 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing the RANSAC Stopping Criterion
Paper and Code
Mar 10, 2025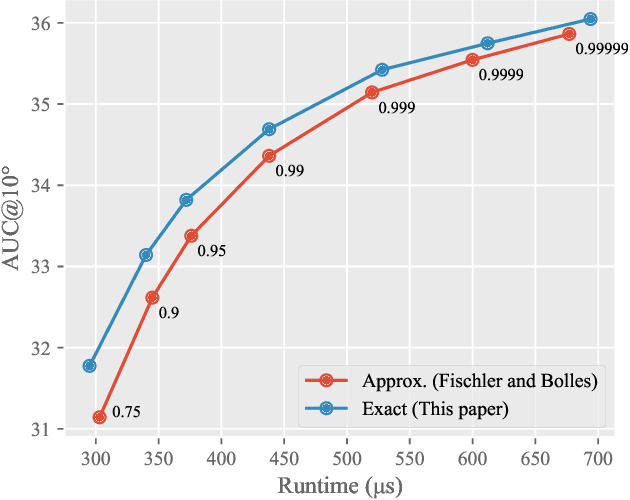

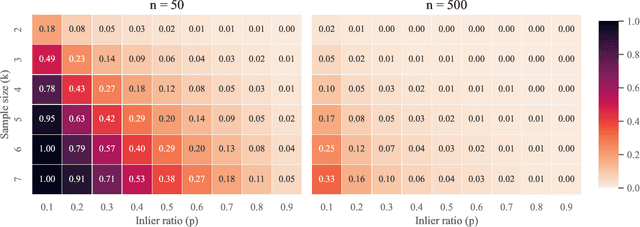

For several decades, RANSAC has been one of the most commonly used robust estimation algorithms for many problems in computer vision and related fields. The main contribution of this paper lies in addressing a long-standing error baked into virtually any system building upon the RANSAC algorithm. Since its inception in 1981 by Fischler and Bolles, many variants of RANSAC have been proposed on top of the same original idea relying on the fact that random sampling has a high likelihood of generating a good hypothesis from minimal subsets of measurements. An approximation to the sampling probability was originally derived by the paper in 1981 in support of adaptively stopping RANSAC and is, as such, used in the vast majority of today's RANSAC variants and implementations. The impact of this approximation has since not been questioned or thoroughly studied by any of the later works. As we theoretically derive and practically demonstrate in this paper, the approximation leads to severe undersampling and thus failure to find good models. The discrepancy is especially pronounced in challenging scenarios with few inliers and high model complexity. An implementation of computing the exact probability is surprisingly simple yet highly effective and has potentially drastic impact across a large range of computer vision systems.