 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaMAR: Benchmarking Localization and Mapping for Augmented Reality
Oct 19, 2022


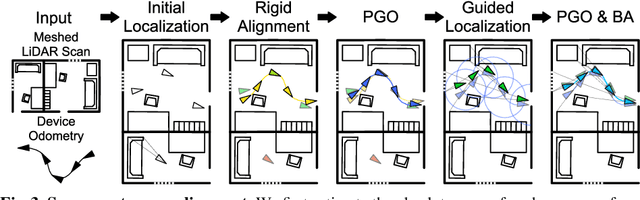
Localization and mapping is the foundational technology for augmented reality (AR) that enables sharing and persistence of digital content in the real world. While significant progress has been made, researchers are still mostly driven by unrealistic benchmarks not representative of real-world AR scenarios. These benchmarks are often based on small-scale datasets with low scene diversity, captured from stationary cameras, and lack other sensor inputs like inertial, radio, or depth data. Furthermore, their ground-truth (GT) accuracy is mostly insufficient to satisfy AR requirements. To close this gap, we introduce LaMAR, a new benchmark with a comprehensive capture and GT pipeline that co-registers realistic trajectories and sensor streams captured by heterogeneous AR devices in large, unconstrained scenes. To establish an accurate GT, our pipeline robustly aligns the trajectories against laser scans in a fully automated manner. As a result, we publish a benchmark dataset of diverse and large-scale scenes recorded with head-mounted and hand-held AR devices. We extend several state-of-the-art methods to take advantage of the AR-specific setup and evaluate them on our benchmark. The results offer new insights on current research and reveal promising avenues for future work in the field of localization and mapping for AR.
DeepVideoMVS: Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion
Dec 03, 2020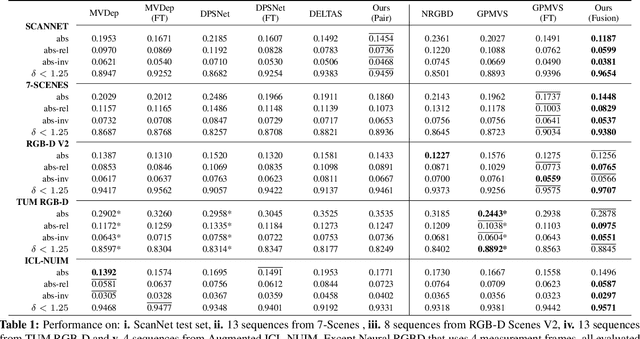
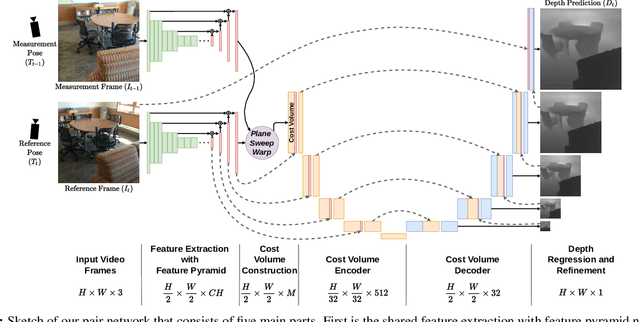
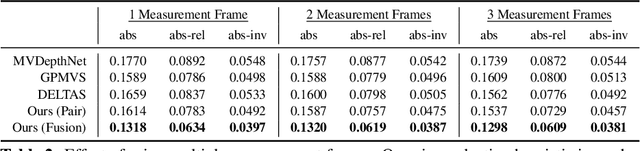
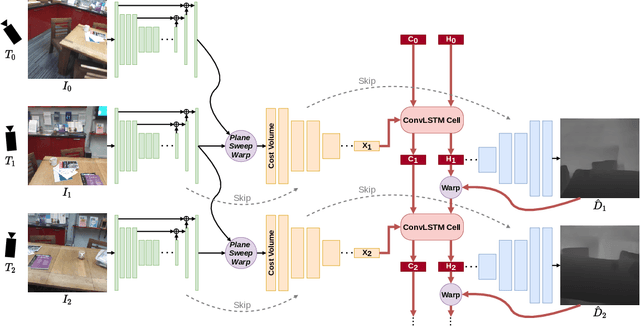
