 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile Airborne Ultrasonic NDT Technologies via Active Omni-Sliding with Over-Actuated Aerial Vehicles
Nov 08, 2023This paper presents the utilization of advanced methodologies in aerial manipulation to address meaningful industrial applications and develop versatile ultrasonic Non-Destructive Testing (NDT) technologies with aerial robots. The primary objectives of this work are to enable multi-point measurements through sliding without re-approaching the work surface, and facilitate the representation of material thickness with B and C scans via dynamic scanning in arbitrary directions (i.e. omnidirections). To accomplish these objectives, a payload that can slide in omnidirections (here we call the omni-sliding payload) is designed for an over-actuated aerial vehicle, ensuring truly omnidirectional sliding mobility while exerting consistent forces in contact with a flat work surface. The omni-sliding payload is equipped with an omniwheel-based active end-effector and an Electro Magnetic Acoustic Transducer (EMAT). Furthermore, to ensure successful development of the designed payload and integration with the aerial vehicle, a comprehensive studying on contact conditions and system dynamics during active sliding is presented, and the derived system constraints are later used as guidelines for the hardware development and control setting. The proposed methods are validated through experiments, encompassing both the wall-sliding task and dynamic scanning for Ultrasonic Testing (UT), employing the aerial platform - Voliro T.
maplab 2.0 -- A Modular and Multi-Modal Mapping Framework
Dec 01, 2022Integration of multiple sensor modalities and deep learning into Simultaneous Localization And Mapping (SLAM) systems are areas of significant interest in current research. Multi-modality is a stepping stone towards achieving robustness in challenging environments and interoperability of heterogeneous multi-robot systems with varying sensor setups. With maplab 2.0, we provide a versatile open-source platform that facilitates developing, testing, and integrating new modules and features into a fully-fledged SLAM system. Through extensive experiments, we show that maplab 2.0's accuracy is comparable to the state-of-the-art on the HILTI 2021 benchmark. Additionally, we showcase the flexibility of our system with three use cases: i) large-scale (approx. 10 km) multi-robot multi-session (23 missions) mapping, ii) integration of non-visual landmarks, and iii) incorporating a semantic object-based loop closure module into the mapping framework. The code is available open-source at https://github.com/ethz-asl/maplab.
CERBERUS: Autonomous Legged and Aerial Robotic Exploration in the Tunnel and Urban Circuits of the DARPA Subterranean Challenge
Jan 18, 2022

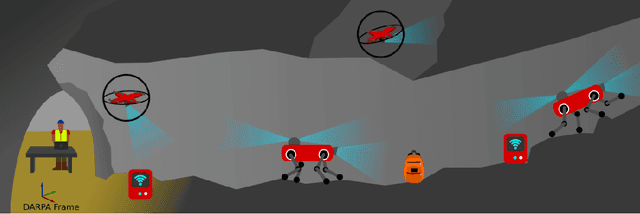

Autonomous exploration of subterranean environments constitutes a major frontier for robotic systems as underground settings present key challenges that can render robot autonomy hard to achieve. This has motivated the DARPA Subterranean Challenge, where teams of robots search for objects of interest in various underground environments. In response, the CERBERUS system-of-systems is presented as a unified strategy towards subterranean exploration using legged and flying robots. As primary robots, ANYmal quadruped systems are deployed considering their endurance and potential to traverse challenging terrain. For aerial robots, both conventional and collision-tolerant multirotors are utilized to explore spaces too narrow or otherwise unreachable by ground systems. Anticipating degraded sensing conditions, a complementary multi-modal sensor fusion approach utilizing camera, LiDAR, and inertial data for resilient robot pose estimation is proposed. Individual robot pose estimates are refined by a centralized multi-robot map optimization approach to improve the reported location accuracy of detected objects of interest in the DARPA-defined coordinate frame. Furthermore, a unified exploration path planning policy is presented to facilitate the autonomous operation of both legged and aerial robots in complex underground networks. Finally, to enable communication between the robots and the base station, CERBERUS utilizes a ground rover with a high-gain antenna and an optical fiber connection to the base station, alongside breadcrumbing of wireless nodes by our legged robots. We report results from the CERBERUS system-of-systems deployment at the DARPA Subterranean Challenge Tunnel and Urban Circuits, along with the current limitations and the lessons learned for the benefit of the community.
