 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIRUS-NeRF -- Vision, InfraRed and UltraSonic based Neural Radiance Fields
Mar 14, 2024Autonomous mobile robots are an increasingly integral part of modern factory and warehouse operations. Obstacle detection, avoidance and path planning are critical safety-relevant tasks, which are often solved using expensive LiDAR sensors and depth cameras. We propose to use cost-effective low-resolution ranging sensors, such as ultrasonic and infrared time-of-flight sensors by developing VIRUS-NeRF - Vision, InfraRed, and UltraSonic based Neural Radiance Fields. Building upon Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (Instant-NGP), VIRUS-NeRF incorporates depth measurements from ultrasonic and infrared sensors and utilizes them to update the occupancy grid used for ray marching. Experimental evaluation in 2D demonstrates that VIRUS-NeRF achieves comparable mapping performance to LiDAR point clouds regarding coverage. Notably, in small environments, its accuracy aligns with that of LiDAR measurements, while in larger ones, it is bounded by the utilized ultrasonic sensors. An in-depth ablation study reveals that adding ultrasonic and infrared sensors is highly effective when dealing with sparse data and low view variation. Further, the proposed occupancy grid of VIRUS-NeRF improves the mapping capabilities and increases the training speed by 46% compared to Instant-NGP. Overall, VIRUS-NeRF presents a promising approach for cost-effective local mapping in mobile robotics, with potential applications in safety and navigation tasks. The code can be found at https://github.com/ethz-asl/virus nerf.
Path-Constrained State Estimation for Rail Vehicles
Aug 23, 2023Globally rising demand for transportation by rail is pushing existing infrastructure to its capacity limits, necessitating the development of accurate, robust, and high-frequency positioning systems to ensure safe and efficient train operation. As individual sensor modalities cannot satisfy the strict requirements of robustness and safety, a combination thereof is required. We propose a path-constrained sensor fusion framework to integrate various modalities while leveraging the unique characteristics of the railway network. To reflect the constrained motion of rail vehicles along their tracks, the state is modeled in 1D along the track geometry. We further leverage the limited action space of a train by employing a novel multi-hypothesis tracking to account for multiple possible trajectories a vehicle can take through the railway network. We demonstrate the reliability and accuracy of our fusion framework on multiple tram datasets recorded in the city of Zurich, utilizing Visual-Inertial Odometry for local motion estimation and a standard GNSS for global localization. We evaluate our results using ground truth localizations recorded with a RTK-GNSS, and compare our method to standard baselines. A Root Mean Square Error of 4.78 m and a track selectivity score of up to 94.9 % have been achieved.
maplab 2.0 -- A Modular and Multi-Modal Mapping Framework
Dec 01, 2022Integration of multiple sensor modalities and deep learning into Simultaneous Localization And Mapping (SLAM) systems are areas of significant interest in current research. Multi-modality is a stepping stone towards achieving robustness in challenging environments and interoperability of heterogeneous multi-robot systems with varying sensor setups. With maplab 2.0, we provide a versatile open-source platform that facilitates developing, testing, and integrating new modules and features into a fully-fledged SLAM system. Through extensive experiments, we show that maplab 2.0's accuracy is comparable to the state-of-the-art on the HILTI 2021 benchmark. Additionally, we showcase the flexibility of our system with three use cases: i) large-scale (approx. 10 km) multi-robot multi-session (23 missions) mapping, ii) integration of non-visual landmarks, and iii) incorporating a semantic object-based loop closure module into the mapping framework. The code is available open-source at https://github.com/ethz-asl/maplab.
