 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperquadric Object Representation for Optimization-based Semantic SLAM
Paper and Code
Sep 20, 2021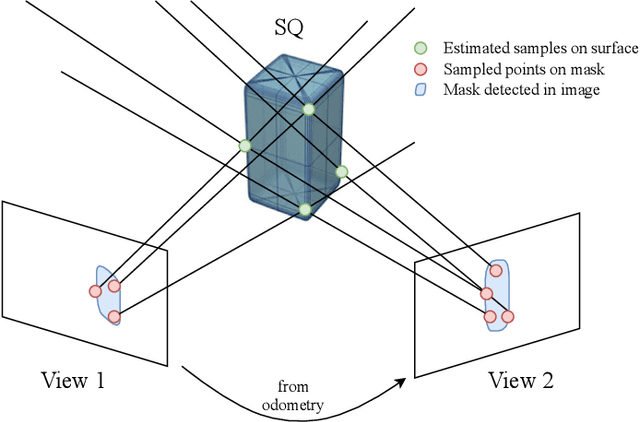
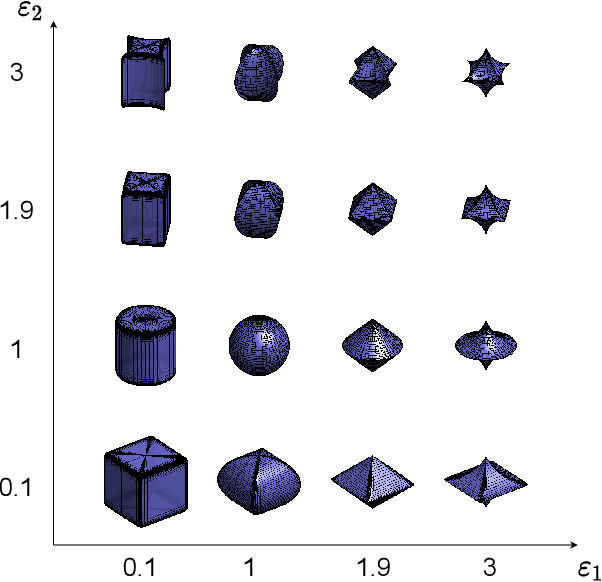
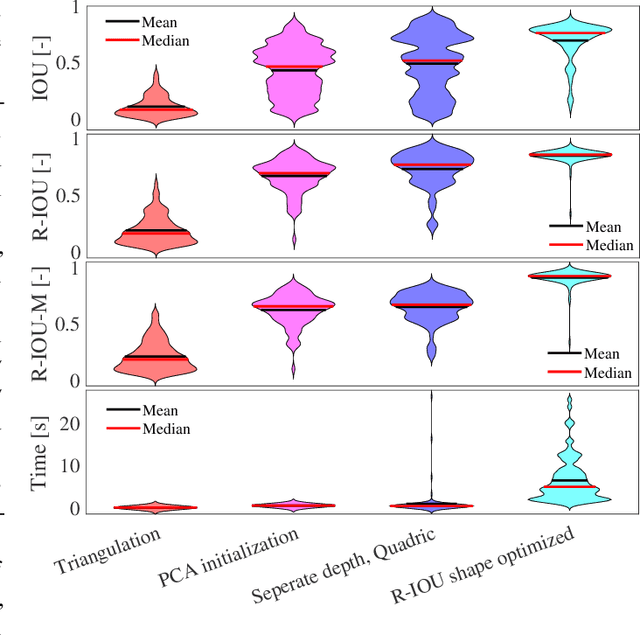
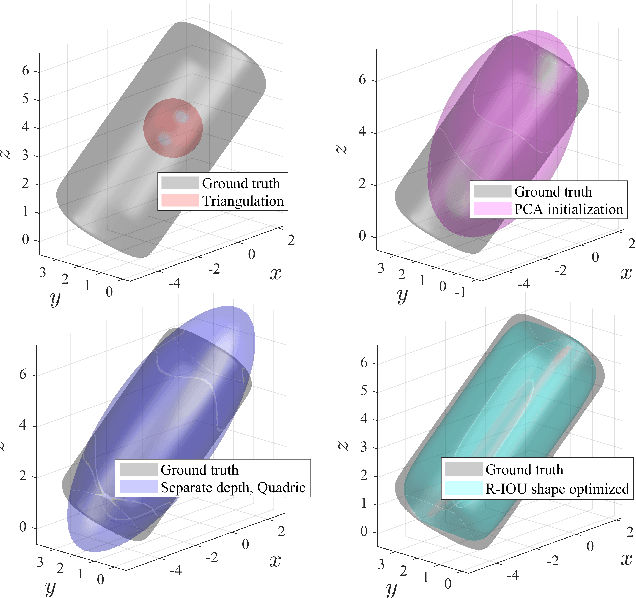
Introducing semantically meaningful objects to visual Simultaneous Localization And Mapping (SLAM) has the potential to improve both the accuracy and reliability of pose estimates, especially in challenging scenarios with significant view-point and appearance changes. However, how semantic objects should be represented for an efficient inclusion in optimization-based SLAM frameworks is still an open question. Superquadrics(SQs) are an efficient and compact object representation, able to represent most common object types to a high degree, and typically retrieved from 3D point-cloud data. However, accurate 3D point-cloud data might not be available in all applications. Recent advancements in machine learning enabled robust object recognition and semantic mask measurements from camera images under many different appearance conditions. We propose a pipeline to leverage such semantic mask measurements to fit SQ parameters to multi-view camera observations using a multi-stage initialization and optimization procedure. We demonstrate the system's ability to retrieve randomly generated SQ parameters from multi-view mask observations in preliminary simulation experiments and evaluate different initialization stages and cost functions.