We propose an online multi-view depth prediction approach on posed video streams, where the scene geometry information computed in the previous time steps is propagated to the current time step in an efficient and geometrically plausible way. The backbone of our approach is a real-time capable, lightweight encoder-decoder that relies on cost volumes computed from pairs of images. We extend it by placing a ConvLSTM cell at the bottleneck layer, which compresses an arbitrary amount of past information in its states. The novelty lies in propagating the hidden state of the cell by accounting for the viewpoint changes between time steps. At a given time step, we warp the previous hidden state into the current camera plane using the previous depth prediction. Our extension brings only a small overhead of computation time and memory consumption, while improving the depth predictions significantly. As a result, we outperform the existing state-of-the-art multi-view stereo methods on most of the evaluated metrics in hundreds of indoor scenes while maintaining a real-time performance. Code available: https://github.com/ardaduz/deep-video-mvs
PatchmatchNet: Learned Multi-View Patchmatch Stereo
Dec 02, 2020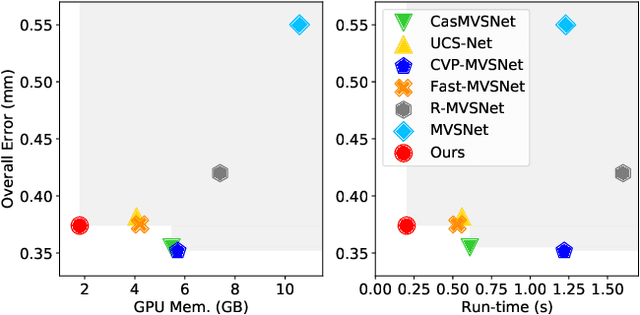
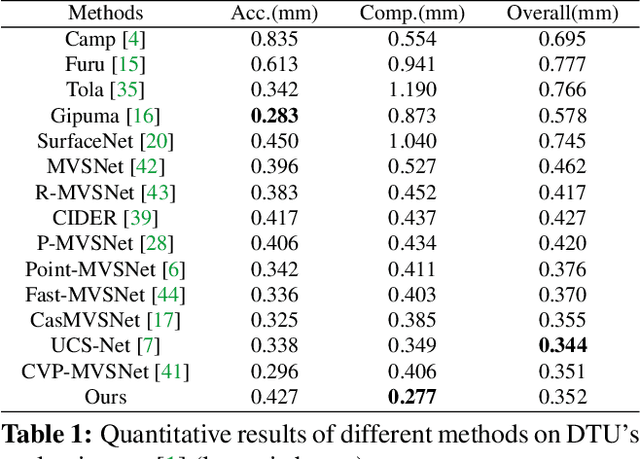
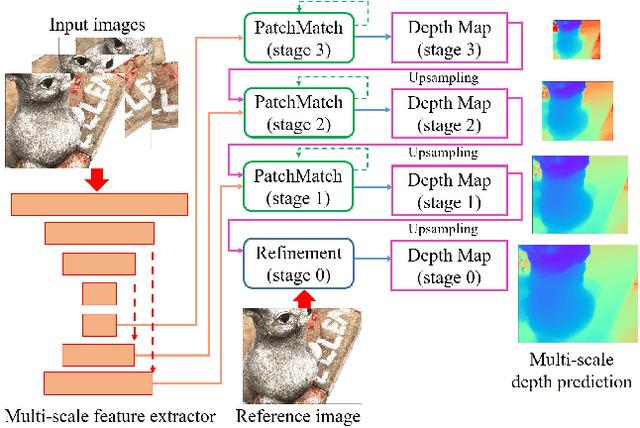
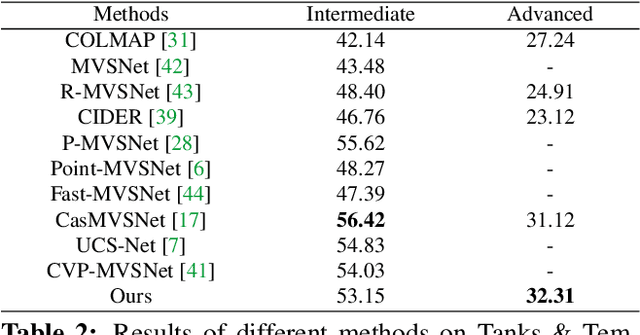
We present PatchmatchNet, a novel and learnable cascade formulation of Patchmatch for high-resolution multi-view stereo. With high computation speed and low memory requirement, PatchmatchNet can process higher resolution imagery and is more suited to run on resource limited devices than competitors that employ 3D cost volume regularization. For the first time we introduce an iterative multi-scale Patchmatch in an end-to-end