Descriptellation: Deep Learned Constellation Descriptors for SLAM
Mar 01, 2022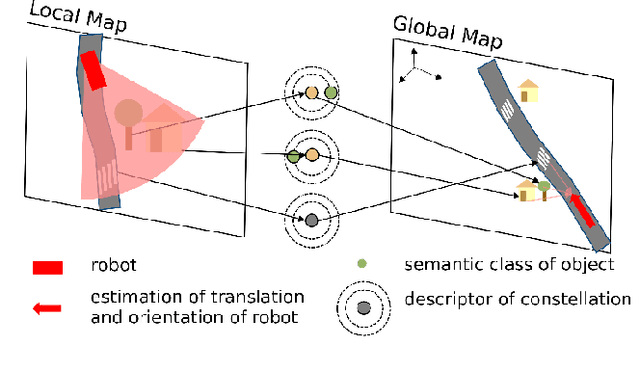
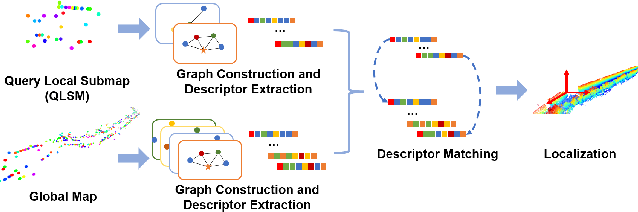
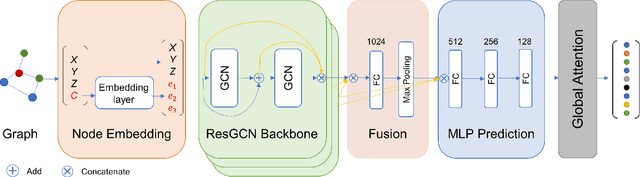
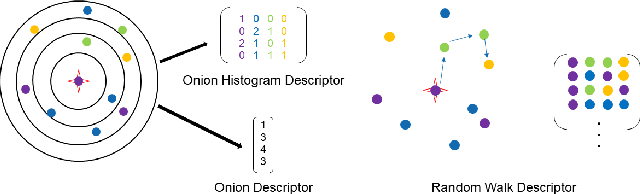
Current global localization descriptors in Simultaneous Localization and Mapping (SLAM) often fail under vast viewpoint or appearance changes. Adding topological information of semantic objects into the descriptors ameliorates the problem. However, hand-crafted topological descriptors extract limited information and they are not robust to environmental noise, drastic perspective changes, or object occlusion or misdetections. To solve this problem, we formulate a learning-based approach by constructing constellations from semantically meaningful objects and use Deep Graph Convolution Networks to map the constellation representation to a descriptor. We demonstrate the effectiveness of our Deep Learned Constellation Descriptor (Descriptellation) on the Paris-Rue-Lille and IQmulus datasets. Although Descriptellation is trained on randomly generated simulation datasets, it shows good generalization abilities on real-world datasets. Descriptellation outperforms the PointNet and handcrafted constellation descriptors for global localization, and shows robustness against different types of noise.
Unified Data Collection for Visual-Inertial Calibration via Deep Reinforcement Learning
Sep 30, 2021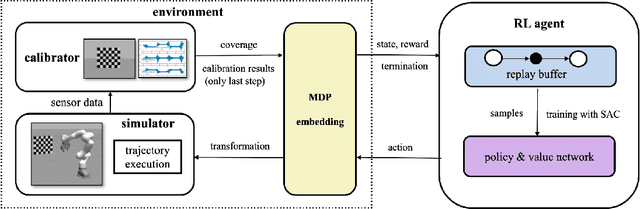
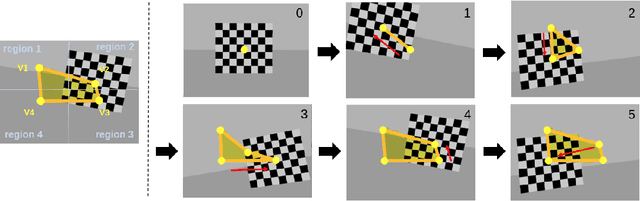

Visual-inertial sensors have a wide range of applications in robotics. However, good performance often requires different sophisticated motion routines to accurately calibrate camera intrinsics and inter-sensor extrinsics. This work presents a novel formulation to learn a motion policy to be executed on a robot arm for automatic data collection for calibrating intrinsics and extrinsics jointly. Our approach models the calibration process compactly using model-free deep reinforcement learning to derive a policy that guides the motions of a robotic arm holding the sensor to efficiently collect measurements that can be used for both camera intrinsic calibration and camera-IMU extrinsic calibration. Given the current pose and collected measurements, the learned policy generates the subsequent transformation that optimizes sensor calibration accuracy. The evaluations in simulation and on a real robotic system show that our learned policy generates favorable motion trajectories and collects enough measurements efficiently that yield the desired intrinsics and extrinsics with short path lengths. In simulation we are able to perform calibrations 10 times faster than hand-crafted policies, which transfers to a real-world speed up of 3 times over a human expert.
