 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoMa: Local Feature Matching Revisited
Apr 06, 2026Local feature matching has long been a fundamental component of 3D vision systems such as Structure-from-Motion (SfM), yet progress has lagged behind the rapid advances of modern data-driven approaches. The newer approaches, such as feed-forward reconstruction models, have benefited extensively from scaling dataset sizes, whereas local feature matching models are still only trained on a few mid-sized datasets. In this paper, we revisit local feature matching from a data-driven perspective. In our approach, which we call LoMa, we combine large and diverse data mixtures, modern training recipes, scaled model capacity, and scaled compute, resulting in remarkable gains in performance. Since current standard benchmarks mainly rely on collecting sparse views from successful 3D reconstructions, the evaluation of progress in feature matching has been limited to relatively easy image pairs. To address the resulting saturation of benchmarks, we collect 1000 highly challenging image pairs from internet data into a new dataset called HardMatch. Ground truth correspondences for HardMatch are obtained via manual annotation by the authors. In our extensive benchmarking suite, we find that LoMa makes outstanding progress across the board, outperforming the state-of-the-art method ALIKED+LightGlue by +18.6 mAA on HardMatch, +29.5 mAA on WxBS, +21.4 (1m, 10$^\circ$) on InLoc, +24.2 AUC on RUBIK, and +12.4 mAA on IMC 2022. We release our code and models publicly at https://github.com/davnords/LoMa.
RoMa v2: Harder Better Faster Denser Feature Matching
Nov 19, 2025Dense feature matching aims to estimate all correspondences between two images of a 3D scene and has recently been established as the gold-standard due to its high accuracy and robustness. However, existing dense matchers still fail or perform poorly for many hard real-world scenarios, and high-precision models are often slow, limiting their applicability. In this paper, we attack these weaknesses on a wide front through a series of systematic improvements that together yield a significantly better model. In particular, we construct a novel matching architecture and loss, which, combined with a curated diverse training distribution, enables our model to solve many complex matching tasks. We further make training faster through a decoupled two-stage matching-then-refinement pipeline, and at the same time, significantly reduce refinement memory usage through a custom CUDA kernel. Finally, we leverage the recent DINOv3 foundation model along with multiple other insights to make the model more robust and unbiased. In our extensive set of experiments we show that the resulting novel matcher sets a new state-of-the-art, being significantly more accurate than its predecessors. Code is available at https://github.com/Parskatt/romav2
Sparse Multiview Open-Vocabulary 3D Detection
Sep 19, 2025
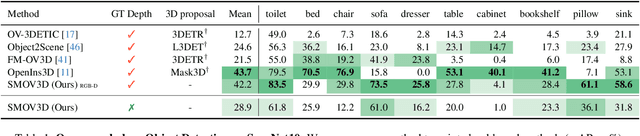
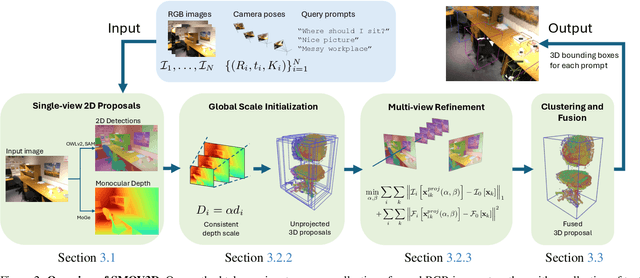

The ability to interpret and comprehend a 3D scene is essential for many vision and robotics systems. In numerous applications, this involves 3D object detection, i.e.~identifying the location and dimensions of objects belonging to a specific category, typically represented as bounding boxes. This has traditionally been solved by training to detect a fixed set of categories, which limits its use. In this work, we investigate open-vocabulary 3D object detection in the challenging yet practical sparse-view setting, where only a limited number of posed RGB images are available as input. Our approach is training-free, relying on pre-trained, off-the-shelf 2D foundation models instead of employing computationally expensive 3D feature fusion or requiring 3D-specific learning. By lifting 2D detections and directly optimizing 3D proposals for featuremetric consistency across views, we fully leverage the extensive training data available in 2D compared to 3D. Through standard benchmarks, we demonstrate that this simple pipeline establishes a powerful baseline, performing competitively with state-of-the-art techniques in densely sampled scenarios while significantly outperforming them in the sparse-view setting.
