 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemaplab 2.0 -- A Modular and Multi-Modal Mapping Framework
Dec 01, 2022Integration of multiple sensor modalities and deep learning into Simultaneous Localization And Mapping (SLAM) systems are areas of significant interest in current research. Multi-modality is a stepping stone towards achieving robustness in challenging environments and interoperability of heterogeneous multi-robot systems with varying sensor setups. With maplab 2.0, we provide a versatile open-source platform that facilitates developing, testing, and integrating new modules and features into a fully-fledged SLAM system. Through extensive experiments, we show that maplab 2.0's accuracy is comparable to the state-of-the-art on the HILTI 2021 benchmark. Additionally, we showcase the flexibility of our system with three use cases: i) large-scale (approx. 10 km) multi-robot multi-session (23 missions) mapping, ii) integration of non-visual landmarks, and iii) incorporating a semantic object-based loop closure module into the mapping framework. The code is available open-source at https://github.com/ethz-asl/maplab.
Spatial Computing and Intuitive Interaction: Bringing Mixed Reality and Robotics Together
Feb 03, 2022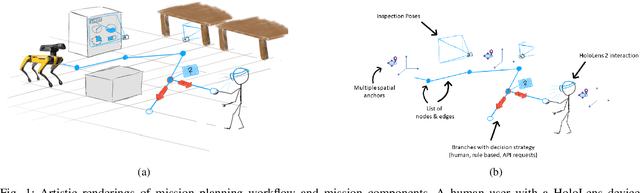

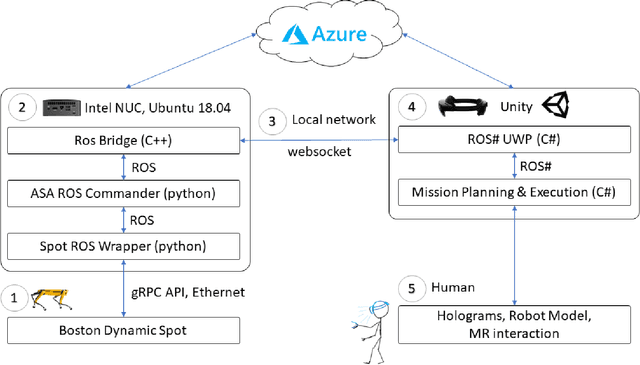

Spatial computing -- the ability of devices to be aware of their surroundings and to represent this digitally -- offers novel capabilities in human-robot interaction. In particular, the combination of spatial computing and egocentric sensing on mixed reality devices enables them to capture and understand human actions and translate these to actions with spatial meaning, which offers exciting new possibilities for collaboration between humans and robots. This paper presents several human-robot systems that utilize these capabilities to enable novel robot use cases: mission planning for inspection, gesture-based control, and immersive teleoperation. These works demonstrate the power of mixed reality as a tool for human-robot interaction, and the potential of spatial computing and mixed reality to drive the future of human-robot interaction.