Superquadric Object Representation for Optimization-based Semantic SLAM
Sep 20, 2021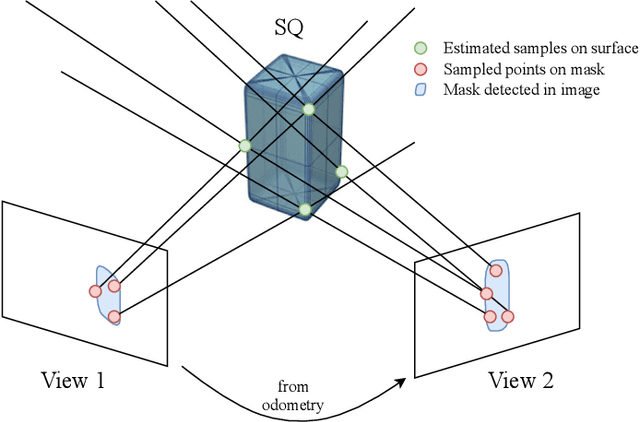
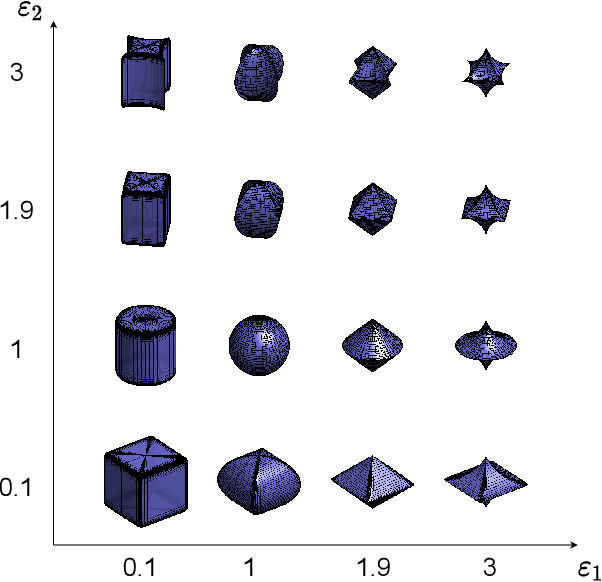
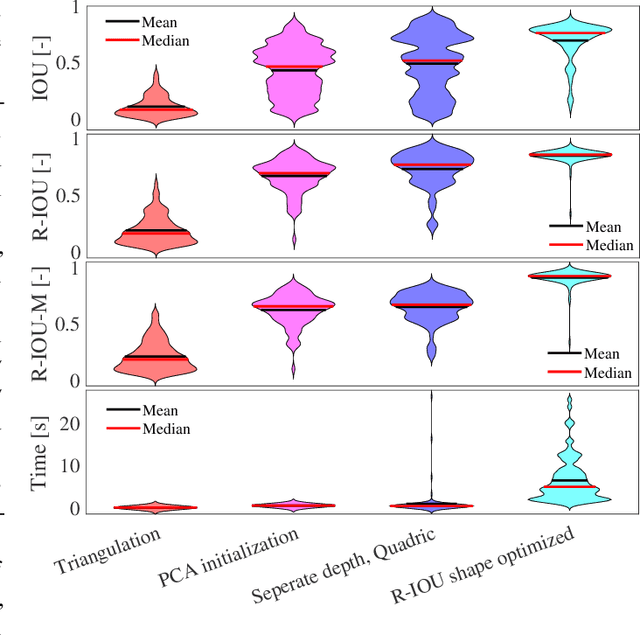
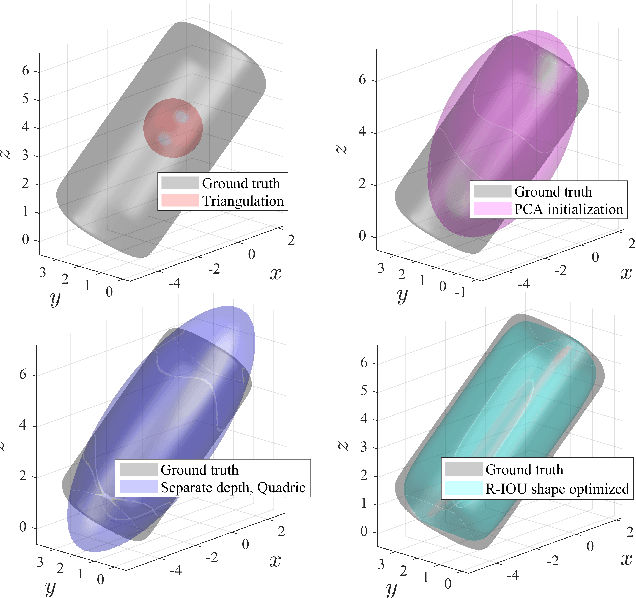
Introducing semantically meaningful objects to visual Simultaneous Localization And Mapping (SLAM) has the potential to improve both the accuracy and reliability of pose estimates, especially in challenging scenarios with significant view-point and appearance changes. However, how semantic objects should be represented for an efficient inclusion in optimization-based SLAM frameworks is still an open question. Superquadrics(SQs) are an efficient and compact object representation, able to represent most common object types to a high degree, and typically retrieved from 3D point-cloud data. However, accurate 3D point-cloud data might not be available in all applications. Recent advancements in machine learning enabled robust object recognition and semantic mask measurements from camera images under many different appearance conditions. We propose a pipeline to leverage such semantic mask measurements to fit SQ parameters to multi-view camera observations using a multi-stage initialization and optimization procedure. We demonstrate the system's ability to retrieve randomly generated SQ parameters from multi-view mask observations in preliminary simulation experiments and evaluate different initialization stages and cost functions.
SemSegMap- 3D Segment-Based Semantic Localization
Jul 30, 2021
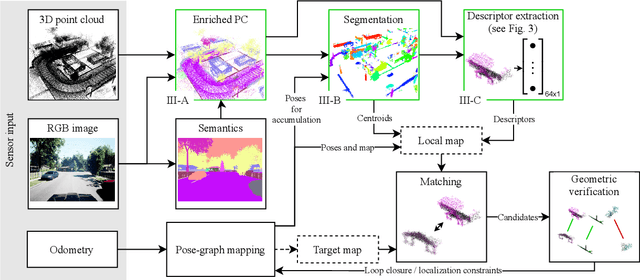
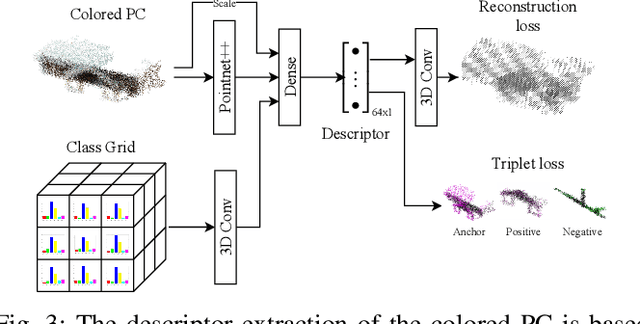
