 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing the RANSAC Stopping Criterion
Mar 10, 2025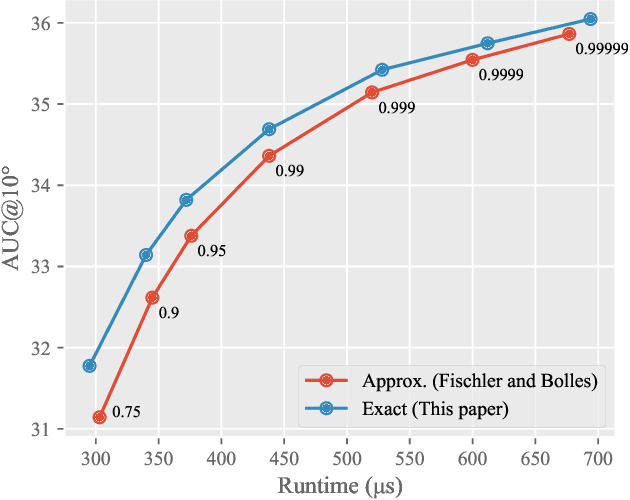

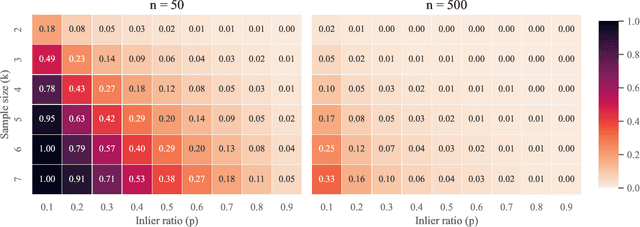

For several decades, RANSAC has been one of the most commonly used robust estimation algorithms for many problems in computer vision and related fields. The main contribution of this paper lies in addressing a long-standing error baked into virtually any system building upon the RANSAC algorithm. Since its inception in 1981 by Fischler and Bolles, many variants of RANSAC have been proposed on top of the same original idea relying on the fact that random sampling has a high likelihood of generating a good hypothesis from minimal subsets of measurements. An approximation to the sampling probability was originally derived by the paper in 1981 in support of adaptively stopping RANSAC and is, as such, used in the vast majority of today's RANSAC variants and implementations. The impact of this approximation has since not been questioned or thoroughly studied by any of the later works. As we theoretically derive and practically demonstrate in this paper, the approximation leads to severe undersampling and thus failure to find good models. The discrepancy is especially pronounced in challenging scenarios with few inliers and high model complexity. An implementation of computing the exact probability is surprisingly simple yet highly effective and has potentially drastic impact across a large range of computer vision systems.
Panoptic Multi-TSDFs: a Flexible Representation for Online Multi-resolution Volumetric Mapping and Long-term Dynamic Scene Consistency
Sep 21, 2021

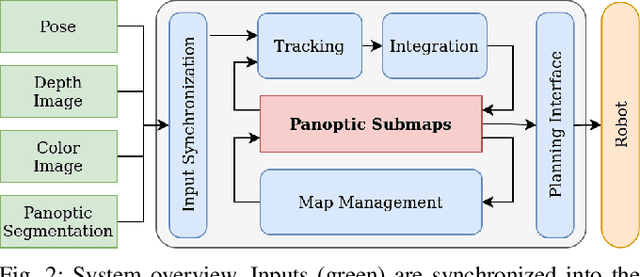
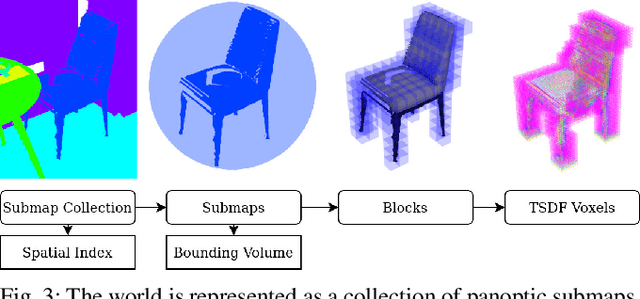
For robotic interaction in an environment shared with multiple agents, accessing a volumetric and semantic map of the scene is crucial. However, such environments are inevitably subject to long-term changes, which the map representation needs to account for.To this end, we propose panoptic multi-TSDFs, a novel representation for multi-resolution volumetric mapping over long periods of time. By leveraging high-level information for 3D reconstruction, our proposed system allocates high resolution only where needed. In addition, through reasoning on the object level, semantic consistency over time is achieved. This enables to maintain up-to-date reconstructions with high accuracy while improving coverage by incorporating and fusing previous data. We show in thorough experimental validations that our map representation can be efficiently constructed, maintained, and queried during online operation, and that the presented approach can operate robustly on real depth sensors using non-optimized panoptic segmentation as input.
RoutedFusion: Learning Real-time Depth Map Fusion
Jan 13, 2020


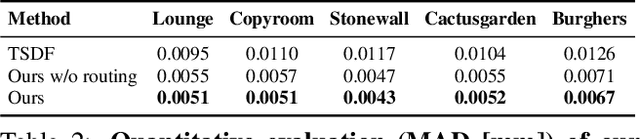
The efficient fusion of depth maps is a key part of most state-of-the-art 3D reconstruction methods. Besides requiring high accuracy, these depth fusion methods need to be scalable and real-time capable. To this end, we present a novel real-time capable machine learning-based method for depth map fusion. Similar to the seminal depth map fusion approach by Curless and Levoy, we only update a local group of voxels to ensure real-time capability. Instead of a simple linear fusion of depth information, we propose a neural network that predicts non-linear updates to better account for typical fusion errors. Our network is composed of a 2D depth routing network and a 3D depth fusion network which efficiently handle sensor-specific noise and outliers. This is especially useful for surface edges and thin objects for which the original approach suffers from thickening artifacts. Our method outperforms the traditional fusion approach and related learned approaches on both synthetic and real data. We demonstrate the performance of our method in reconstructing fine geometric details from noise and outlier contaminated data on various scenes