CERBERUS: Autonomous Legged and Aerial Robotic Exploration in the Tunnel and Urban Circuits of the DARPA Subterranean Challenge
Jan 18, 2022

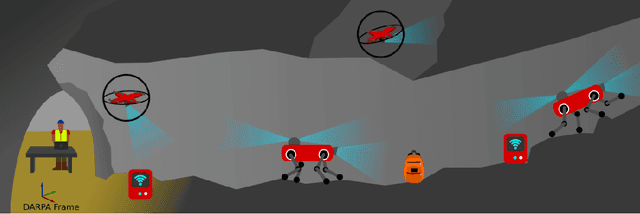

Autonomous exploration of subterranean environments constitutes a major frontier for robotic systems as underground settings present key challenges that can render robot autonomy hard to achieve. This has motivated the DARPA Subterranean Challenge, where teams of robots search for objects of interest in various underground environments. In response, the CERBERUS system-of-systems is presented as a unified strategy towards subterranean exploration using legged and flying robots. As primary robots, ANYmal quadruped systems are deployed considering their endurance and potential to traverse challenging terrain. For aerial robots, both conventional and collision-tolerant multirotors are utilized to explore spaces too narrow or otherwise unreachable by ground systems. Anticipating degraded sensing conditions, a complementary multi-modal sensor fusion approach utilizing camera, LiDAR, and inertial data for resilient robot pose estimation is proposed. Individual robot pose estimates are refined by a centralized multi-robot map optimization approach to improve the reported location accuracy of detected objects of interest in the DARPA-defined coordinate frame. Furthermore, a unified exploration path planning policy is presented to facilitate the autonomous operation of both legged and aerial robots in complex underground networks. Finally, to enable communication between the robots and the base station, CERBERUS utilizes a ground rover with a high-gain antenna and an optical fiber connection to the base station, alongside breadcrumbing of wireless nodes by our legged robots. We report results from the CERBERUS system-of-systems deployment at the DARPA Subterranean Challenge Tunnel and Urban Circuits, along with the current limitations and the lessons learned for the benefit of the community.
Panoptic Multi-TSDFs: a Flexible Representation for Online Multi-resolution Volumetric Mapping and Long-term Dynamic Scene Consistency
Sep 21, 2021

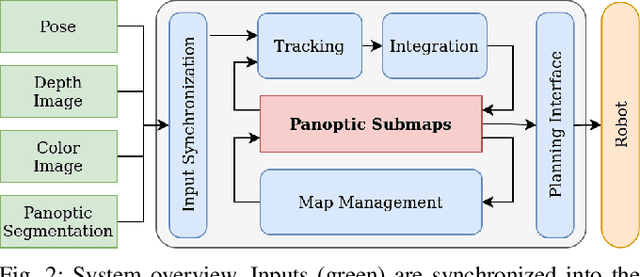
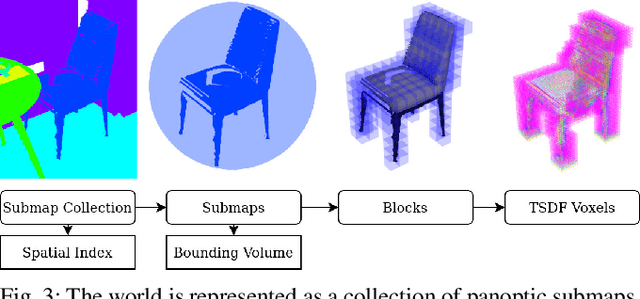
For robotic interaction in an environment shared with multiple agents, accessing a volumetric and semantic map of the scene is crucial. However, such environments are inevitably subject to long-term changes, which the map representation needs to account for.To this end, we propose panoptic multi-TSDFs, a novel representation for multi-resolution volumetric mapping over long periods of time. By leveraging high-level information for 3D reconstruction, our proposed system allocates high resolution only where needed. In addition, through reasoning on the object level, semantic consistency over time is achieved. This enables to maintain up-to-date reconstructions with high accuracy while improving coverage by incorporating and fusing previous data. We show in thorough experimental validations that our map representation can be efficiently constructed, maintained, and queried during online operation, and that the presented approach can operate robustly on real depth sensors using non-optimized panoptic segmentation as input.