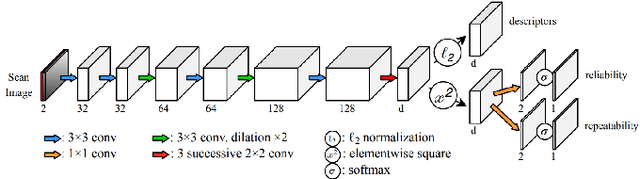
Localization is an essential task for mobile autonomous robotic systems that want to use pre-existing maps or create new ones in the context of SLAM. Today, many robotic platforms are equipped with high-accuracy 3D LiDAR sensors, which allow a geometric mapping, and cameras able to provide semantic cues of the environment. Segment-based mapping and localization have been applied with great success to 3D point-cloud data, while semantic understanding has been shown to improve localization performance in vision based systems. In this paper we combine both modalities in SemSegMap, extending SegMap into a segment based mapping framework able to also leverage color and semantic data from the environment to improve localization accuracy and robustness. In particular, we present new segmentation and descriptor extraction processes. The segmentation process benefits from additional distance information from color and semantic class consistency resulting in more repeatable segments and more overlap after re-visiting a place. For the descriptor, a tight fusion approach in a deep-learned descriptor extraction network is performed leading to a higher descriptiveness for landmark matching. We demonstrate the advantages of this fusion on multiple simulated and real-world datasets and compare its performance to various baselines. We show that we are able to find 50.9% more high-accuracy prior-less global localizations compared to SegMap on challenging datasets using very compact maps while also providing accurate full 6 DoF pose estimates in real-time.