PixCuboid: Room Layout Estimation from Multi-view Featuremetric Alignment
Aug 06, 2025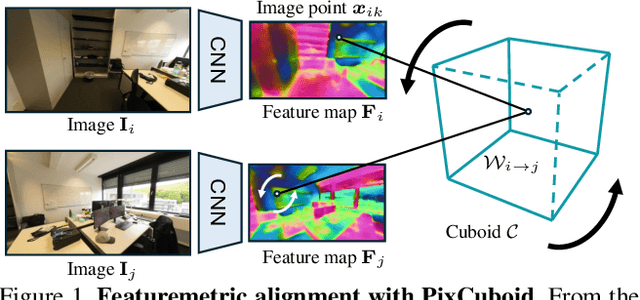
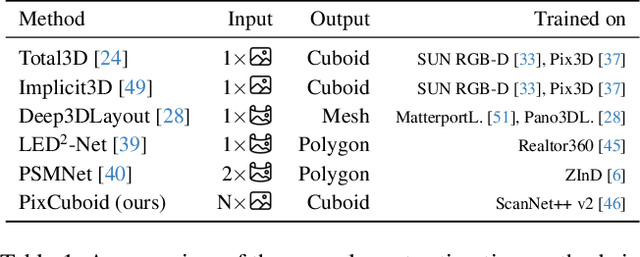
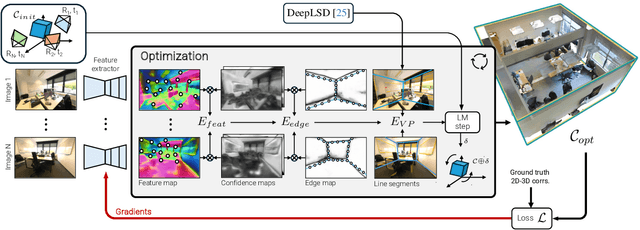
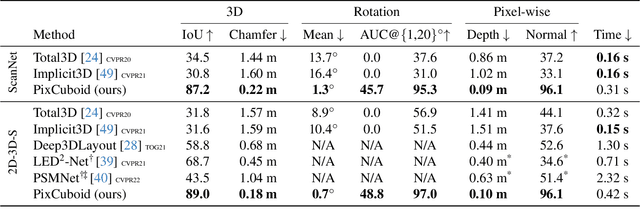
Coarse room layout estimation provides important geometric cues for many downstream tasks. Current state-of-the-art methods are predominantly based on single views and often assume panoramic images. We introduce PixCuboid, an optimization-based approach for cuboid-shaped room layout estimation, which is based on multi-view alignment of dense deep features. By training with the optimization end-to-end, we learn feature maps that yield large convergence basins and smooth loss landscapes in the alignment. This allows us to initialize the room layout using simple heuristics. For the evaluation we propose two new benchmarks based on ScanNet++ and 2D-3D-Semantics, with manually verified ground truth 3D cuboids. In thorough experiments we validate our approach and significantly outperform the competition. Finally, while our network is trained with single cuboids, the flexibility of the optimization-based approach allow us to easily extend to multi-room estimation, e.g. larger apartments or offices. Code and model weights are available at https://github.com/ghanning/PixCuboid.
Visual Re-Ranking with Non-Visual Side Information
Apr 15, 2025The standard approach for visual place recognition is to use global image descriptors to retrieve the most similar database images for a given query image. The results can then be further improved with re-ranking methods that re-order the top scoring images. However, existing methods focus on re-ranking based on the same image descriptors that were used for the initial retrieval, which we argue provides limited additional signal. In this work we propose Generalized Contextual Similarity Aggregation (GCSA), which is a graph neural network-based re-ranking method that, in addition to the visual descriptors, can leverage other types of available side information. This can for example be other sensor data (such as signal strength of nearby WiFi or BlueTooth endpoints) or geometric properties such as camera poses for database images. In many applications this information is already present or can be acquired with low effort. Our architecture leverages the concept of affinity vectors to allow for a shared encoding of the heterogeneous multi-modal input. Two large-scale datasets, covering both outdoor and indoor localization scenarios, are utilized for training and evaluation. In experiments we show significant improvement not only on image retrieval metrics, but also for the downstream visual localization task.