Superquadric Object Representation for Optimization-based Semantic SLAM
Sep 20, 2021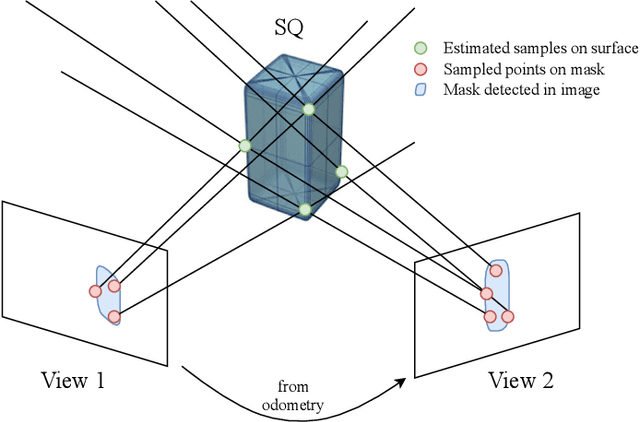
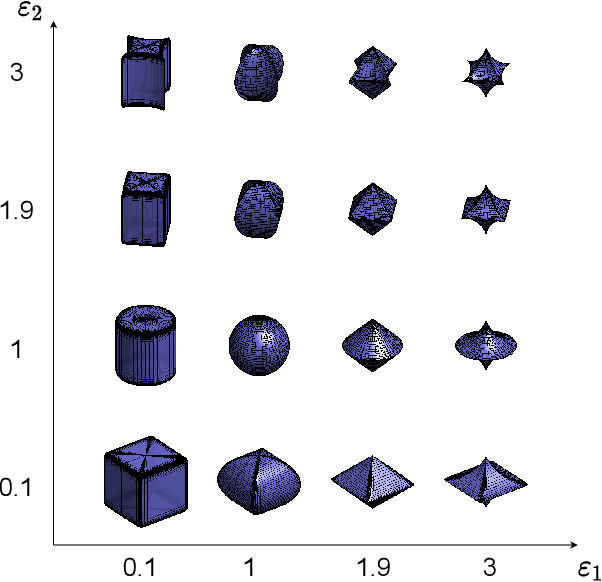
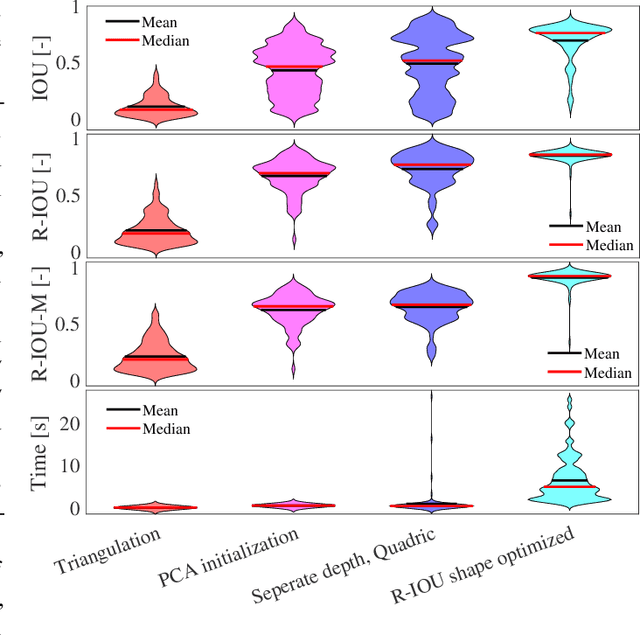
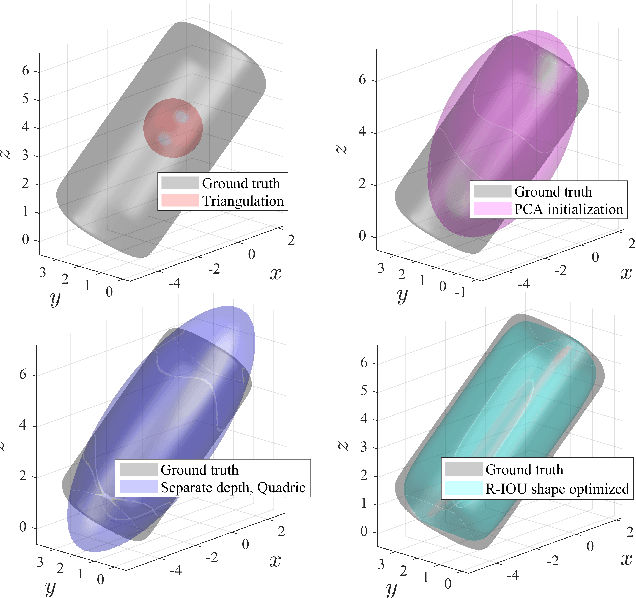
Introducing semantically meaningful objects to visual Simultaneous Localization And Mapping (SLAM) has the potential to improve both the accuracy and reliability of pose estimates, especially in challenging scenarios with significant view-point and appearance changes. However, how semantic objects should be represented for an efficient inclusion in optimization-based SLAM frameworks is still an open question. Superquadrics(SQs) are an efficient and compact object representation, able to represent most common object types to a high degree, and typically retrieved from 3D point-cloud data. However, accurate 3D point-cloud data might not be available in all applications. Recent advancements in machine learning enabled robust object recognition and semantic mask measurements from camera images under many different appearance conditions. We propose a pipeline to leverage such semantic mask measurements to fit SQ parameters to multi-view camera observations using a multi-stage initialization and optimization procedure. We demonstrate the system's ability to retrieve randomly generated SQ parameters from multi-view mask observations in preliminary simulation experiments and evaluate different initialization stages and cost functions.
SemSegMap- 3D Segment-Based Semantic Localization
Jul 30, 2021
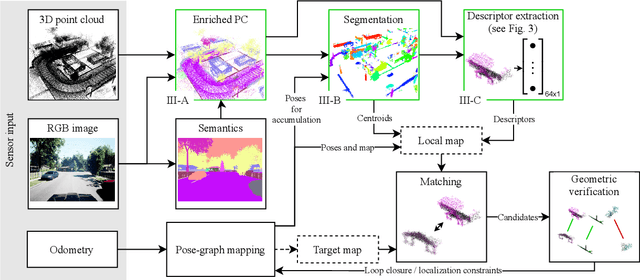
