 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models
Mar 18, 2026Multimodal Large Language Models (MLLMs) have made impressive progress in connecting vision and language, but they still struggle with spatial understanding and viewpoint-aware reasoning. Recent efforts aim to augment the input representations with geometric cues rather than explicitly teaching models to reason in 3D space. We introduce Loc3R-VLM, a framework that equips 2D Vision-Language Models with advanced 3D understanding capabilities from monocular video input. Inspired by human spatial cognition, Loc3R-VLM relies on two joint objectives: global layout reconstruction to build a holistic representation of the scene structure, and explicit situation modeling to anchor egocentric perspective. These objectives provide direct spatial supervision that grounds both perception and language in a 3D context. To ensure geometric consistency and metric-scale alignment, we leverage lightweight camera pose priors extracted from a pre-trained 3D foundation model. Loc3R-VLM achieves state-of-the-art performance in language-based localization and outperforms existing 2D- and video-based approaches on situated and general 3D question-answering benchmarks, demonstrating that our spatial supervision framework enables strong 3D understanding. Project page: https://kevinqu7.github.io/loc3r-vlm
CoPE-VideoLM: Codec Primitives For Efficient Video Language Models
Feb 13, 2026Video Language Models (VideoLMs) empower AI systems to understand temporal dynamics in videos. To fit to the maximum context window constraint, current methods use keyframe sampling which can miss both macro-level events and micro-level details due to the sparse temporal coverage. Furthermore, processing full images and their tokens for each frame incurs substantial computational overhead. To address these limitations, we propose to leverage video codec primitives (specifically motion vectors and residuals) which natively encode video redundancy and sparsity without requiring expensive full-image encoding for most frames. To this end, we introduce lightweight transformer-based encoders that aggregate codec primitives and align their representations with image encoder embeddings through a pre-training strategy that accelerates convergence during end-to-end fine-tuning. Our approach reduces the time-to-first-token by up to $86\%$ and token usage by up to $93\%$ compared to standard VideoLMs. Moreover, by varying the keyframe and codec primitive densities we are able to maintain or exceed performance on $14$ diverse video understanding benchmarks spanning general question answering, temporal reasoning, long-form understanding, and spatial scene understanding.
Space3D-Bench: Spatial 3D Question Answering Benchmark
Aug 29, 2024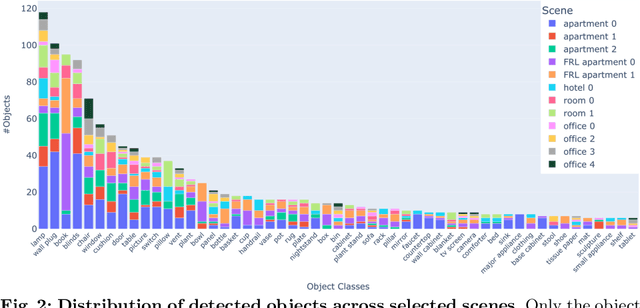
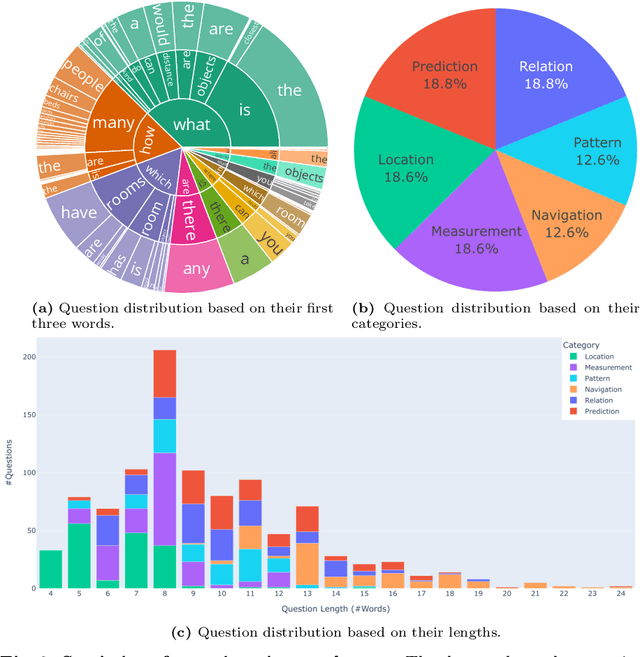
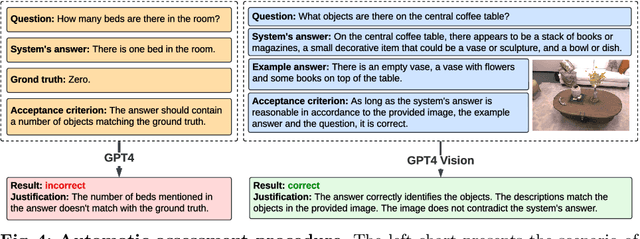
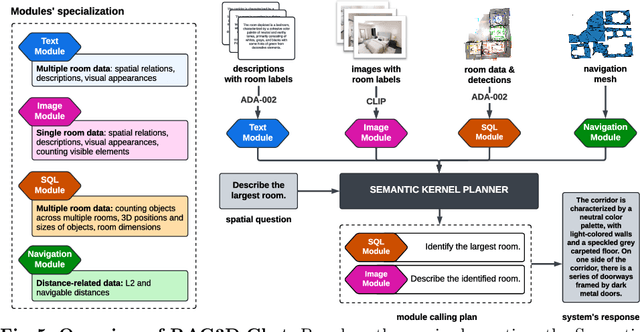
Answering questions about the spatial properties of the environment poses challenges for existing language and vision foundation models due to a lack of understanding of the 3D world notably in terms of relationships between objects. To push the field forward, multiple 3D Q&A datasets were proposed which, overall, provide a variety of questions, but they individually focus on particular aspects of 3D reasoning or are limited in terms of data modalities. To address this, we present Space3D-Bench - a collection of 1000 general spatial questions and answers related to scenes of the Replica dataset which offers a variety of data modalities: point clouds, posed RGB-D images, navigation meshes and 3D object detections. To