 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoLM: Multi-Modal Language Model of Egocentric Motions
Sep 26, 2024



As the prevalence of wearable devices, learning egocentric motions becomes essential to develop contextual AI. In this work, we present EgoLM, a versatile framework that tracks and understands egocentric motions from multi-modal inputs, e.g., egocentric videos and motion sensors. EgoLM exploits rich contexts for the disambiguation of egomotion tracking and understanding, which are ill-posed under single modality conditions. To facilitate the versatile and multi-modal framework, our key insight is to model the joint distribution of egocentric motions and natural languages using large language models (LLM). Multi-modal sensor inputs are encoded and projected to the joint latent space of language models, and used to prompt motion generation or text generation for egomotion tracking or understanding, respectively. Extensive experiments on large-scale multi-modal human motion dataset validate the effectiveness of EgoLM as a generalist model for universal egocentric learning.
Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild
Jun 14, 2024We introduce Nymeria - a large-scale, diverse, richly annotated human motion dataset collected in the wild with multiple multimodal egocentric devices. The dataset comes with a) full-body 3D motion ground truth; b) egocentric multimodal recordings from Project Aria devices with RGB, grayscale, eye-tracking cameras, IMUs, magnetometer, barometer, and microphones; and c) an additional "observer" device providing a third-person viewpoint. We compute world-aligned 6DoF transformations for all sensors, across devices and capture sessions. The dataset also provides 3D scene point clouds and calibrated gaze estimation. We derive a protocol to annotate hierarchical language descriptions of in-context human motion, from fine-grain pose narrations, to atomic actions and activity summarization. To the best of our knowledge, the Nymeria dataset is the world largest in-the-wild collection of human motion with natural and diverse activities; first of its kind to provide synchronized and localized multi-device multimodal egocentric data; and the world largest dataset with motion-language descriptions. It contains 1200 recordings of 300 hours of daily activities from 264 participants across 50 locations, travelling a total of 399Km. The motion-language descriptions provide 310.5K sentences in 8.64M words from a vocabulary size of 6545. To demonstrate the potential of the dataset we define key research tasks for egocentric body tracking, motion synthesis, and action recognition and evaluate several state-of-the-art baseline algorithms. Data and code will be open-sourced.
DivaTrack: Diverse Bodies and Motions from Acceleration-Enhanced Three-Point Trackers
Feb 14, 2024Full-body avatar presence is crucial for immersive social and environmental interactions in digital reality. However, current devices only provide three six degrees of freedom (DOF) poses from the headset and two controllers (i.e. three-point trackers). Because it is a highly under-constrained problem, inferring full-body pose from these inputs is challenging, especially when supporting the full range of body proportions and use cases represented by the general population. In this paper, we propose a deep learning framework, DivaTrack, which outperforms existing methods when applied to diverse body sizes and activities. We augment the sparse three-point inputs with linear accelerations from Inertial Measurement Units (IMU) to improve foot contact prediction. We then condition the otherwise ambiguous lower-body pose with the predictions of foot contact and upper-body pose in a two-stage model. We further stabilize the inferred full-body pose in a wide range of configurations by learning to blend predictions that are computed in two reference frames, each of which is designed for different types of motions. We demonstrate the effectiveness of our design on a large dataset that captures 22 subjects performing challenging locomotion for three-point tracking, including lunges, hula-hooping, and sitting. As shown in a live demo using the Meta VR headset and Xsens IMUs, our method runs in real-time while accurately tracking a user's motion when they perform a diverse set of movements.
FoundPose: Unseen Object Pose Estimation with Foundation Features
Nov 30, 2023



We propose FoundPose, a method for 6D pose estimation of unseen rigid objects from a single RGB image. The method assumes that 3D models of the objects are available but does not require any object-specific training. This is achieved by building upon DINOv2, a recent vision foundation model with impressive generalization capabilities. An online pose estimation stage is supported by a minimal object representation that is built during a short onboarding stage from DINOv2 patch features extracted from rendered object templates. Given a query image with an object segmentation mask, FoundPose first rapidly retrieves a handful of similarly looking templates by a DINOv2-based bag-of-words approach. Pose hypotheses are then generated from 2D-3D correspondences established by matching DINOv2 patch features between the query image and a retrieved template, and finally optimized by featuremetric refinement. The method can handle diverse objects, including challenging ones with symmetries and without any texture, and noticeably outperforms existing RGB methods for coarse pose estimation in both accuracy and speed on the standard BOP benchmark. With the featuremetric and additional MegaPose refinement, which are demonstrated complementary, the method outperforms all RGB competitors. Source code is at: evinpinar.github.io/foundpose.