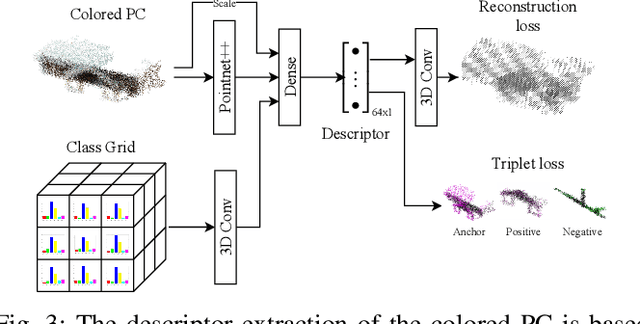
Localization is an essential task for mobile autonomous robotic systems that want to use pre-existing maps or create new ones in the context of SLAM. Today, many robotic platforms are equipped with high-accuracy 3D LiDAR sensors, which allow a geometric mapping, and cameras able to provide semantic cues of the environment. Segment-based mapping and localization have been applied with great success to 3D point-cloud data, while semantic understanding has been shown to improve localization performance in vision based systems. In this paper we combine both modalities in SemSegMap, extending SegMap into a segment based mapping framework able to also leverage color and semantic data from the environment to improve localization accuracy and robustness. In particular, we present new segmentation and descriptor extraction processes. The segmentation process benefits from additional distance information from color and semantic class consistency resulting in more repeatable segments and more overlap after re-visiting a place. For the descriptor, a tight fusion approach in a deep-learned descriptor extraction network is performed leading to a higher descriptiveness for landmark matching. We demonstrate the advantages of this fusion on multiple simulated and real-world datasets and compare its performance to various baselines. We show that we are able to find 50.9% more high-accuracy prior-less global localizations compared to SegMap on challenging datasets using very compact maps while also providing accurate full 6 DoF pose estimates in real-time.