ensure that the questions cover a wide range of 3D objectives, we propose an indoor spatial questions taxonomy inspired by geographic information systems and use it to balance the dataset accordingly. Moreover, we provide an assessment system that grades natural language responses based on predefined ground-truth answers by leveraging a Vision Language Model's comprehension of both text and images to compare the responses with ground-truth textual information or relevant visual data. Finally, we introduce a baseline called RAG3D-Chat integrating the world understanding of foundation models with rich context retrieval, achieving an accuracy of 67% on the proposed dataset.
MaRINeR: Enhancing Novel Views by Matching Rendered Images with Nearby References
Jul 18, 2024



Rendering realistic images from 3D reconstruction is an essential task of many Computer Vision and Robotics pipelines, notably for mixed-reality applications as well as training autonomous agents in simulated environments. However, the quality of novel views heavily depends of the source reconstruction which is often imperfect due to noisy or missing geometry and appearance. Inspired by the recent success of reference-based super-resolution networks, we propose MaRINeR, a refinement method that leverages information of a nearby mapping image to improve the rendering of a target viewpoint. We first establish matches between the raw rendered image of the scene geometry from the target viewpoint and the nearby reference based on deep features, followed by hierarchical detail transfer. We show improved renderings in quantitative metrics and qualitative examples from both explicit and implicit scene representations. We further employ our method on the downstream tasks of pseudo-ground-truth validation, synthetic data enhancement and detail recovery for renderings of reduced 3D reconstructions.
EgoGen: An Egocentric Synthetic Data Generator
Jan 16, 2024Understanding the world in first-person view is fundamental in Augmented Reality (AR). This immersive perspective brings dramatic visual changes and unique challenges compared to third-person views. Synthetic data has empowered third-person-view vision models, but its application to embodied egocentric perception tasks remains largely unexplored. A critical challenge lies in simulating natural human movements and behaviors that effectively steer the embodied cameras to capture a faithful egocentric representation of the 3D world. To address this challenge, we introduce EgoGen, a new synthetic data generator that can produce accurate and rich ground-truth training data for egocentric perception tasks. At the heart of EgoGen is a novel human motion synthesis model that directly leverages egocentric visual inputs of a virtual human to sense the 3D environment. Combined with collision-avoiding motion primitives and a two-stage reinforcement learning approach, our motion synthesis model offers a closed-loop solution where the embodied perception and movement of the virtual human are seamlessly coupled. Compared to previous works, our model eliminates the need for a pre-defined global path, and is directly applicable to dynamic environments. Combined with our easy-to-use and scalable data generation pipeline, we demonstrate EgoGen's efficacy in three tasks: mapping and localization for head-mounted cameras, egocentric camera tracking, and human mesh recovery from egocentric views. EgoGen will be fully open-sourced, offering a practical solution for creating realistic egocentric training data and aiming to serve as a useful tool for egocentric computer vision research. Refer to our project page: https://ego-gen.github.io/.