EgoHumans: An Egocentric 3D Multi-Human Benchmark
May 25, 2023



We present EgoHumans, a new multi-view multi-human video benchmark to advance the state-of-the-art of egocentric human 3D pose estimation and tracking. Existing egocentric benchmarks either capture single subject or indoor-only scenarios, which limit the generalization of computer vision algorithms for real-world applications. We propose a novel 3D capture setup to construct a comprehensive egocentric multi-human benchmark in the wild with annotations to support diverse tasks such as human detection, tracking, 2D/3D pose estimation, and mesh recovery. We leverage consumer-grade wearable camera-equipped glasses for the egocentric view, which enables us to capture dynamic activities like playing soccer, fencing, volleyball, etc. Furthermore, our multi-view setup generates accurate 3D ground truth even under severe or complete occlusion. The dataset consists of more than 125k egocentric images, spanning diverse scenes with a particular focus on challenging and unchoreographed multi-human activities and fast-moving egocentric views. We rigorously evaluate existing state-of-the-art methods and highlight their limitations in the egocentric scenario, specifically on multi-human tracking. To address such limitations, we propose EgoFormer, a novel approach with a multi-stream transformer architecture and explicit 3D spatial reasoning to estimate and track the human pose. EgoFormer significantly outperforms prior art by 13.6% IDF1 and 9.3 HOTA on the EgoHumans dataset.
In-Hand 3D Object Scanning from an RGB Sequence
Nov 28, 2022
We propose a method for in-hand 3D scanning of an unknown object from a sequence of color images. We cast the problem as reconstructing the object surface from un-posed multi-view images and rely on a neural implicit surface representation that captures both the geometry and the appearance of the object. By contrast with most NeRF-based methods, we do not assume that the camera-object relative poses are known and instead simultaneously optimize both the object shape and the pose trajectory. As global optimization over all the shape and pose parameters is prone to fail without coarse-level initialization of the poses, we propose an incremental approach which starts by splitting the sequence into carefully selected overlapping segments within which the optimization is likely to succeed. We incrementally reconstruct the object shape and track the object poses independently within each segment, and later merge all the segments by aligning poses estimated at the overlapping frames. Finally, we perform a global optimization over all the aligned segments to achieve full reconstruction. We experimentally show that the proposed method is able to reconstruct the shape and color of both textured and challenging texture-less objects, outperforms classical methods that rely only on appearance features, and its performance is close to recent methods that assume known camera poses.
Neural Correspondence Field for Object Pose Estimation
Jul 30, 2022
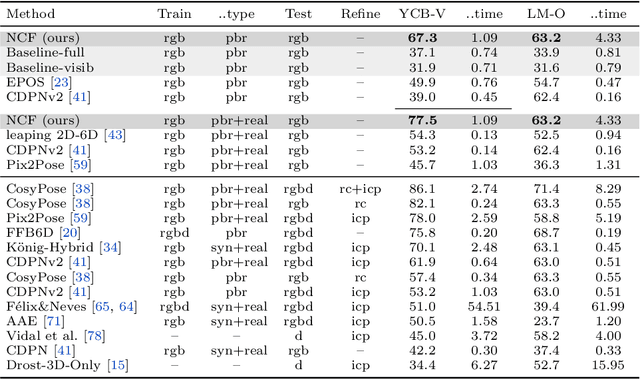
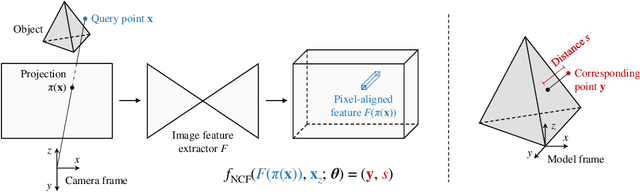
We propose a method for estimating the 6DoF pose of a rigid object with an available 3D model from a single RGB image. Unlike classical correspondence-based methods which predict 3D object coordinates at pixels of the input image, the proposed method predicts 3D object coordinates at 3D query points sampled in the camera frustum. The move from pixels to 3D points, which is inspired by recent PIFu-style methods for 3D reconstruction, enables reasoning about the whole object, including its (self-)occluded parts. For a 3D query point associated with a pixel-aligned image feature, we train a fully-connected neural network to predict: (i) the corresponding 3D object coordinates, and (ii) the signed distance to the object surface, with the first defined only for query points in the surface vicinity. We call the mapping realized by this network as Neural Correspondence Field. The object pose is then robustly estimated from the predicted 3D-3D correspondences by the Kabsch-RANSAC algorithm. The proposed method achieves state-of-the-art results on three BOP datasets and is shown superior especially in challenging cases with occlusion. The project website is at: linhuang17.github.io/NCF.