TSDF++: A Multi-Object Formulation for Dynamic Object Tracking and Reconstruction
May 16, 2021
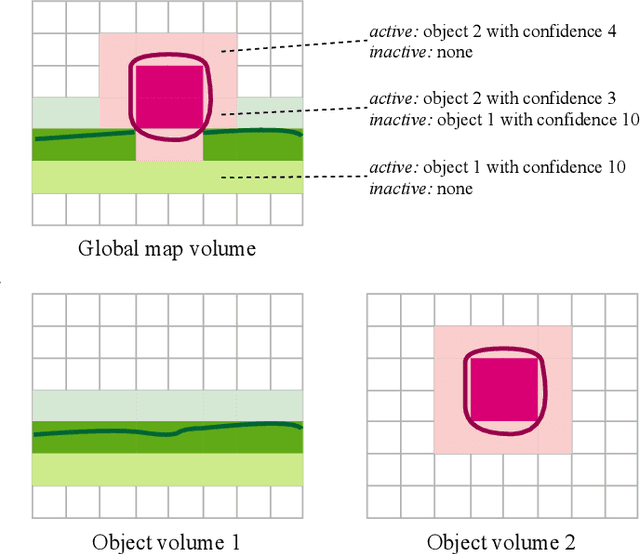

The ability to simultaneously track and reconstruct multiple objects moving in the scene is of the utmost importance for robotic tasks such as autonomous navigation and interaction. Virtually all of the previous attempts to map multiple dynamic objects have evolved to store individual objects in separate reconstruction volumes and track the relative pose between them. While simple and intuitive, such formulation does not scale well with respect to the number of objects in the scene and introduces the need for an explicit occlusion handling strategy. In contrast, we propose a map representation that allows maintaining a single volume for the entire scene and all the objects therein. To this end, we introduce a novel multi-object TSDF formulation that can encode multiple object surfaces at any given location in the map. In a multiple dynamic object tracking and reconstruction scenario, our representation allows maintaining accurate reconstruction of surfaces even while they become temporarily occluded by other objects moving in their proximity. We evaluate the proposed TSDF++ formulation on a public synthetic dataset and demonstrate its ability to preserve reconstructions of occluded surfaces when compared to the standard TSDF map representation.
Crowd against the machine: A simulation-based benchmark tool to evaluate and compare robot capabilities to navigate a human crowd
Apr 29, 2021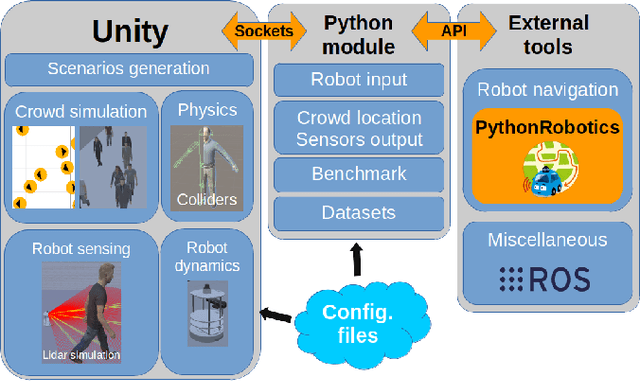
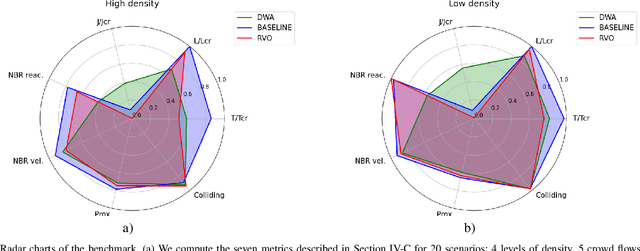
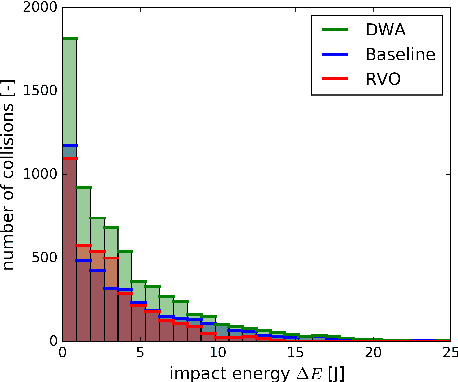
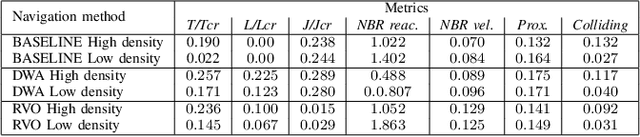