LaMAR: Benchmarking Localization and Mapping for Augmented Reality
Oct 19, 2022


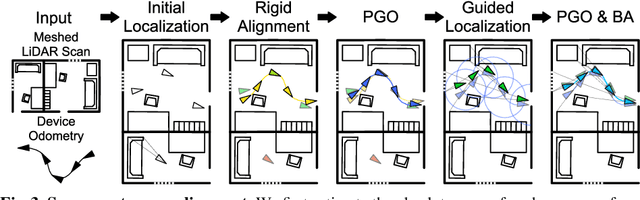
Localization and mapping is the foundational technology for augmented reality (AR) that enables sharing and persistence of digital content in the real world. While significant progress has been made, researchers are still mostly driven by unrealistic benchmarks not representative of real-world AR scenarios. These benchmarks are often based on small-scale datasets with low scene diversity, captured from stationary cameras, and lack other sensor inputs like inertial, radio, or depth data. Furthermore, their ground-truth (GT) accuracy is mostly insufficient to satisfy AR requirements. To close this gap, we introduce LaMAR, a new benchmark with a comprehensive capture and GT pipeline that co-registers realistic trajectories and sensor streams captured by heterogeneous AR devices in large, unconstrained scenes. To establish an accurate GT, our pipeline robustly aligns the trajectories against laser scans in a fully automated manner. As a result, we publish a benchmark dataset of diverse and large-scale scenes recorded with head-mounted and hand-held AR devices. We extend several state-of-the-art methods to take advantage of the AR-specific setup and evaluate them on our benchmark. The results offer new insights on current research and reveal promising avenues for future work in the field of localization and mapping for AR.
Learning-Based Dimensionality Reduction for Computing Compact and Effective Local Feature Descriptors
Sep 27, 2022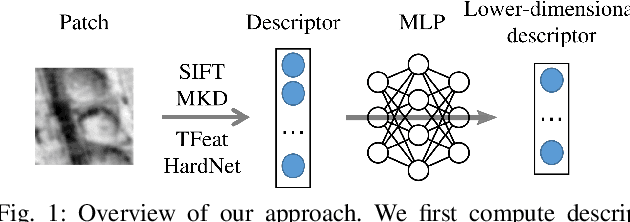
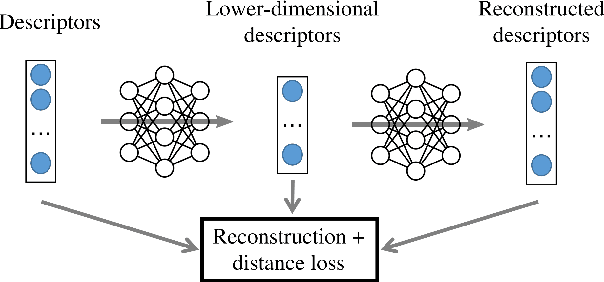
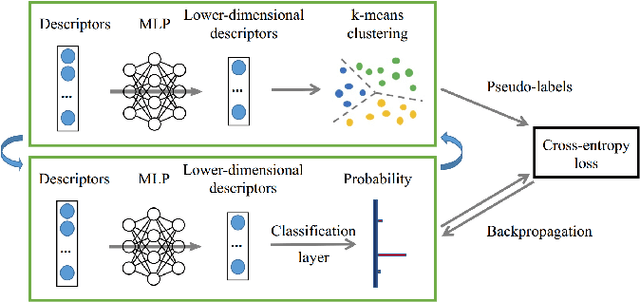
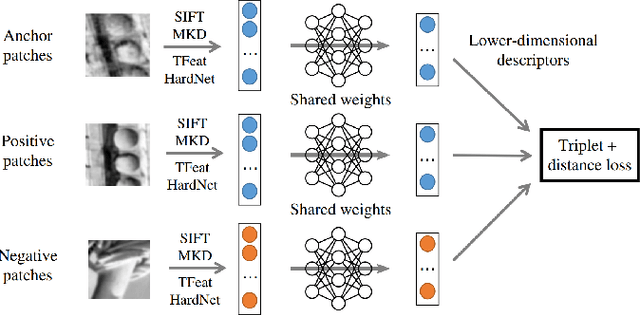
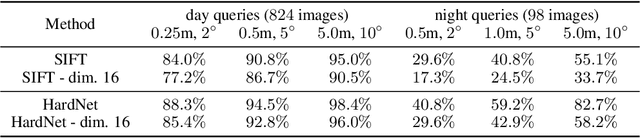
