 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully-Convolutional Point Networks for Large-Scale Point Clouds
Aug 21, 2018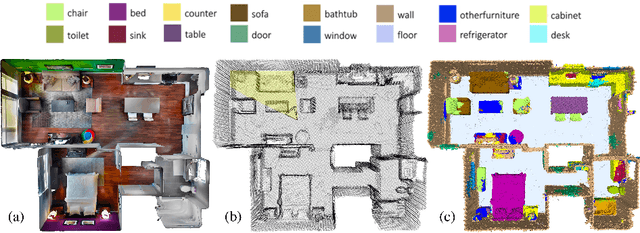
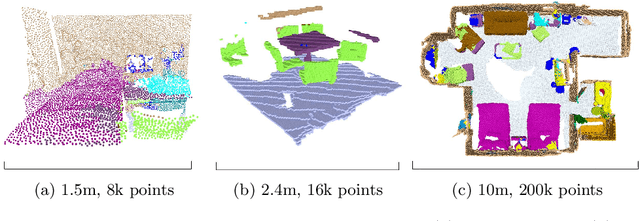

This work proposes a general-purpose, fully-convolutional network architecture for efficiently processing large-scale 3D data. One striking characteristic of our approach is its ability to process unorganized 3D representations such as point clouds as input, then transforming them internally to ordered structures to be processed via 3D convolutions. In contrast to conventional approaches that maintain either unorganized or organized representations, from input to output, our approach has the advantage of operating on memory efficient input data representations while at the same time exploiting the natural structure of convolutional operations to avoid the redundant computing and storing of spatial information in the network. The network eliminates the need to pre- or post process the raw sensor data. This, together with the fully-convolutional nature of the network, makes it an end-to-end method able to process point clouds of huge spaces or even entire rooms with up to 200k points at once. Another advantage is that our network can produce either an ordered output or map predictions directly onto the input cloud, thus making it suitable as a general-purpose point cloud descriptor applicable to many 3D tasks. We demonstrate our network's ability to effectively learn both low-level features as well as complex compositional relationships by evaluating it on benchmark datasets for semantic voxel segmentation, semantic part segmentation and 3D scene captioning.
ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans
Mar 28, 2018
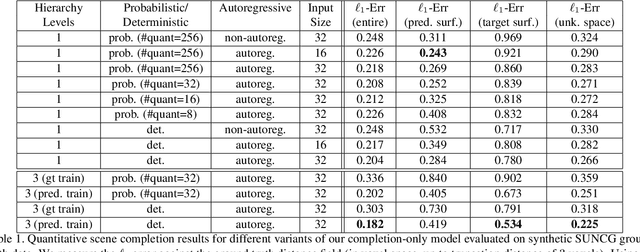

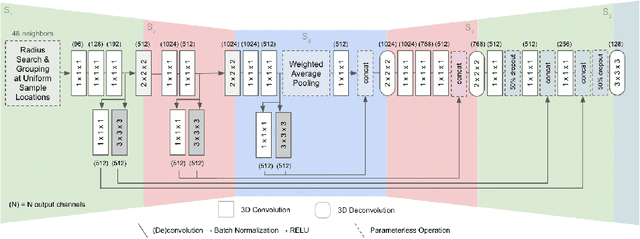
We introduce ScanComplete, a novel data-driven approach for taking an incomplete 3D scan of a scene as input and predicting a complete 3D model along with per-voxel semantic labels. The key contribution of our method is its ability to handle large scenes with varying spatial extent, managing the cubic growth in data size as scene size increases. To this end, we devise a fully-convolutional generative 3D CNN model whose filter kernels are invariant to the overall scene size. The model can be trained on scene subvolumes but deployed on arbitrarily large scenes at test time. In addition, we propose a coarse-to-fine inference strategy in order to produce high-resolution output while also leveraging large input context sizes. In an extensive series of experiments, we carefully evaluate different model design choices, considering both deterministic and probabilistic models for completion and semantic inference. Our results show that we outperform other methods not only in the size of the environments handled and processing efficiency, but also with regard to completion quality and semantic segmentation performance by a significant margin.
Visual-Inertial Teach and Repeat for Aerial Inspection
Mar 26, 2018
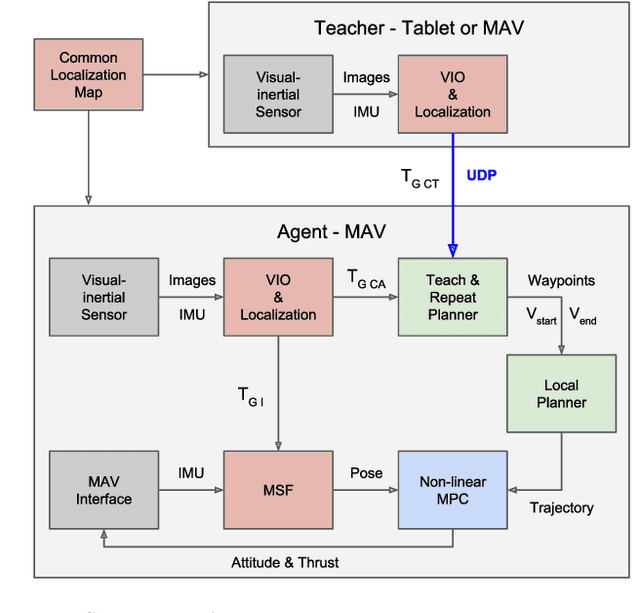