3D3L: Deep Learned 3D Keypoint Detection and Description for LiDARs
Apr 12, 2021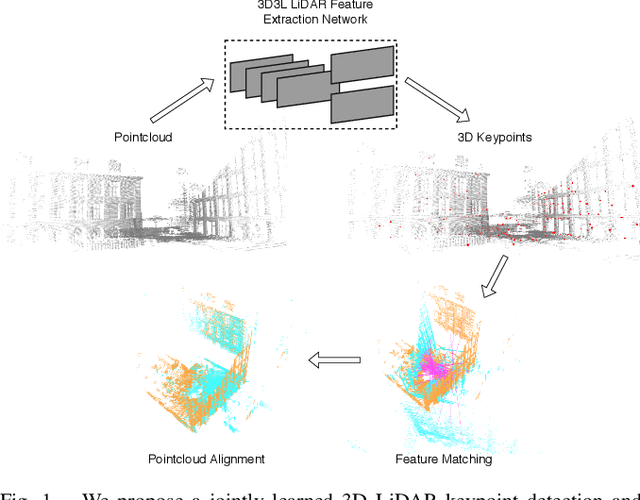
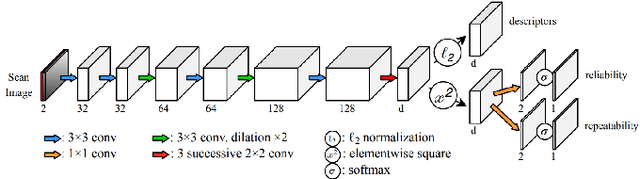
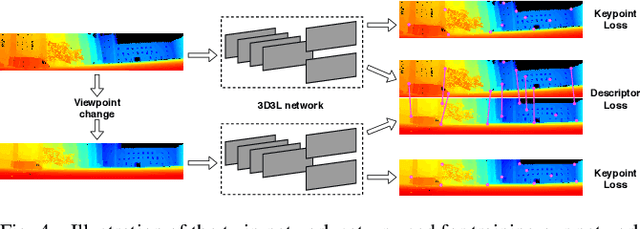

With the advent of powerful, light-weight 3D LiDARs, they have become the hearth of many navigation and SLAM algorithms on various autonomous systems. Pointcloud registration methods working with unstructured pointclouds such as ICP are often computationally expensive or require a good initial guess. Furthermore, 3D feature-based registration methods have never quite reached the robustness of 2D methods in visual SLAM. With the continuously increasing resolution of LiDAR range images, these 2D methods not only become applicable but should exploit the illumination-independent modalities that come with it, such as depth and intensity. In visual SLAM, deep learned 2D features and descriptors perform exceptionally well compared to traditional methods. In this publication, we use a state-of-the-art 2D feature network as a basis for 3D3L, exploiting both intensity and depth of LiDAR range images to extract powerful 3D features. Our results show that these keypoints and descriptors extracted from LiDAR scan images outperform state-of-the-art on different benchmark metrics and allow for robust scan-to-scan alignment as well as global localization.