3D3L: Deep Learned 3D Keypoint Detection and Description for LiDARs
Apr 12, 2021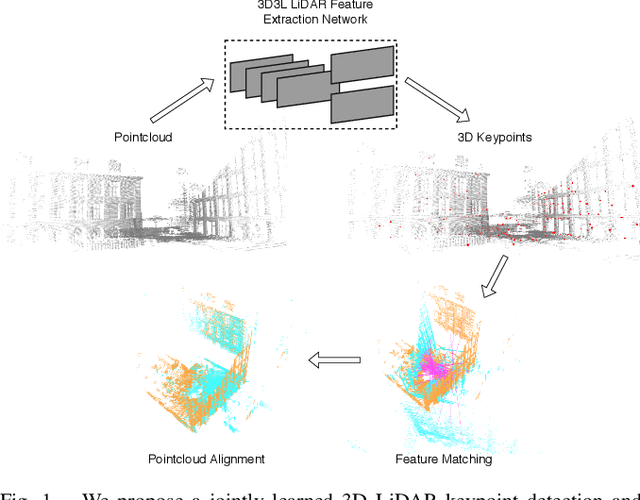
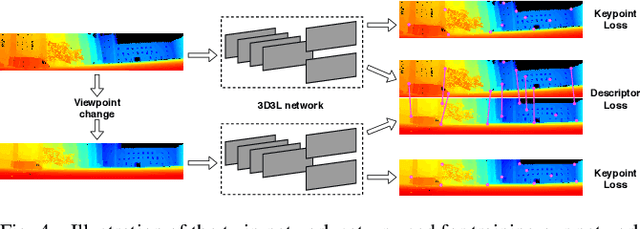

With the advent of powerful, light-weight 3D LiDARs, they have become the hearth of many navigation and SLAM algorithms on various autonomous systems. Pointcloud registration methods working with unstructured pointclouds such as ICP are often computationally expensive or require a good initial guess. Furthermore, 3D feature-based registration methods have never quite reached the robustness of 2D methods in visual SLAM. With the continuously increasing resolution of LiDAR range images, these 2D methods not only become applicable but should exploit the illumination-independent modalities that come with it, such as depth and intensity. In visual SLAM, deep learned 2D features and descriptors perform exceptionally well compared to traditional methods. In this publication, we use a state-of-the-art 2D feature network as a basis for 3D3L, exploiting both intensity and depth of LiDAR range images to extract powerful 3D features. Our results show that these keypoints and descriptors extracted from LiDAR scan images outperform state-of-the-art on different benchmark metrics and allow for robust scan-to-scan alignment as well as global localization.
CalQNet -- Detection of Calibration Quality for Life-Long Stereo Camera Setups
Apr 10, 2021
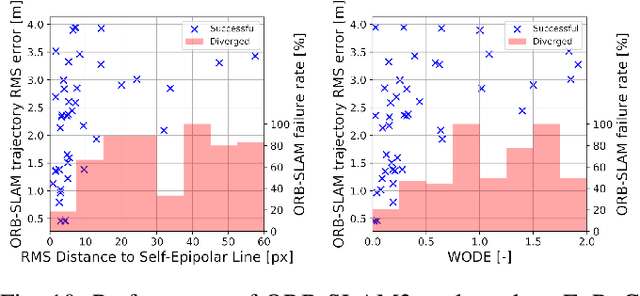

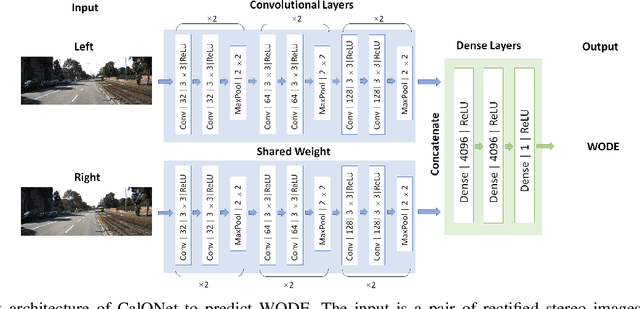
Many mobile robotic platforms rely on an accurate knowledge of the extrinsic calibration parameters, especially systems performing visual stereo matching. Although a number of accurate stereo camera calibration methods have been developed, which provide good initial "factory" calibrations, the determined parameters can lose their validity over time as the sensors are exposed to environmental conditions and external effects. Thus, on autonomous platforms on-board diagnostic methods for an early detection of the need to repeat calibration procedures have the potential to prevent critical failures of crucial systems, such as state estimation or obstacle detection. In this work, we present a novel data-driven method to estimate the calibration quality and detect discrepancies between the original calibration and the current system state for stereo camera systems. The framework consists of a novel dataset generation pipeline to train CalQNet, a deep convolutional neural network. CalQNet can estimate the calibration quality using a new metric that approximates the degree of miscalibration in stereo setups. We show the framework's ability to predict from a single stereo frame if a state-of-the-art stereo-visual odometry system will diverge due to a degraded calibration in two real-world experiments.