trainable architecture and improve the Patchmatch core algorithm with a novel and learned adaptive propagation and evaluation scheme for each iteration. Extensive experiments show a very competitive performance and generalization for our method on DTU, Tanks & Temples and ETH3D, but at a significantly higher efficiency than all existing top-performing models: at least two and a half times faster than state-of-the-art methods with twice less memory usage.
Privacy Preserving Image-Based Localization
Mar 13, 2019
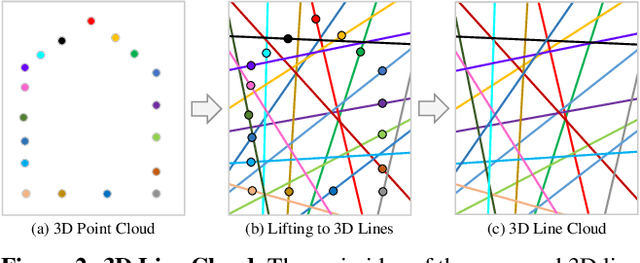
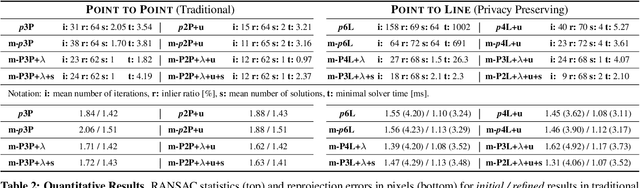
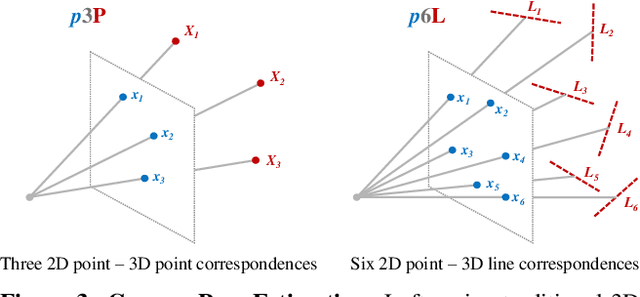
Image-based localization is a core component of many augmented/mixed reality (AR/MR) and autonomous robotic systems. Current localization systems rely on the persistent storage of 3D point clouds of the scene to enable camera pose estimation, but such data reveals potentially sensitive scene information. This gives rise to significant privacy risks, especially as for many applications 3D mapping is a background process that the user might not be fully aware of. We pose the following question: How can we avoid disclosing confidential information about the captured 3D scene, and yet allow reliable camera pose estimation? This paper proposes the first solution to what we call privacy preserving image-based localization. The key idea of our approach is to lift the map representation from a 3D point cloud to a 3D line cloud. This novel representation obfuscates the underlying scene geometry while providing sufficient geometric constraints to enable robust and accurate 6-DOF camera pose estimation. Extensive experiments on several datasets and localization scenarios underline the high practical relevance of our proposed approach.