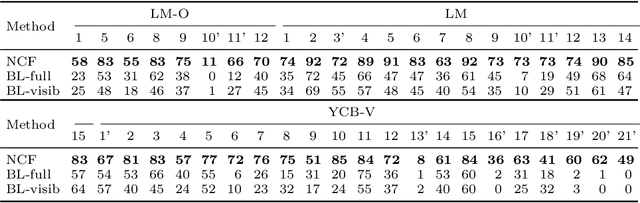
Snipper: A Spatiotemporal Transformer for Simultaneous Multi-Person 3D Pose Estimation Tracking and Forecasting on a Video Snippet
Jul 13, 2022
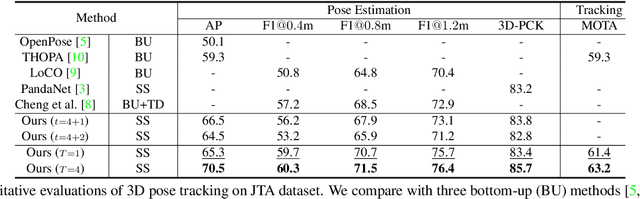
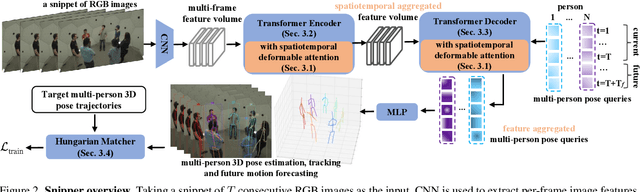
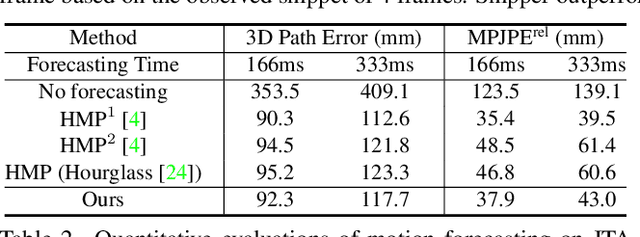
Multi-person pose understanding from RGB videos includes three complex tasks: pose estimation, tracking and motion forecasting. Among these three tasks, pose estimation and tracking are correlated, and tracking is crucial to motion forecasting. Most existing works either focus on a single task or employ cascaded methods to solve each individual task separately. In this paper, we propose Snipper, a framework to perform multi-person 3D pose estimation, tracking and motion forecasting simultaneously in a single inference. Specifically, we first propose a deformable attention mechanism to aggregate spatiotemporal information from video snippets. Building upon this deformable attention, a visual transformer is learned to encode the spatiotemporal features from multi-frame images and to decode informative pose features to update multi-person pose queries. Last, these queries are regressed to predict multi-person pose trajectories and future motions in one forward pass. In the experiments, we show the effectiveness of Snipper on three challenging public datasets where a generic model rivals specialized state-of-art baselines for pose estimation, tracking, and forecasting. Code is available at https://github.com/JimmyZou/Snipper
Self-supervised Neural Articulated Shape and Appearance Models
May 17, 2022


Learning geometry, motion, and appearance priors of object classes is important for the solution of a large variety of computer vision problems. While the majority of approaches has focused on static objects, dynamic objects, especially with controllable articulation, are less explored. We propose a novel approach for learning a representation of the geometry, appearance, and motion of a class of articulated objects given only a set of color images as input. In a self-supervised manner, our novel representation learns shape, appearance, and articulation codes that enable independent control of these semantic dimensions. Our model is trained end-to-end without requiring any articulation annotations. Experiments show that our approach performs well for different joint types, such as revolute and prismatic joints, as well as different combinations of these joints. Compared to state of the art that uses direct 3D supervision and does not output appearance, we recover more faithful geometry and appearance from 2D observations only. In addition, our representation enables a large variety of applications, such as few-shot reconstruction, the generation of novel articulations, and novel view-synthesis.