Fixing the RANSAC Stopping Criterion
Mar 10, 2025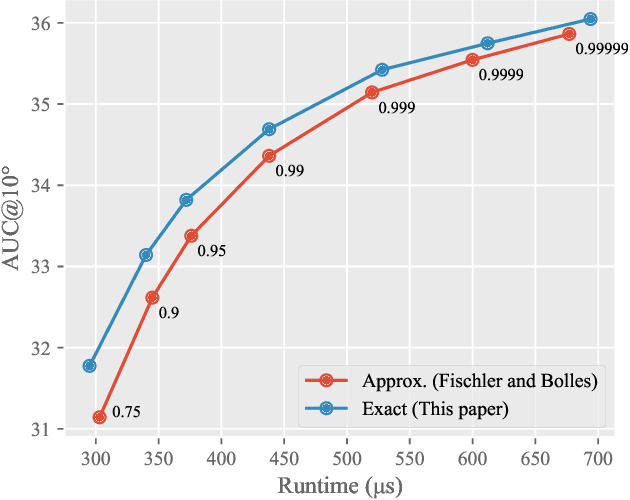

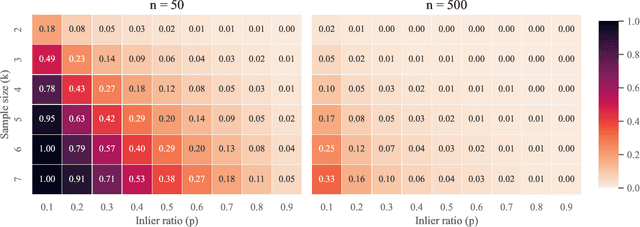

For several decades, RANSAC has been one of the most commonly used robust estimation algorithms for many problems in computer vision and related fields. The main contribution of this paper lies in addressing a long-standing error baked into virtually any system building upon the RANSAC algorithm. Since its inception in 1981 by Fischler and Bolles, many variants of RANSAC have been proposed on top of the same original idea relying on the fact that random sampling has a high likelihood of generating a good hypothesis from minimal subsets of measurements. An approximation to the sampling probability was originally derived by the paper in 1981 in support of adaptively stopping RANSAC and is, as such, used in the vast majority of today's RANSAC variants and implementations. The impact of this approximation has since not been questioned or thoroughly studied by any of the later works. As we theoretically derive and practically demonstrate in this paper, the approximation leads to severe undersampling and thus failure to find good models. The discrepancy is especially pronounced in challenging scenarios with few inliers and high model complexity. An implementation of computing the exact probability is surprisingly simple yet highly effective and has potentially drastic impact across a large range of computer vision systems.
Relative Pose Estimation through Affine Corrections of Monocular Depth Priors
Jan 09, 2025



Monocular depth estimation (MDE) models have undergone significant advancements over recent years. Many MDE models aim to predict affine-invariant relative depth from monocular images, while recent developments in large-scale training and vision foundation models enable reasonable estimation of metric (absolute) depth. However, effectively leveraging these predictions for geometric vision tasks, in particular relative pose estimation, remains relatively under explored. While depths provide rich constraints for cross-view image alignment, the intrinsic noise and ambiguity from the monocular depth priors present practical challenges to improving upon classic keypoint-based solutions. In this paper, we develop three solvers for relative pose estimation that explicitly account for independent affine (scale and shift) ambiguities, covering both calibrated and uncalibrated conditions. We further propose a hybrid estimation pipeline that combines our proposed solvers with classic point-based solvers and epipolar constraints. We find that the affine correction modeling is beneficial to not only the relative depth priors but also, surprisingly, the ``metric" ones. Results across multiple datasets demonstrate large improvements of our approach over classic keypoint-based baselines and PnP-based solutions, under both calibrated and uncalibrated setups. We also show that our method improves consistently with different feature matchers and MDE models, and can further benefit from very recent advances on both modules. Code is available at https://github.com/MarkYu98/madpose.