A distinctive representation of image patches in form of features is a key component of many computer vision and robotics tasks, such as image matching, image retrieval, and visual localization. State-of-the-art descriptors, from hand-crafted descriptors such as SIFT to learned ones such as HardNet, are usually high dimensional; 128 dimensions or even more. The higher the dimensionality, the larger the memory consumption and computational time for approaches using such descriptors. In this paper, we investigate multi-layer perceptrons (MLPs) to extract low-dimensional but high-quality descriptors. We thoroughly analyze our method in unsupervised, self-supervised, and supervised settings, and evaluate the dimensionality reduction results on four representative descriptors. We consider different applications, including visual localization, patch verification, image matching and retrieval. The experiments show that our lightweight MLPs achieve better dimensionality reduction than PCA. The lower-dimensional descriptors generated by our approach outperform the original higher-dimensional descriptors in downstream tasks, especially for the hand-crafted ones. The code will be available at https://github.com/PRBonn/descriptor-dr.
DeepVideoMVS: Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion
Dec 03, 2020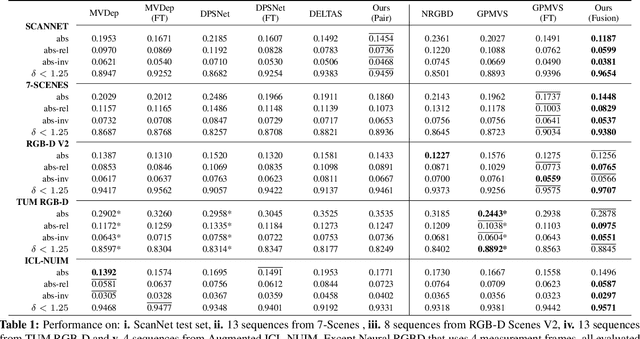
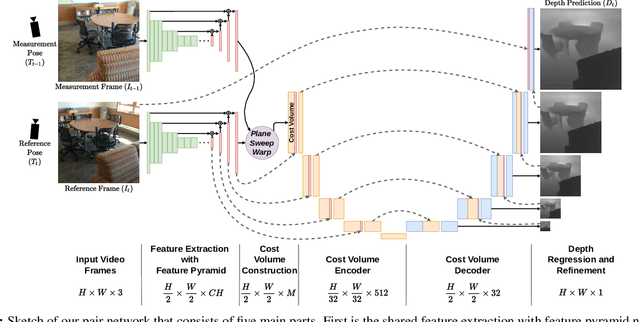
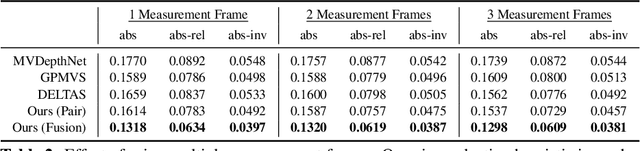
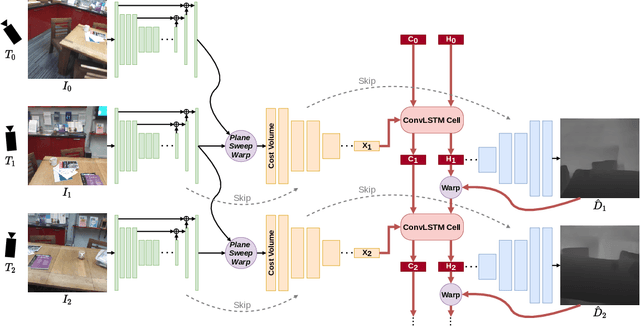
We propose an online multi-view depth prediction approach on posed video streams, where the scene geometry information computed in the previous time steps is propagated to the current time step in an efficient and geometrically plausible way. The backbone of our approach is a real-time capable, lightweight encoder-decoder that relies on cost