VersaVIS: An Open Versatile Multi-Camera Visual-Inertial Sensor Suite
Dec 05, 2019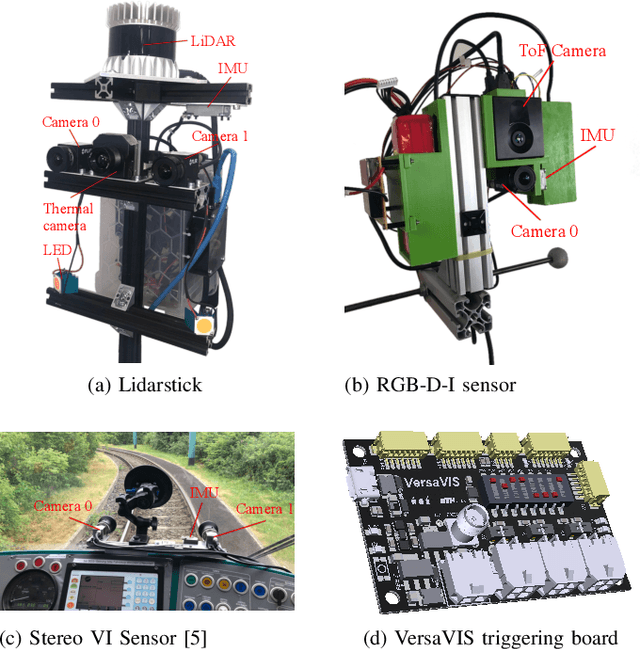
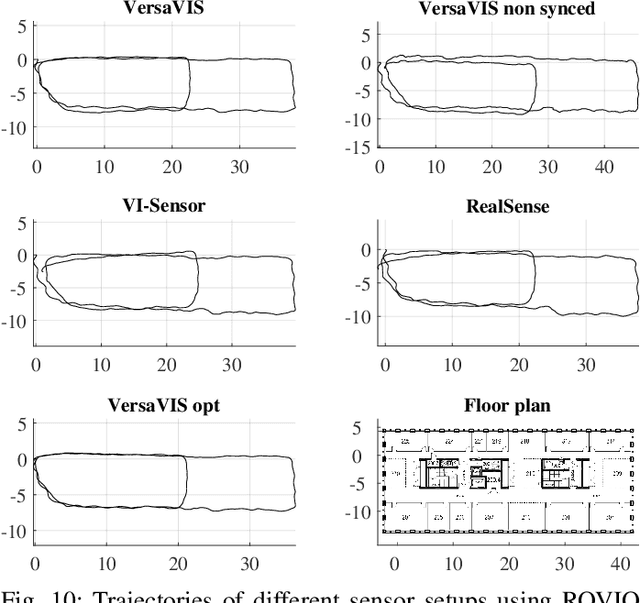
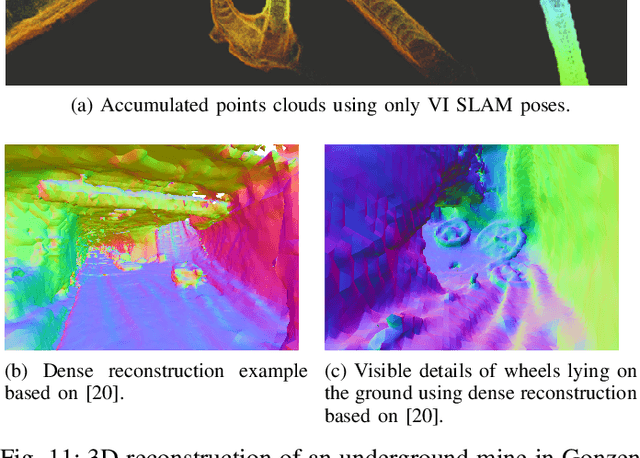
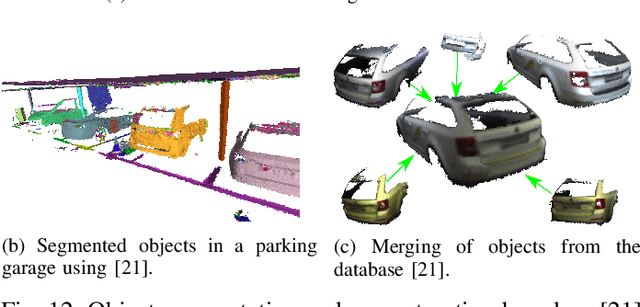
Robust and accurate pose estimation is crucial for many applications in mobile robotics. Extending visual Simultaneous Localization and Mapping (SLAM) with other modalities such as an inertial measurement unit (IMU) can boost robustness and accuracy. However, for a tight sensor fusion, accurate time synchronization of the sensors is often crucial. Changing exposure times, internal sensor filtering, multiple clock sources and unpredictable delays from operation system scheduling and data transfer can make sensor synchronization challenging. In this paper, we present VersaVIS, an Open Versatile Multi-Camera Visual-Inertial Sensor Suite aimed to be an efficient research platform for easy deployment, integration and extension for many mobile robotic applications. VersaVIS provides a complete, open-source hardware, firmware and software bundle to perform time synchronization of multiple cameras with an IMU featuring exposure compensation, host clock translation and independent and stereo camera triggering. The sensor suite supports a wide range of cameras and IMUs to match the requirements of the application. The synchronization accuracy of the framework is evaluated on multiple experiments achieving timing accuracy of less than 1 ms. Furthermore, the applicability and versatility of the sensor suite is demonstrated in multiple applications including visual-inertial SLAM, multi-camera applications, multimodal mapping, reconstruction and object based mapping.