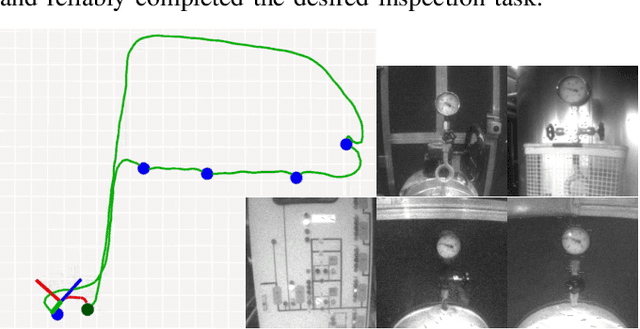
Industrial facilities often require periodic visual inspections of key installations. Examining these points of interest is time consuming, potentially hazardous or require special equipment to reach. MAVs are ideal platforms to automate this expensive and tedious task. In this work we present a novel system that enables a human operator to teach a visual inspection task to an autonomous aerial vehicle by simply demonstrating the task using a handheld device. To enable robust operation in confined, GPS-denied environments, the system employs the Google Tango visual-inertial mapping framework as the only source of pose estimates. In a first step the operator records the desired inspection path and defines the inspection points. The mapping framework then computes a feature-based localization map, which is shared with the robot. After take-off, the robot estimates its pose based on this map and plans a smooth trajectory through the way points defined by the operator. Furthermore, the system is able to track the poses of other robots or the operator, localized in the same map, and follow them in real-time while keeping a safe distance.
De-noising, Stabilizing and Completing 3D Reconstructions On-the-go using Plane Priors
Mar 28, 2017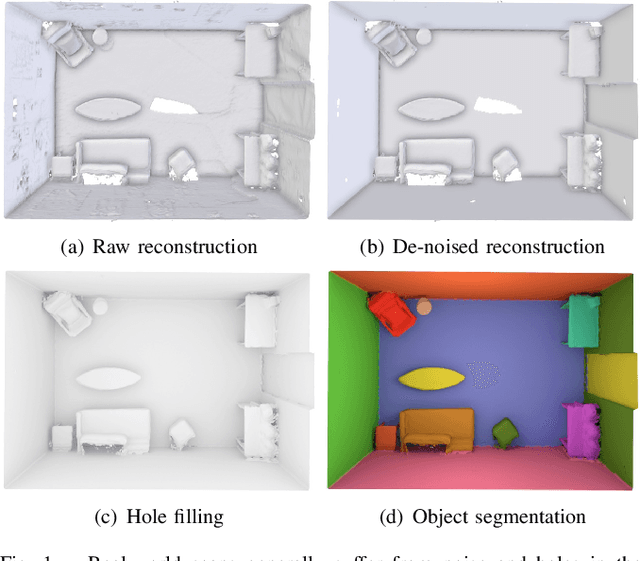
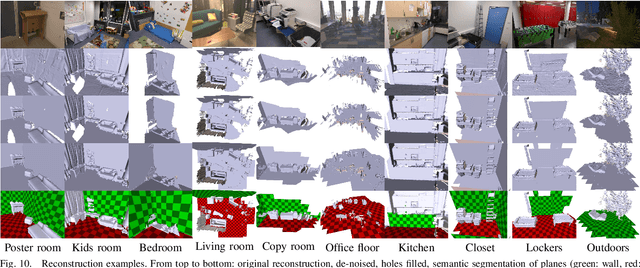