volumes computed from pairs of images. We extend it by placing a ConvLSTM cell at the bottleneck layer, which compresses an arbitrary amount of past information in its states. The novelty lies in propagating the hidden state of the cell by accounting for the viewpoint changes between time steps. At a given time step, we warp the previous hidden state into the current camera plane using the previous depth prediction. Our extension brings only a small overhead of computation time and memory consumption, while improving the depth predictions significantly. As a result, we outperform the existing state-of-the-art multi-view stereo methods on most of the evaluated metrics in hundreds of indoor scenes while maintaining a real-time performance. Code available: https://github.com/ardaduz/deep-video-mvs
Cross-Descriptor Visual Localization and Mapping
Dec 02, 2020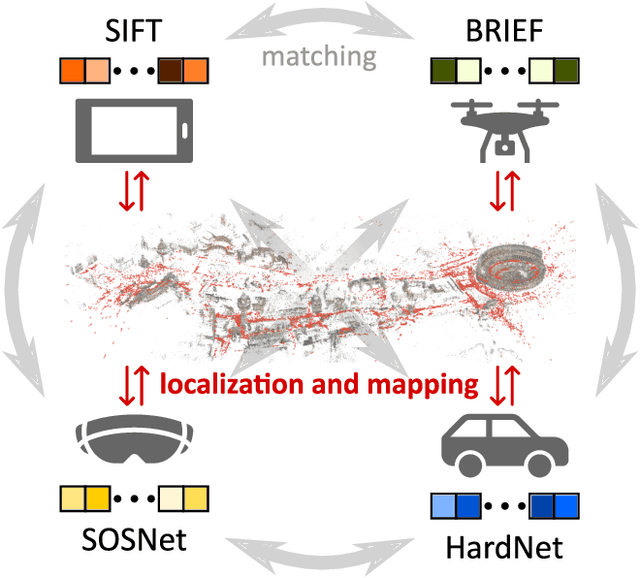
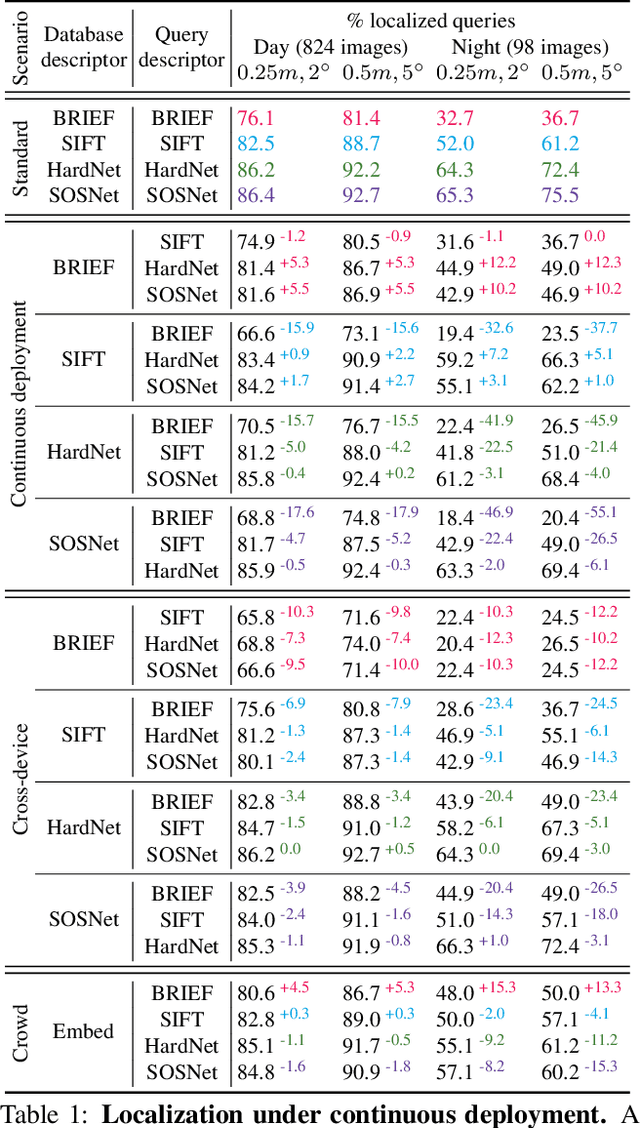
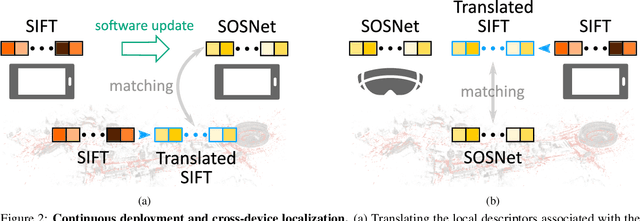
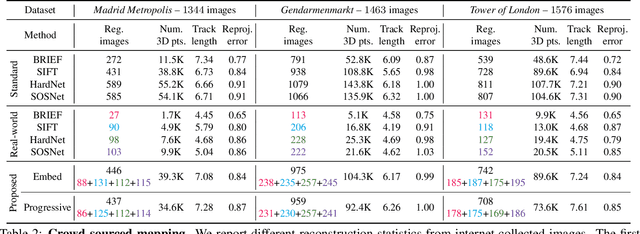
Visual localization and mapping is the key technology underlying the majority of Mixed Reality and robotics systems. Most state-of-the-art approaches rely on local features to establish correspondences between images. In this paper, we present three novel scenarios for localization and mapping which require the continuous update of feature representations and the ability to match across different feature types. While localization and mapping is a fundamental computer vision problem, the traditional setup treats it as a single-shot process using the same local image features throughout the evolution of a map. This assumes the whole process is repeated from scratch whenever the underlying features are changed. However, reiterating it is typically impossible in