 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpace3D-Bench: Spatial 3D Question Answering Benchmark
Aug 29, 2024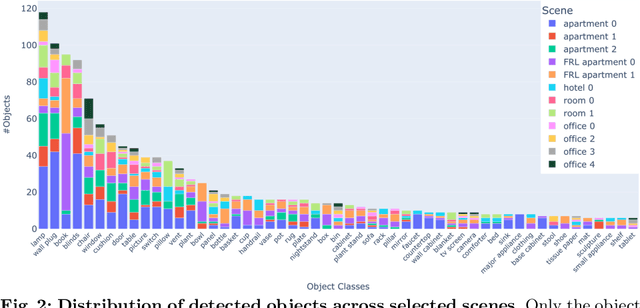
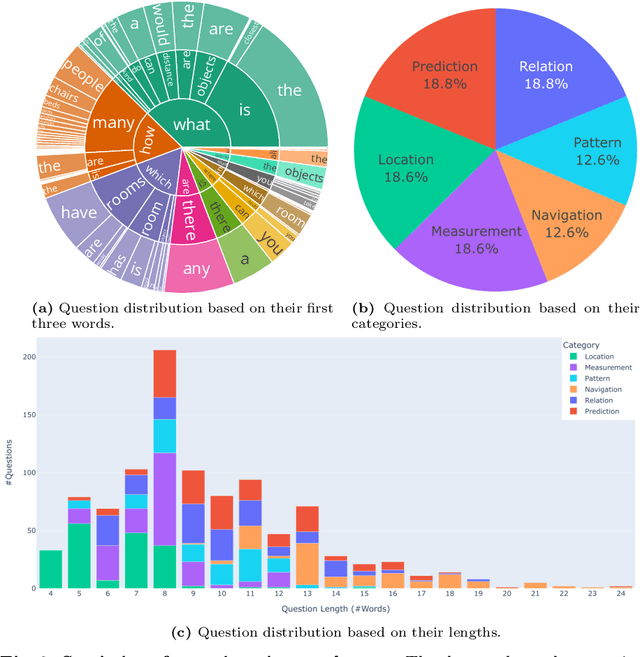
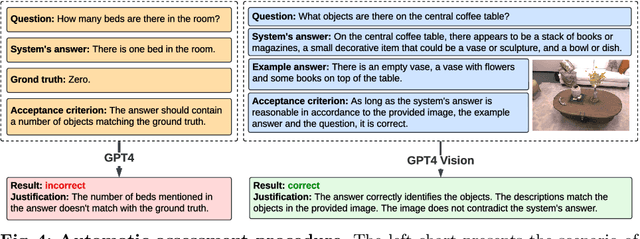
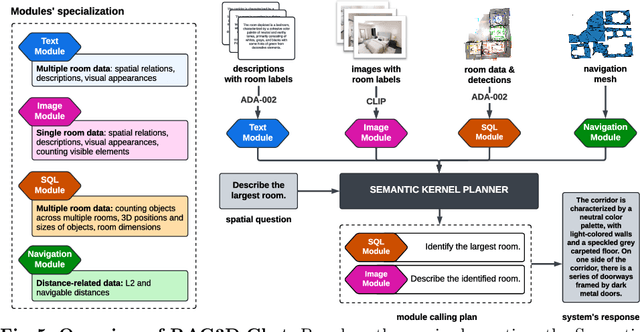
Answering questions about the spatial properties of the environment poses challenges for existing language and vision foundation models due to a lack of understanding of the 3D world notably in terms of relationships between objects. To push the field forward, multiple 3D Q&A datasets were proposed which, overall, provide a variety of questions, but they individually focus on particular aspects of 3D reasoning or are limited in terms of data modalities. To address this, we present Space3D-Bench - a collection of 1000 general spatial questions and answers related to scenes of the Replica dataset which offers a variety of data modalities: point clouds, posed RGB-D images, navigation meshes and 3D object detections. To ensure that the questions cover a wide range of 3D objectives, we propose an indoor spatial questions taxonomy inspired by geographic information systems and use it to balance the dataset accordingly. Moreover, we provide an assessment system that grades natural language responses based on predefined ground-truth answers by leveraging a Vision Language Model's comprehension of both text and images to compare the responses with ground-truth textual information or relevant visual data. Finally, we introduce a baseline called RAG3D-Chat integrating the world understanding of foundation models with rich context retrieval, achieving an accuracy of 67% on the proposed dataset.
Noise2Filter: fast, self-supervised learning and real-time reconstruction for 3D Computed Tomography
Jul 03, 2020
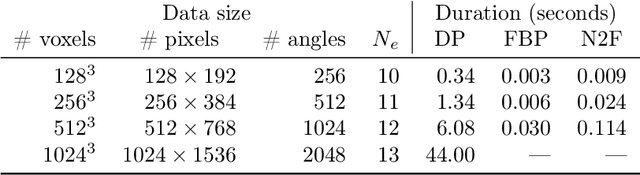
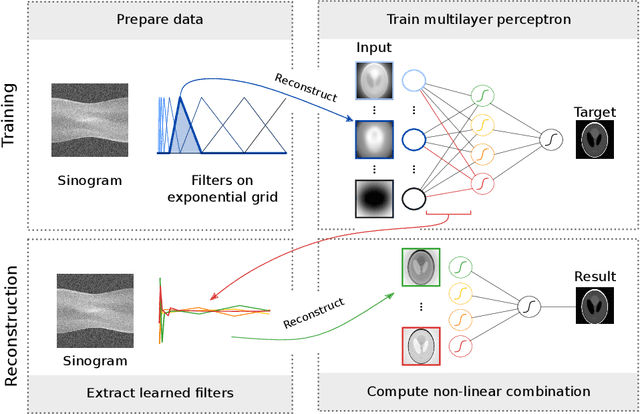
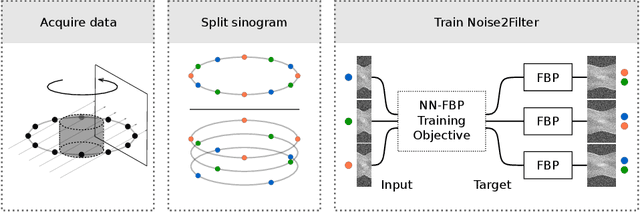
At X-ray beamlines of synchrotron light sources, the achievable time-resolution for 3D tomographic imaging of the interior of an object has been reduced to a fraction of a second, enabling rapidly changing structures to be examined. The associated data acquisition rates require sizable computational resources for reconstruction. Therefore, full 3D reconstruction of the object is usually performed after the scan has completed. Quasi-3D reconstruction -- where several interactive 2D slices are computed instead of a 3D volume -- has been shown to be significantly more efficient, and can enable the real-time reconstruction and visualization of the interior. However, quasi-3D reconstruction relies on filtered backprojection type algorithms, which are typically sensitive to measurement noise. To overcome this issue, we propose Noise2Filter, a learned filter method that can be trained using only the measured data, and does not require any additional training data. This method combines quasi-3D reconstruction, learned filters, and self-supervised learning to derive a tomographic reconstruction method that can be trained in under a minute and evaluated in real-time. We show limited loss of accuracy compared to training with additional training data, and improved accuracy compared to standard filter-based methods.