 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoTrack: Generic 6DoF Object Pose Refinement and Tracking
Jun 08, 2025We introduce GoTrack, an efficient and accurate CAD-based method for 6DoF object pose refinement and tracking, which can handle diverse objects without any object-specific training. Unlike existing tracking methods that rely solely on an analysis-by-synthesis approach for model-to-frame registration, GoTrack additionally integrates frame-to-frame registration, which saves compute and stabilizes tracking. Both types of registration are realized by optical flow estimation. The model-to-frame registration is noticeably simpler than in existing methods, relying only on standard neural network blocks (a transformer is trained on top of DINOv2) and producing reliable pose confidence scores without a scoring network. For the frame-to-frame registration, which is an easier problem as consecutive video frames are typically nearly identical, we employ a light off-the-shelf optical flow model. We demonstrate that GoTrack can be seamlessly combined with existing coarse pose estimation methods to create a minimal pipeline that reaches state-of-the-art RGB-only results on standard benchmarks for 6DoF object pose estimation and tracking. Our source code and trained models are publicly available at https://github.com/facebookresearch/gotrack
FoundPose: Unseen Object Pose Estimation with Foundation Features
Nov 30, 2023



We propose FoundPose, a method for 6D pose estimation of unseen rigid objects from a single RGB image. The method assumes that 3D models of the objects are available but does not require any object-specific training. This is achieved by building upon DINOv2, a recent vision foundation model with impressive generalization capabilities. An online pose estimation stage is supported by a minimal object representation that is built during a short onboarding stage from DINOv2 patch features extracted from rendered object templates. Given a query image with an object segmentation mask, FoundPose first rapidly retrieves a handful of similarly looking templates by a DINOv2-based bag-of-words approach. Pose hypotheses are then generated from 2D-3D correspondences established by matching DINOv2 patch features between the query image and a retrieved template, and finally optimized by featuremetric refinement. The method can handle diverse objects, including challenging ones with symmetries and without any texture, and noticeably outperforms existing RGB methods for coarse pose estimation in both accuracy and speed on the standard BOP benchmark. With the featuremetric and additional MegaPose refinement, which are demonstrated complementary, the method outperforms all RGB competitors. Source code is at: evinpinar.github.io/foundpose.
Instant Visual Odometry Initialization for Mobile AR
Jul 30, 2021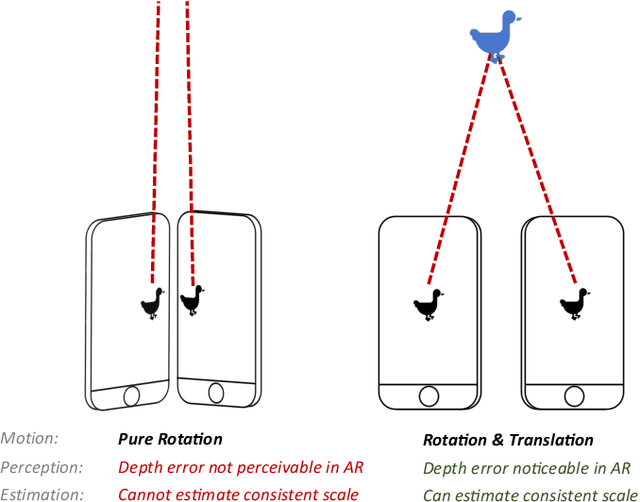
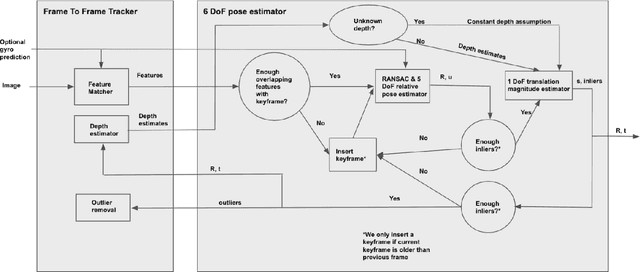
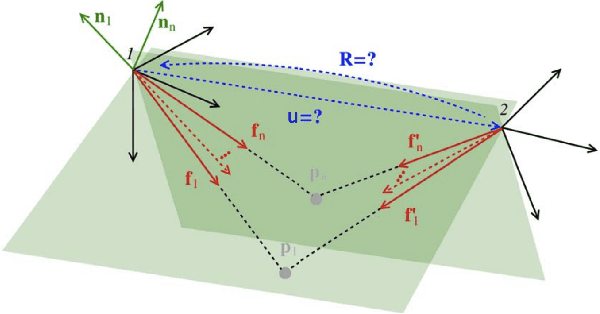
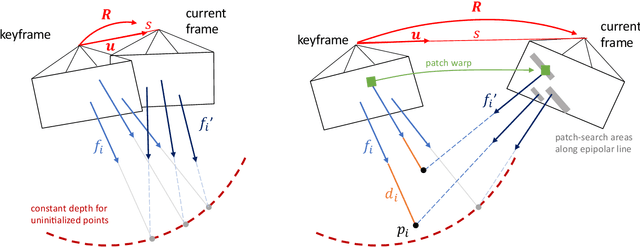
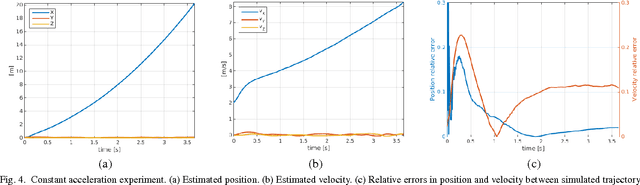
