 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Optimization of Powdered Beverages Leveraging Computer Vision and Bayesian Optimization
Sep 17, 2024The growing demand for innovative research in the food industry is driving the adoption of robots in large-scale experimentation, as it offers increased precision, replicability, and efficiency in product manufacturing and evaluation. To this end, we introduce a robotic system designed to optimize food product quality, focusing on powdered cappuccino preparation as a case study. By leveraging optimization algorithms and computer vision, the robot explores the parameter space to identify the ideal conditions for producing a cappuccino with the best foam quality. The system also incorporates computer vision-driven feedback in a closed-loop control to further improve the beverage. Our findings demonstrate the effectiveness of robotic automation in achieving high repeatability and extensive parameter exploration, paving the way for more advanced and reliable food product development.
Space3D-Bench: Spatial 3D Question Answering Benchmark
Aug 29, 2024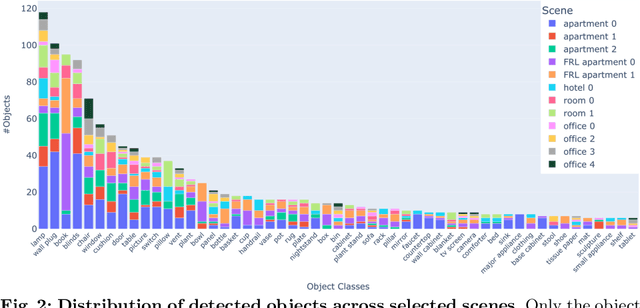
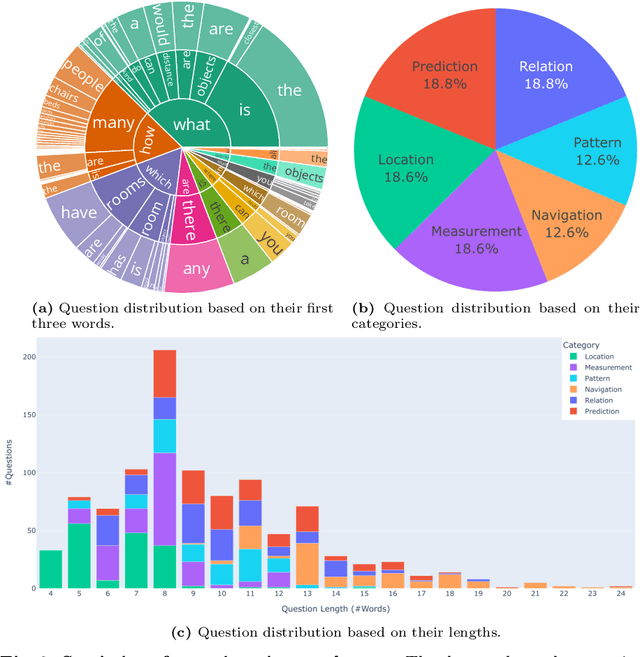
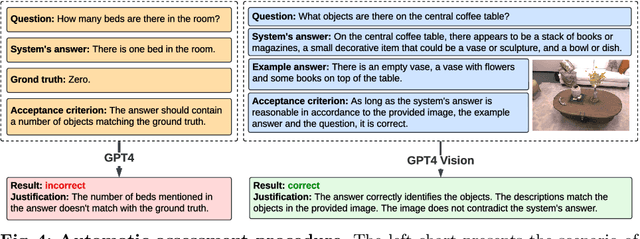
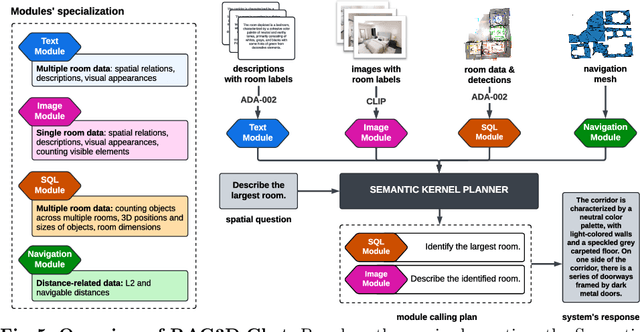
Answering questions about the spatial properties of the environment poses challenges for existing language and vision foundation models due to a lack of understanding of the 3D world notably in terms of relationships between objects. To push the field forward, multiple 3D Q&A datasets were proposed which, overall, provide a variety of questions, but they individually focus on particular aspects of 3D reasoning or are limited in terms of data modalities. To address this, we present Space3D-Bench - a collection of 1000 general spatial questions and answers related to scenes of the Replica dataset which offers a variety of data modalities: point clouds, posed RGB-D images, navigation meshes and 3D object detections. To ensure that the questions cover a wide range of 3D objectives, we propose an indoor spatial questions taxonomy inspired by geographic information systems and use it to balance the dataset accordingly. Moreover, we provide an assessment system that grades natural language responses based on predefined ground-truth answers by leveraging a Vision Language Model's comprehension of both text and images to compare the responses with ground-truth textual information or relevant visual data. Finally, we introduce a baseline called RAG3D-Chat integrating the world understanding of foundation models with rich context retrieval, achieving an accuracy of 67% on the proposed dataset.