Predicting Unobserved Space For Planning via Depth Map Augmentation
Nov 13, 2019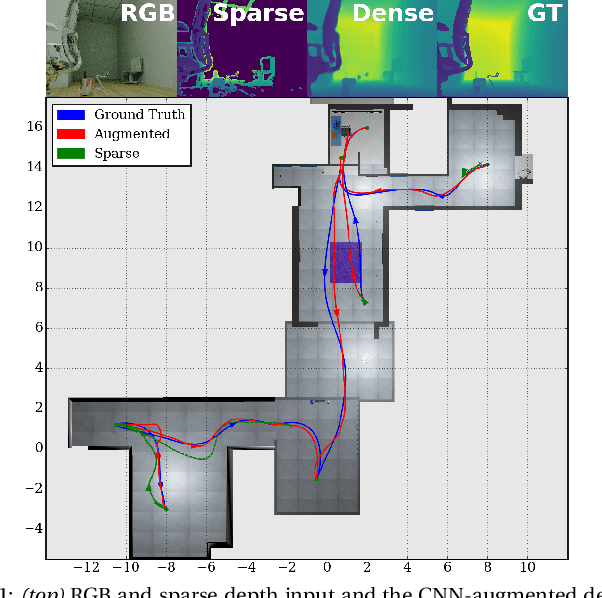
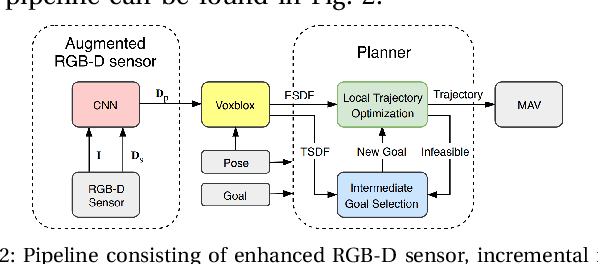

Safe and efficient path planning is crucial for autonomous mobile robots. A prerequisite for path planning is to have a comprehensive understanding of the 3D structure of the robot's environment. On MAVs this is commonly achieved using low-cost sensors, such as stereo or RGB-D cameras. These sensors may fail to provide depth measurements in textureless or IR-absorbing areas and have limited effective range. In path planning, this results in inefficient trajectories or failure to recognize a feasible path to the goal, hence significantly impairing the robot's mobility. Recent advances in deep learning enables us to exploit prior experience about the shape of the world and hence to infer complete depth maps from color images and additional sparse depth measurements. In this work, we present an augmented planning system and investigate the effects of employing state-of-the-art depth completion techniques, specifically trained to augment sparse depth maps originating from RGB-D sensors, semi-dense methods and stereo matchers. We extensively evaluate our approach in online path planning experiments based on simulated data, as well as global path planning experiments based on real world MAV data. We show that our augmented system, provided with only sparse depth perception, can reach on-par performance to ground truth depth input in simulated online planning experiments. On real world MAV data the augmented system demonstrates superior performance compared to a planner based on very dense RGB-D depth maps.