The evaluation of robot capabilities to navigate human crowds is essential to conceive new robots intended to operate in public spaces. This paper initiates the development of a benchmark tool to evaluate such capabilities; our long term vision is to provide the community with a simulation tool that generates virtual crowded environment to test robots, to establish standard scenarios and metrics to evaluate navigation techniques in terms of safety and efficiency, and thus, to install new methods to benchmarking robots' crowd navigation capabilities. This paper presents the architecture of the simulation tools, introduces first scenarios and evaluation metrics, as well as early results to demonstrate that our solution is relevant to be used as a benchmark tool.
Spherical Multi-Modal Place Recognition for Heterogeneous Sensor Systems
Apr 17, 2021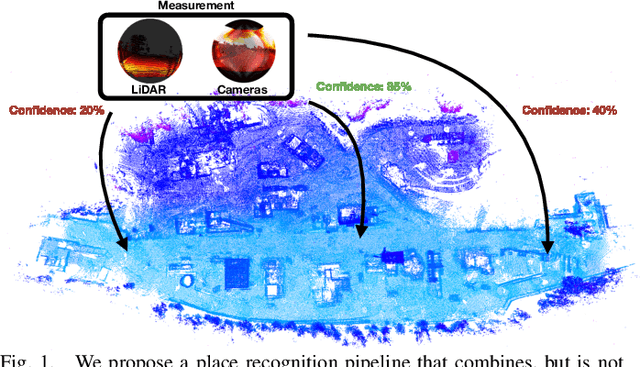
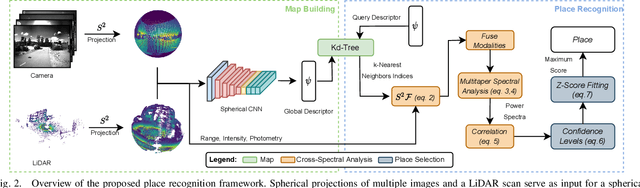
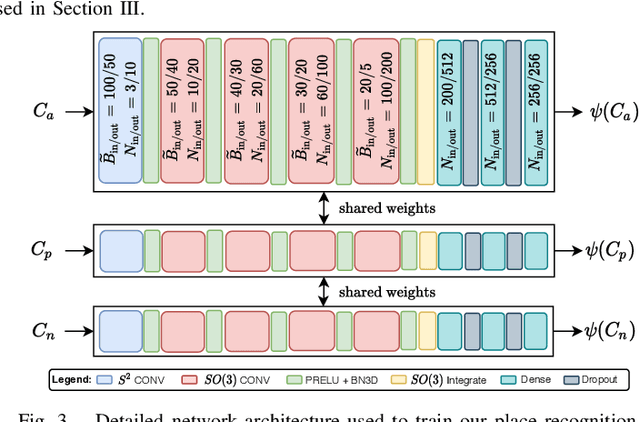
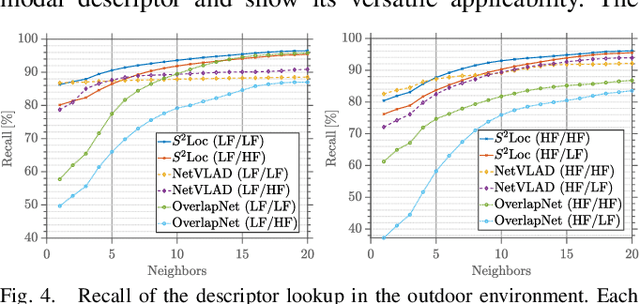
In this paper, we propose a robust end-to-end multi-modal pipeline for place recognition where the sensor systems can differ from the map building to the query. Our approach operates directly on images and LiDAR scans without requiring any local feature extraction modules. By projecting the sensor data onto the unit sphere, we learn a multi-modal descriptor of partially overlapping scenes using a spherical convolutional neural network. The employed spherical projection model enables the support of arbitrary LiDAR and camera systems readily without losing information. Loop closure candidates are found using a nearest-neighbor lookup in the embedding space. We tackle the problem of correctly identifying the closest place by correlating the candidates' power spectra, obtaining a confidence value per prospect. Our estimate for the correct place corresponds then to the candidate with the highest confidence. We evaluate our proposal w.r.t. state-of-the-art approaches in place recognition using real-world data acquired