Mobile AR applications benefit from fast initialization to display world-locked effects instantly. However, standard visual odometry or SLAM algorithms require motion parallax to initialize (see Figure 1) and, therefore, suffer from delayed initialization. In this paper, we present a 6-DoF monocular visual odometry that initializes instantly and without motion parallax. Our main contribution is a pose estimator that decouples estimating the 5-DoF relative rotation and translation direction from the 1-DoF translation magnitude. While scale is not observable in a monocular vision-only setting, it is still paramount to estimate a consistent scale over the whole trajectory (even if not physically accurate) to avoid AR effects moving erroneously along depth. In our approach, we leverage the fact that depth errors are not perceivable to the user during rotation-only motion. However, as the user starts translating the device, depth becomes perceivable and so does the capability to estimate consistent scale. Our proposed algorithm naturally transitions between these two modes. We perform extensive validations of our contributions with both a publicly available dataset and synthetic data. We show that the proposed pose estimator outperforms the classical approaches for 6-DoF pose estimation used in the literature in low-parallax configurations. We release a dataset for the relative pose problem using real data to facilitate the comparison with future solutions for the relative pose problem. Our solution is either used as a full odometry or as a preSLAM component of any supported SLAM system (ARKit, ARCore) in world-locked AR effects on platforms such as Instagram and Facebook.
Perception-aware Path Planning
Feb 10, 2017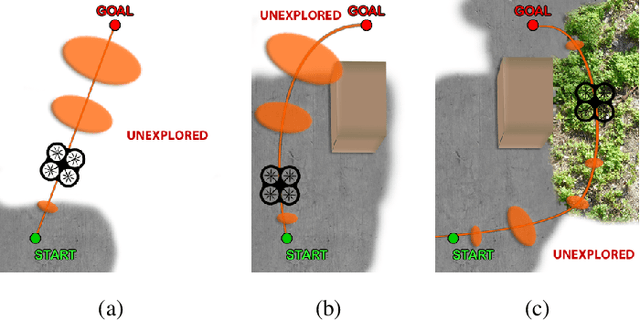
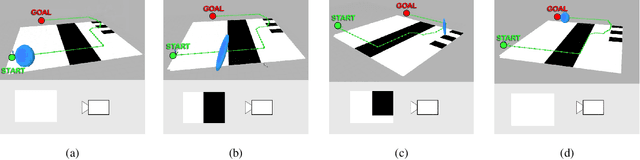


In this paper, we give a double twist to the problem of planning under uncertainty. State-of-the-art planners seek to minimize the localization uncertainty by only considering the geometric structure of the scene. In this paper, we argue that motion planning for vision-controlled robots should be perception aware in that the robot should also favor texture-rich areas to minimize the localization uncertainty during a goal-reaching task. Thus, we describe how to optimally incorporate the photometric information (i.e., texture) of the scene, in addition to the the geometric one, to compute the uncertainty of vision-based localization during path planning. To avoid the caveats of feature-based localization systems (i.e., dependence on feature type and user-defined thresholds), we use dense, direct methods. This allows us to compute the localization uncertainty directly from the intensity values of every pixel in the image. We also describe how to compute trajectories online, considering also scenarios with no prior knowledge about the map. The proposed framework is general and can easily be adapted to different robotic platforms and scenarios. The effectiveness of our approach is demonstrated with extensive experiments in both simulated and real-world environments using a vision-controlled micro aerial vehicle.
