutional neural networks (CNNs) have proven to be highly successful at a range of image-to-image tasks. CNNs can be computationally expensive, which can limit their applicability in practice. Model pruning can improve computational efficiency by sparsifying trained networks. Common methods for pruning CNNs determine what convolutional filters to remove by ranking filters on an individual basis. However, filters are not independent, as CNNs consist of chains of convolutions, which can result in sub-optimal filter selection. We propose a novel pruning method, LongEst-chAiN (LEAN) pruning, which takes the interdependency between the convolution operations into account. We propose to prune CNNs by using graph-based algorithms to select relevant chains of convolutions. A CNN is interpreted as a graph, with the operator norm of each convolution as distance metric for the edges. LEAN pruning iteratively extracts the highest value path from the graph to keep. In our experiments, we test LEAN pruning for several image-to-image tasks, including the well-known CamVid dataset. LEAN pruning enables us to keep just 0.5%-2% of the convolutions without significant loss of accuracy. When pruning CNNs with LEAN, we achieve a higher accuracy than pruning filters individually, and different pruned substructures emerge.
Noise2Filter: fast, self-supervised learning and real-time reconstruction for 3D Computed Tomography
Jul 03, 2020
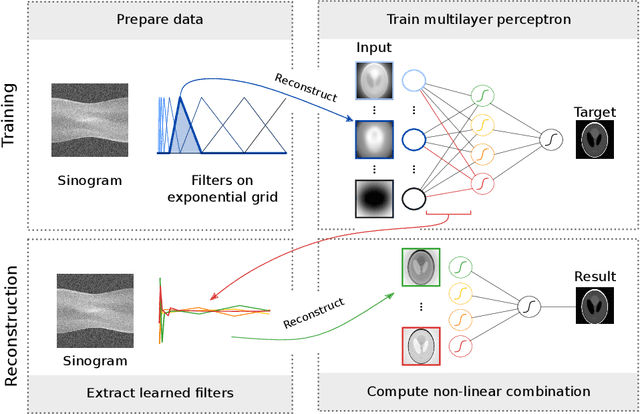
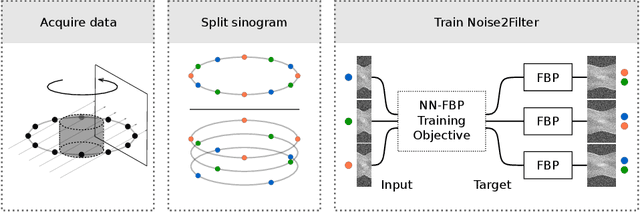
At X-ray beamlines of synchrotron light sources, the achievable time-resolution for 3D tomographic imaging of the interior of an object has been reduced to a fraction of a second, enabling rapidly changing structures to be examined. The associated data acquisition rates require sizable computational resources for reconstruction. Therefore, full 3D reconstruction of the object is usually performed after the scan has completed. Quasi-3D reconstruction -- where several interactive 2D slices are computed instead of a 3D volume -- has been shown to be significantly more efficient, and can enable the real-time reconstruction and visualization of the interior. However, quasi-3D reconstruction relies on filtered backprojection type algorithms, which are typically sensitive to measurement noise. To overcome this issue, we propose Noise2Filter, a learned filter method that can be trained using only the measured data, and does not require any additional training data. This method combines quasi-3D reconstruction, learned filters, and self-supervised learning to derive a tomographic reconstruction method that can be trained in under a minute and evaluated in real-time. We show limited loss of accuracy compared to training with additional training data, and improved accuracy compared to standard filter-based methods.
Noise2Inverse: Self-supervised deep convolutional denoising for linear inverse problems in imaging
Jan 31, 2020
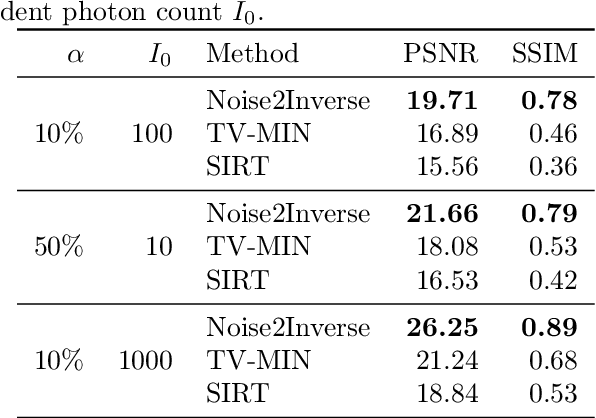
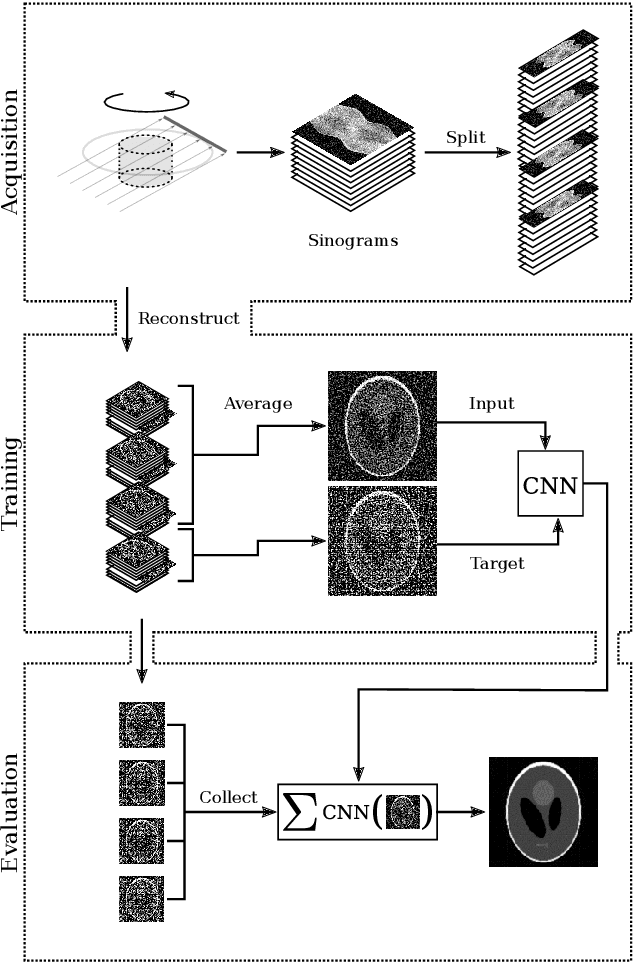

Recovering a high-quality image from noisy indirect measurement is an important problem with many applications. For such inverse problems, supervised deep convolutional neural network (CNN)-based denoising methods have shown strong results, but their success critically depends on the availability of a high-quality training dataset of similar measurements. For image denoising, methods are available that enable training without a separate training dataset by assuming that the noise in two different pixels is uncorrelated. However, this assumption does not hold for inverse problems, resulting in artifacts in the output of existing methods. Here, we propose Noise2Inverse, a deep CNN-based denoising method for linear inverse problems in imaging that does not require any additional clean or noisy data. Training a CNN-based denoiser is enabled by exploiting the noise model to compute multiple statistically independent reconstructions. We develop a theoretical framework which shows that such training indeed obtains a denoising CNN, assuming the measured noise is element-wise independent and zero-mean. On simulated CT datasets, Noise2Inverse demonstrates a substantial improvement in peak signal-to-noise ratio (> 2dB) and structural similarity index (> 30%) compared to image denoising methods and conventional reconstruction methods, such as Total-Variation Minimization. We also demonstrate that the method is able to significantly reduce noise in challenging real-world experimental datasets.