using different sensors. Our approach can achieve a recall that is up to 10% and 5% higher than for a LiDAR- and vision-based system, respectively, when the sensor setup differs between model training and deployment. Additionally, our place selection can correctly identify up to 95% matches from the candidate set.
Mesh Manifold based Riemannian Motion Planning for Omnidirectional Micro Aerial Vehicles
Feb 20, 2021
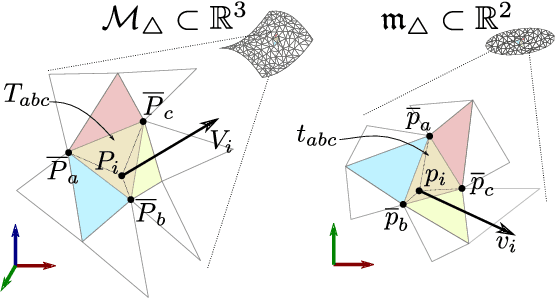

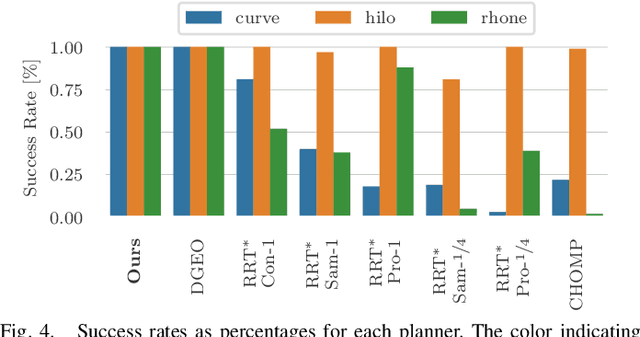
This paper presents a novel on-line path planning method that enables aerial robots to interact with surfaces. We present a solution to the problem of finding trajectories that drive a robot towards a surface and move along it. Triangular meshes are used as a surface map representation that is free of fixed discretization and allows for very large workspaces. We propose to leverage planar parametrization methods to obtain a lower-dimensional topologically equivalent representation of the original surface. Furthermore, we interpret the original surface and its lower-dimensional representation as manifold approximations that allow the use of Riemannian Motion Policies (RMPs), resulting in an efficient, versatile, and elegant motion generation framework. We compare against several Rapidly-exploring Random Tree (RRT) planners, a customized CHOMP variant, and the discrete geodesic algorithm. Using extensive simulations on real-world data we show that the proposed planner can reliably plan high-quality near-optimal trajectories at minimal computational cost. The accompanying multimedia attachment demonstrates feasibility on a real OMAV. The obtained paths show less than 10% deviation from the theoretical optimum while facilitating reactive re-planning at kHz refresh rates, enabling flying robots to perform motion planning for interaction with complex surfaces.