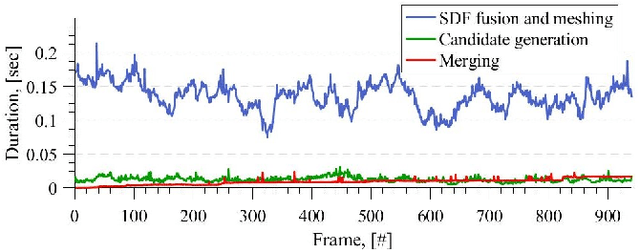
Creating 3D maps on robots and other mobile devices has become a reality in recent years. Online 3D reconstruction enables many exciting applications in robotics and AR/VR gaming. However, the reconstructions are noisy and generally incomplete. Moreover, during onine reconstruction, the surface changes with every newly integrated depth image which poses a significant challenge for physics engines and path planning algorithms. This paper presents a novel, fast and robust method for obtaining and using information about planar surfaces, such as walls, floors, and ceilings as a stage in 3D reconstruction based on Signed Distance Fields. Our algorithm recovers clean and accurate surfaces, reduces the movement of individual mesh vertices caused by noise during online reconstruction and fills in the occluded and unobserved regions. We implemented and evaluated two different strategies to generate plane candidates and two strategies for merging them. Our implementation is optimized to run in real-time on mobile devices such as the Tango tablet. In an extensive set of experiments, we validated that our approach works well in a large number of natural environments despite the presence of significant amount of occlusion, clutter and noise, which occur frequently. We further show that plane fitting enables in many cases a meaningful semantic segmentation of real-world scenes.
A Probabilistic Framework for Learning Kinematic Models of Articulated Objects
Jan 16, 2014
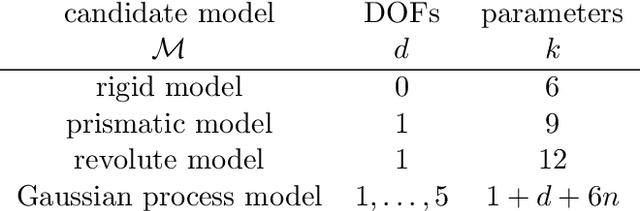

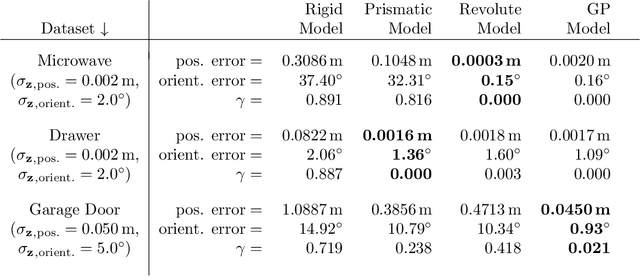
Robots operating in domestic environments generally need to interact with articulated objects, such as doors, cabinets, dishwashers or fridges. In this work, we present a novel, probabilistic framework for modeling articulated objects as kinematic graphs. Vertices in this graph correspond to object parts, while edges between them model their kinematic relationship. In particular, we present a set of parametric and non-parametric edge models and how they can robustly be estimated from noisy pose observations. We furthermore describe how to estimate the kinematic structure and how to use the learned kinematic models for pose prediction and for robotic manipulation tasks. We finally present how the learned models can be generalized to new and previously unseen objects. In various experiments using real robots with different camera systems as well as in simulation, we show that our approach is valid, accurate and efficient. Further, we demonstrate that our approach has a broad set of applications, in particular for the emerging fields of mobile manipulation and service robotics.