practice, because raw images are often not stored and re-building the maps could lead to loss of the attached digital content. To overcome the limitations of current approaches, we present the first principled solution to cross-descriptor localization and mapping. Our data-driven approach is agnostic to the feature descriptor type, has low computational requirements, and scales linearly with the number of description algorithms. Extensive experiments demonstrate the effectiveness of our approach on state-of-the-art benchmarks for a variety of handcrafted and learned features.
Privacy-Preserving Visual Feature Descriptors through Adversarial Affine Subspace Embedding
Jun 11, 2020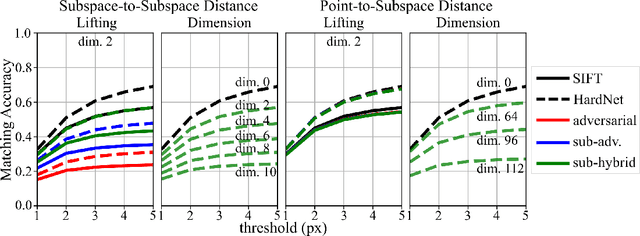
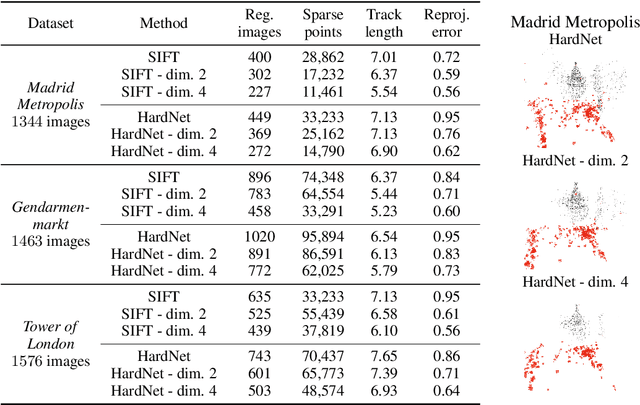

Many computer vision systems require users to upload image features to the cloud for processing and storage. Such features can be exploited to recover sensitive information about the scene or subjects, e.g., by reconstructing the appearance of the original image. To address this privacy concern, we propose a new privacy-preserving feature representation. The core idea of our work is to drop constraints from each feature descriptor by embedding it within an affine subspace containing the original feature as well as one or more adversarial feature samples. Feature matching on the privacy-preserving representation is enabled based on the notion of subspace-to-subspace distance. We experimentally demonstrate the effectiveness of our method and its high practical relevance for applications such as crowd-sourced 3D scene reconstruction and face authentication. Compared to the original features, our approach has only marginal impact on performance but makes it significantly more difficult for an adversary to recover private information.