Incremental Object Database: Building 3D Models from Multiple Partial Observations
Aug 02, 2018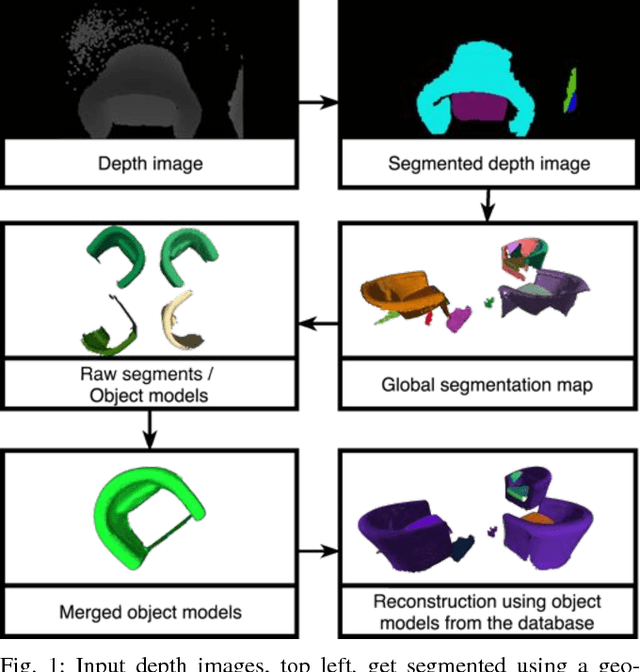

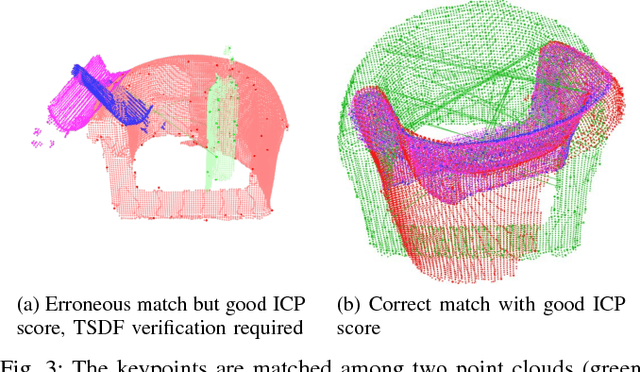
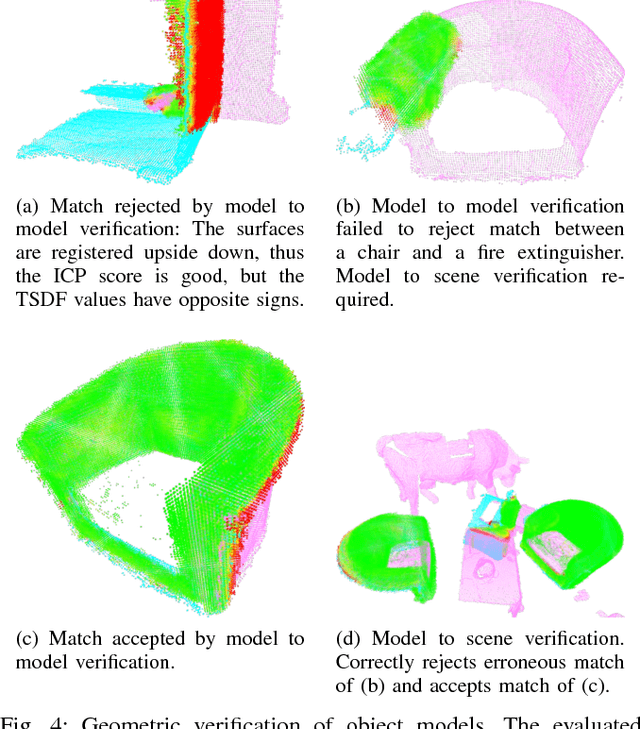
Collecting 3D object datasets involves a large amount of manual work and is time consuming. Getting complete models of objects either requires a 3D scanner that covers all the surfaces of an object or one needs to rotate it to completely observe it. We present a system that incrementally builds a database of objects as a mobile agent traverses a scene. Our approach requires no prior knowledge of the shapes present in the scene. Object-like segments are extracted from a global segmentation map, which is built online using the input of segmented RGB-D images. These segments are stored in a database, matched among each other, and merged with other previously observed instances. This allows us to create and improve object models on the fly and to use these merged models to reconstruct also unobserved parts of the scene. The database contains each (potentially merged) object model only once, together with a set of poses where it was observed. We evaluate our pipeline with one public dataset, and on a newly created Google Tango dataset containing four indoor scenes with some of the objects appearing multiple times, both within and across scenes.