LISA: Learning Implicit Shape and Appearance of Hands
Apr 04, 2022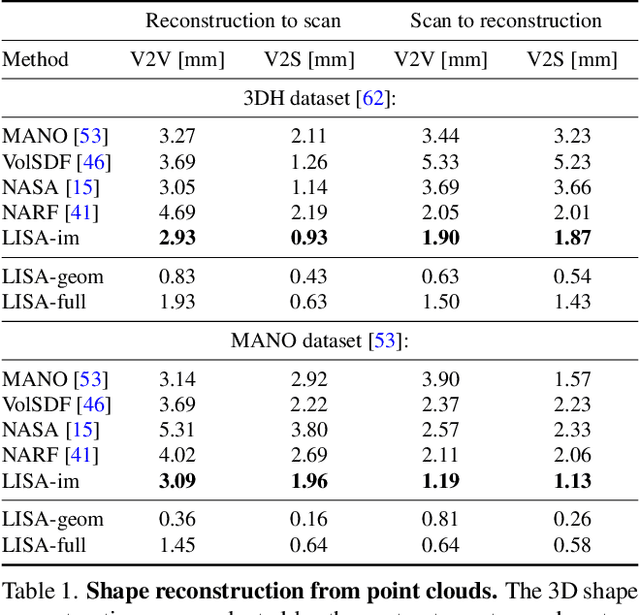
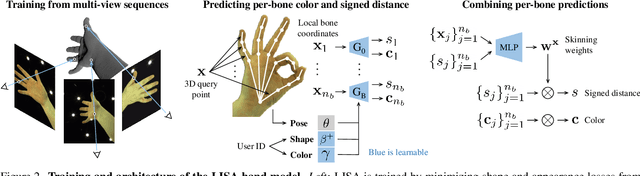
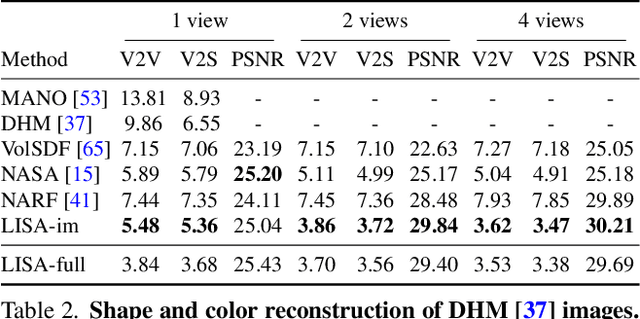

This paper proposes a do-it-all neural model of human hands, named LISA. The model can capture accurate hand shape and appearance, generalize to arbitrary hand subjects, provide dense surface correspondences, be reconstructed from images in the wild and easily animated. We train LISA by minimizing the shape and appearance losses on a large set of multi-view RGB image sequences annotated with coarse 3D poses of the hand skeleton. For a 3D point in the hand local coordinate, our model predicts the color and the signed distance with respect to each hand bone independently, and then combines the per-bone predictions using predicted skinning weights. The shape, color and pose representations are disentangled by design, allowing to estimate or animate only selected parameters. We experimentally demonstrate that LISA can accurately reconstruct a dynamic hand from monocular or multi-view sequences, achieving a noticeably higher quality of reconstructed hand shapes compared to baseline approaches. Project page: https://www.iri.upc.edu/people/ecorona/lisa/.