Robust Incremental Structure-from-Motion with Hybrid Features
Sep 29, 2024


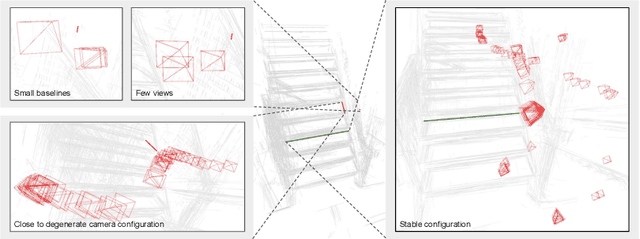
Structure-from-Motion (SfM) has become a ubiquitous tool for camera calibration and scene reconstruction with many downstream applications in computer vision and beyond. While the state-of-the-art SfM pipelines have reached a high level of maturity in well-textured and well-configured scenes over the last decades, they still fall short of robustly solving the SfM problem in challenging scenarios. In particular, weakly textured scenes and poorly constrained configurations oftentimes cause catastrophic failures or large errors for the primarily keypoint-based pipelines. In these scenarios, line segments are often abundant and can offer complementary geometric constraints. Their large spatial extent and typically structured configurations lead to stronger geometric constraints as compared to traditional keypoint-based methods. In this work, we introduce an incremental SfM system that, in addition to points, leverages lines and their structured geometric relations. Our technical contributions span the entire pipeline (mapping, triangulation, registration) and we integrate these into a comprehensive end-to-end SfM system that we share as an open-source software with the community. We also present the first analytical method to propagate uncertainties for 3D optimized lines via sensitivity analysis. Experiments show that our system is consistently more robust and accurate compared to the widely used point-based state of the art in SfM -- achieving richer maps and more precise camera registrations, especially under challenging conditions. In addition, our uncertainty-aware localization module alone is able to consistently improve over the state of the art under both point-alone and hybrid setups.
Revisiting Sampson Approximations for Geometric Estimation Problems
Jan 13, 2024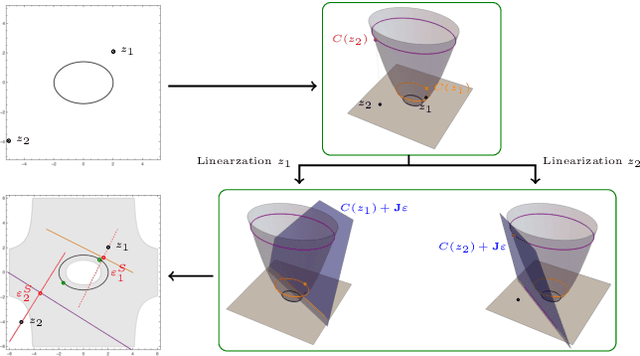

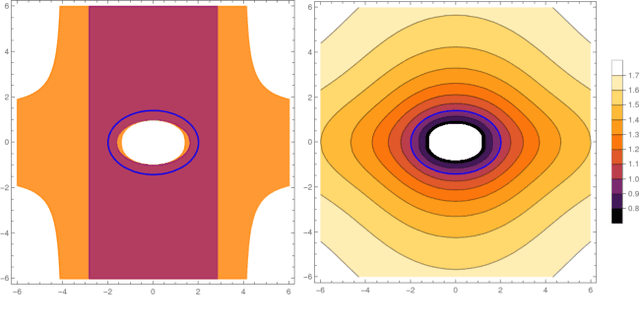
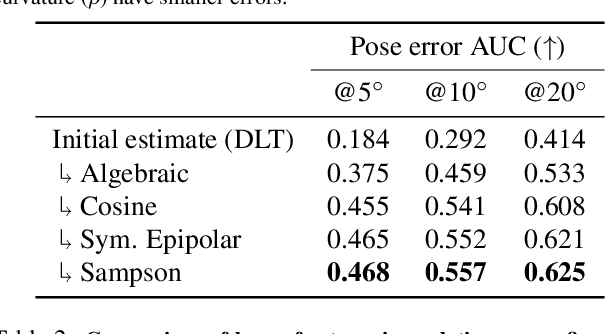
Many problems in computer vision can be formulated as geometric estimation problems, i.e. given a collection of measurements (e.g. point correspondences) we wish to fit a model (e.g. an essential matrix) that agrees with our observations. This necessitates some measure of how much an observation ``agrees" with a given model. A natural choice is to consider the smallest perturbation that makes the observation exactly satisfy the constraints. However, for many problems, this metric is expensive or otherwise intractable to compute. The so-called Sampson error approximates this geometric error through a linearization scheme. For epipolar geometry, the Sampson error is a popular choice and in practice known to yield very tight approximations of the corresponding geometric residual (the reprojection error). In this paper we revisit the Sampson approximation and provide new theoretical insights as to why and when this approximation works, as well as provide explicit bounds on the tightness under some mild assumptions. Our theoretical results are validated in several experiments on real data and in the context of different geometric estimation tasks.