Long-term Large-scale Mapping and Localization Using maplab
May 28, 2018

This paper discusses a large-scale and long-term mapping and localization scenario using the maplab open-source framework. We present a brief overview of the specific algorithms in the system that enable building a consistent map from multiple sessions. We then demonstrate that such a map can be reused even a few months later for efficient 6-DoF localization and also new trajectories can be registered within the existing 3D model. The datasets presented in this paper are made publicly available.
History-aware Autonomous Exploration in Confined Environments using MAVs
Mar 28, 2018
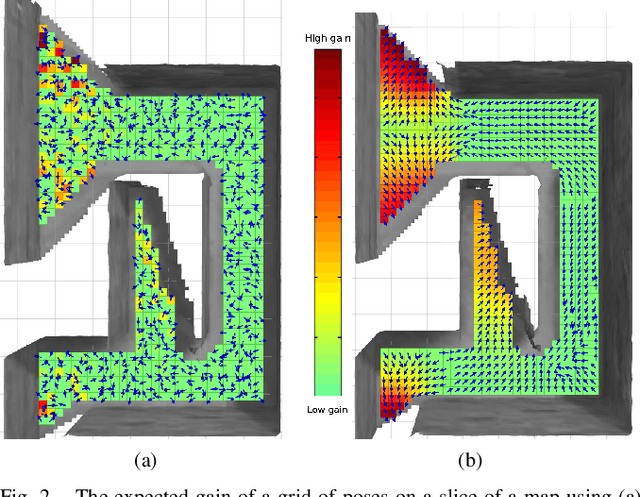

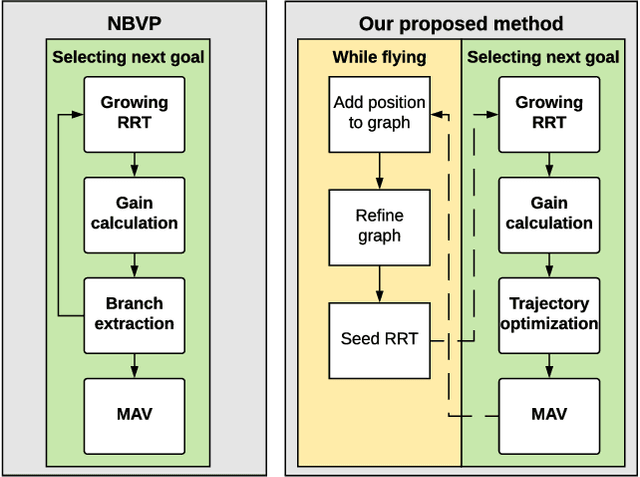
Many scenarios require a robot to be able to explore its 3D environment online without human supervision. This is especially relevant for inspection tasks and search and rescue missions. To solve this high-dimensional path planning problem, sampling-based exploration algorithms have proven successful. However, these do not necessarily scale well to larger environments or spaces with narrow openings. This paper presents a 3D exploration planner based on the principles of Next-Best Views (NBVs). In this approach, a Micro-Aerial Vehicle (MAV) equipped with a limited field-of-view depth sensor randomly samples its configuration space to find promising future viewpoints. In order to obtain high sampling efficiency, our planner maintains and uses a history of visited places, and locally optimizes the robot's orientation with respect to unobserved space. We evaluate our method in several simulated scenarios, and compare it against a state-of-the-art exploration algorithm. The experiments show substantial improvements in exploration time ($2\times$ faster), computation time, and path length, and advantages in handling difficult situations such as escaping dead-ends (up to $20\times$ faster). Finally, we validate the on-line capability of our algorithm on a computational constrained real world MAV.