On-Manifold Preintegration for Real-Time Visual-Inertial Odometry
Oct 30, 2016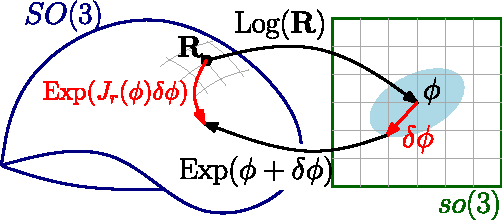
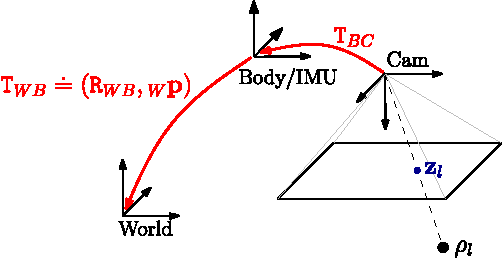
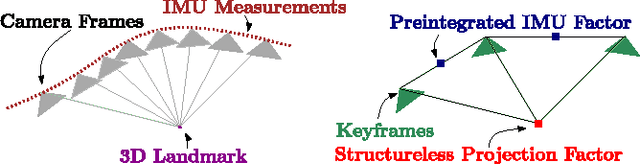
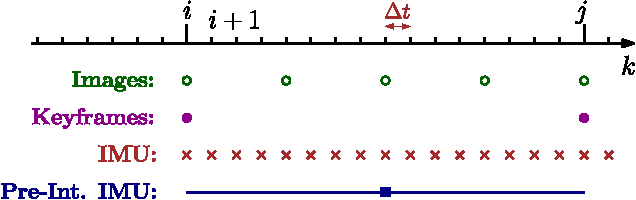
Current approaches for visual-inertial odometry (VIO) are able to attain highly accurate state estimation via nonlinear optimization. However, real-time optimization quickly becomes infeasible as the trajectory grows over time, this problem is further emphasized by the fact that inertial measurements come at high rate, hence leading to fast growth of the number of variables in the optimization. In this paper, we address this issue by preintegrating inertial measurements between selected keyframes into single relative motion constraints. Our first contribution is a \emph{preintegration theory} that properly addresses the manifold structure of the rotation group. We formally discuss the generative measurement model as well as the nature of the rotation noise and derive the expression for the \emph{maximum a posteriori} state estimator. Our theoretical development enables the computation of all necessary Jacobians for the optimization and a-posteriori bias correction in analytic form. The second contribution is to show that the preintegrated IMU model can be seamlessly integrated into a visual-inertial pipeline under the unifying framework of factor graphs. This enables the application of incremental-smoothing algorithms and the use of a \emph{structureless} model for visual measurements, which avoids optimizing over the 3D points, further accelerating the computation. We perform an extensive evaluation of our monocular \VIO pipeline on real and simulated datasets. The results confirm that our modelling effort leads to accurate state estimation in real-time, outperforming state-of-the-art approaches.
Event-based Camera Pose Tracking using a Generative Event Model
Oct 07, 2015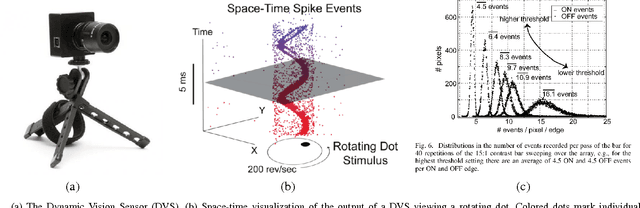
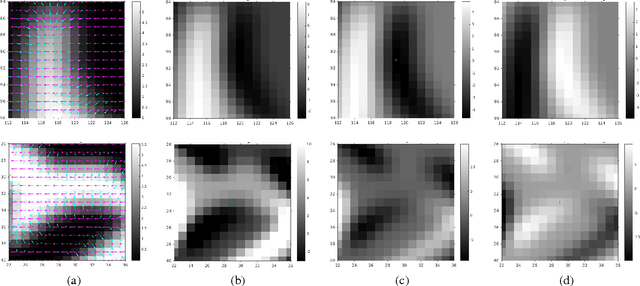
Event-based vision sensors mimic the operation of biological retina and they represent a major paradigm shift from traditional cameras. Instead of providing frames of intensity measurements synchronously, at artificially chosen rates, event-based cameras provide information on brightness changes asynchronously, when they occur. Such non-redundant pieces of information are called "events". These sensors overcome some of the limitations of traditional cameras (response time, bandwidth and dynamic range) but require new methods to deal with the data they output. We tackle the problem of event-based camera localization in a known environment, without additional sensing, using a probabilistic generative event model in a Bayesian filtering framework. Our main contribution is the design of the likelihood function used in the filter to process the observed events. Based on the physical characteristics of the sensor and on empirical evidence of the Gaussian-like distribution of spiked events with respect to the brightness change, we propose to use the contrast residual as a measure of how well the estimated pose of the event-based camera and the environment explain the observed events. The filter allows for localization in the general case of six degrees-of-freedom motions.