Hough2Map -- Iterative Event-based Hough Transform for High-Speed Railway Mapping
Feb 18, 2021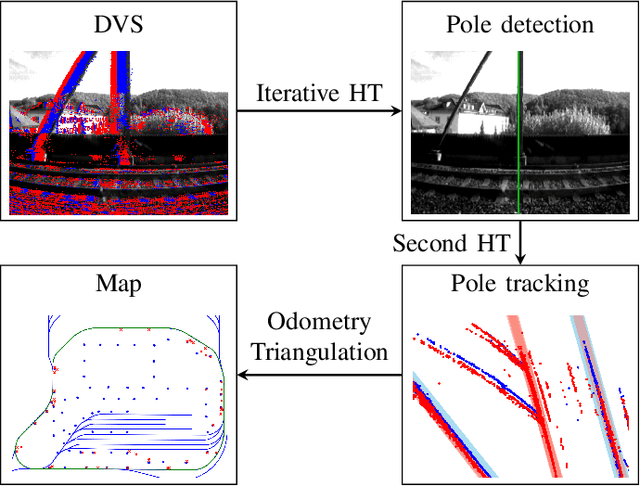

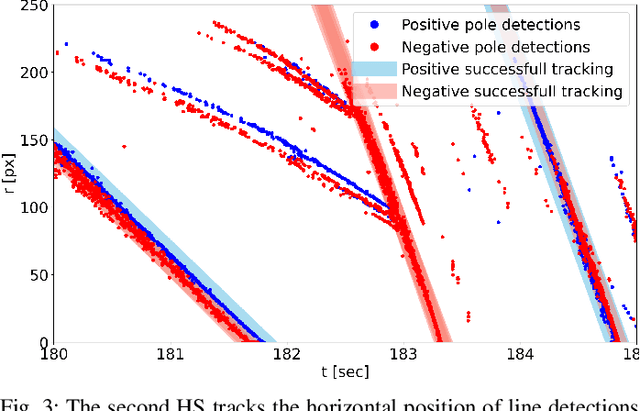

To cope with the growing demand for transportation on the railway system, accurate, robust, and high-frequency positioning is required to enable a safe and efficient utilization of the existing railway infrastructure. As a basis for a localization system we propose a complete on-board mapping pipeline able to map robust meaningful landmarks, such as poles from power lines, in the vicinity of the vehicle. Such poles are good candidates for reliable and long term landmarks even through difficult weather conditions or seasonal changes. To address the challenges of motion blur and illumination changes in railway scenarios we employ a Dynamic Vision Sensor, a novel event-based camera. Using a sideways oriented on-board camera, poles appear as vertical lines. To map such lines in a real-time event stream, we introduce Hough2Map, a novel consecutive iterative event-based Hough transform framework capable of detecting, tracking, and triangulating close-by structures. We demonstrate the mapping reliability and accuracy of Hough2Map on real-world data in typical usage scenarios and evaluate using surveyed infrastructure ground truth maps. Hough2Map achieves a detection reliability of up to 92% and a mapping root mean square error accuracy of 1.1518m.