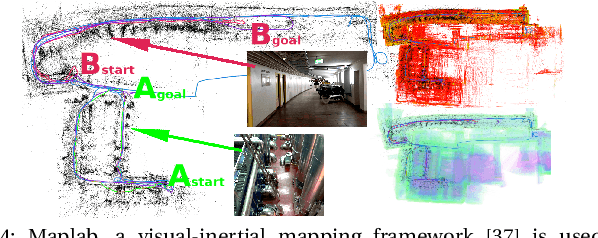
Visual-Inertial Teach and Repeat for Aerial Inspection
Mar 26, 2018
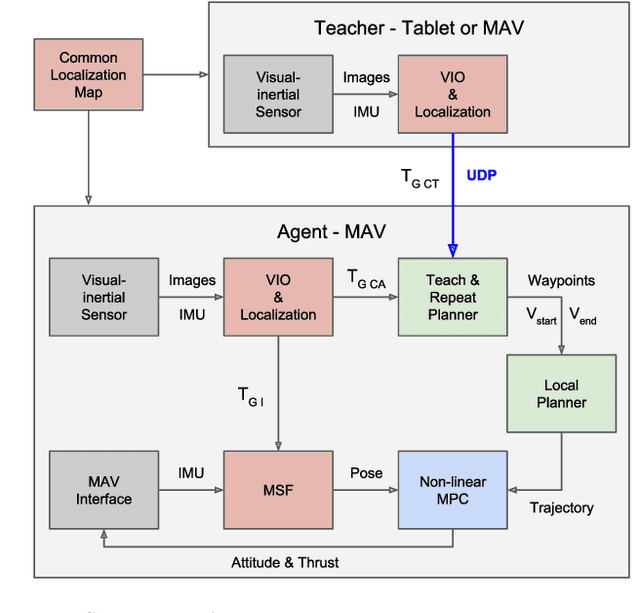

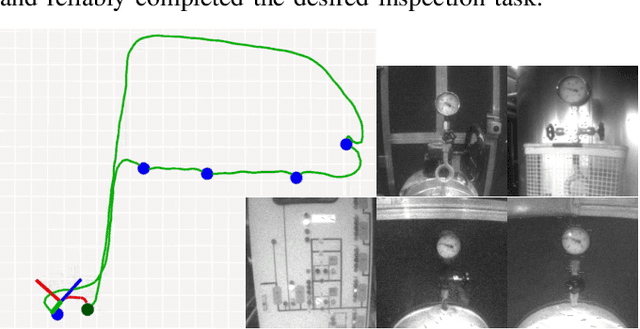
Industrial facilities often require periodic visual inspections of key installations. Examining these points of interest is time consuming, potentially hazardous or require special equipment to reach. MAVs are ideal platforms to automate this expensive and tedious task. In this work we present a novel system that enables a human operator to teach a visual inspection task to an autonomous aerial vehicle by simply demonstrating the task using a handheld device. To enable robust operation in confined, GPS-denied environments, the system employs the Google Tango visual-inertial mapping framework as the only source of pose estimates. In a first step the operator records the desired inspection path and defines the inspection points. The mapping framework then computes a feature-based localization map, which is shared with the robot. After take-off, the robot estimates its pose based on this map and plans a smooth trajectory through the way points defined by the operator. Furthermore, the system is able to track the poses of other robots or the operator, localized in the same map, and follow them in real-time while keeping a safe distance.