Consensus-Adaptive RANSAC
Jul 26, 2023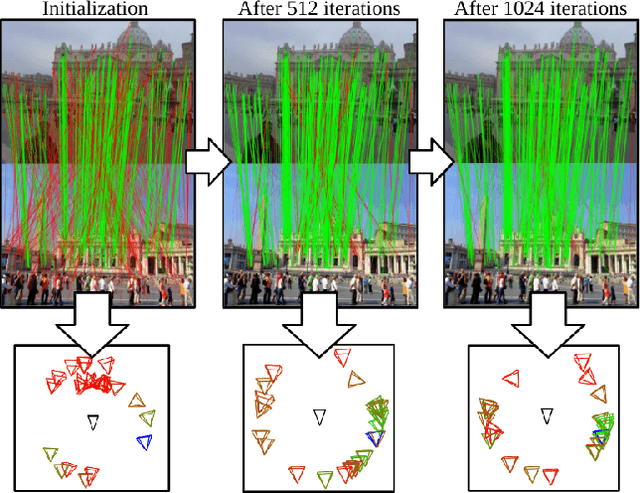
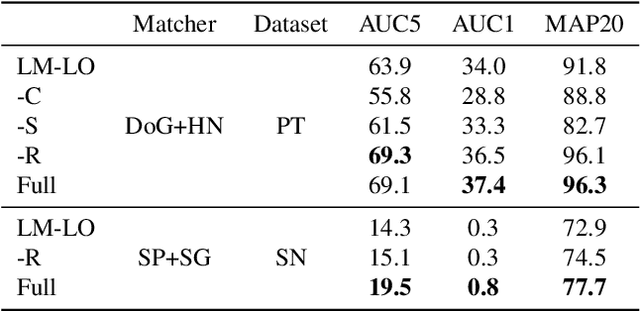
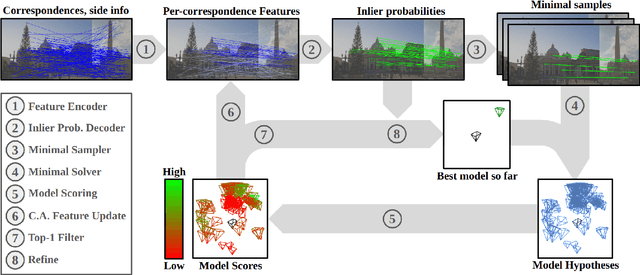
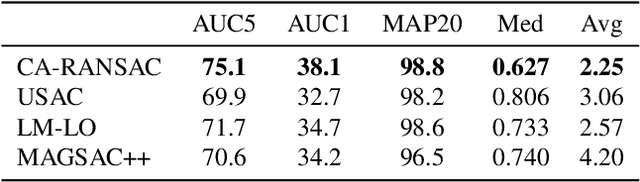
RANSAC and its variants are widely used for robust estimation, however, they commonly follow a greedy approach to finding the highest scoring model while ignoring other model hypotheses. In contrast, Iteratively Reweighted Least Squares (IRLS) techniques gradually approach the model by iteratively updating the weight of each correspondence based on the residuals from previous iterations. Inspired by these methods, we propose a new RANSAC framework that learns to explore the parameter space by considering the residuals seen so far via a novel attention layer. The attention mechanism operates on a batch of point-to-model residuals, and updates a per-point estimation state to take into account the consensus found through a lightweight one-step transformer. This rich state then guides the minimal sampling between iterations as well as the model refinement. We evaluate the proposed approach on essential and fundamental matrix estimation on a number of indoor and outdoor datasets. It outperforms state-of-the-art estimators by a significant margin adding only a small runtime overhead. Moreover, we demonstrate good generalization properties of our trained model, indicating its effectiveness across different datasets and tasks. The proposed attention mechanism and one-step transformer provide an adaptive behavior that enhances the performance of RANSAC, making it a more effective tool for robust estimation. Code is available at https://github.com/cavalli1234/CA-RANSAC.