 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Illumination for Visual Ego-Motion Estimation in the Dark
Feb 19, 2025



Visual Odometry (VO) and Visual SLAM (V-SLAM) systems often struggle in low-light and dark environments due to the lack of robust visual features. In this paper, we propose a novel active illumination framework to enhance the performance of VO and V-SLAM algorithms in these challenging conditions. The developed approach dynamically controls a moving light source to illuminate highly textured areas, thereby improving feature extraction and tracking. Specifically, a detector block, which incorporates a deep learning-based enhancing network, identifies regions with relevant features. Then, a pan-tilt controller is responsible for guiding the light beam toward these areas, so that to provide information-rich images to the ego-motion estimation algorithm. Experimental results on a real robotic platform demonstrate the effectiveness of the proposed method, showing a reduction in the pose estimation error up to 75% with respect to a traditional fixed lighting technique.
The Power of Input: Benchmarking Zero-Shot Sim-To-Real Transfer of Reinforcement Learning Control Policies for Quadrotor Control
Oct 10, 2024



In the last decade, data-driven approaches have become popular choices for quadrotor control, thanks to their ability to facilitate the adaptation to unknown or uncertain flight conditions. Among the different data-driven paradigms, Deep Reinforcement Learning (DRL) is currently one of the most explored. However, the design of DRL agents for Micro Aerial Vehicles (MAVs) remains an open challenge. While some works have studied the output configuration of these agents (i.e., what kind of control to compute), there is no general consensus on the type of input data these approaches should employ. Multiple works simply provide the DRL agent with full state information, without questioning if this might be redundant and unnecessarily complicate the learning process, or pose superfluous constraints on the availability of such information in real platforms. In this work, we provide an in-depth benchmark analysis of different configurations of the observation space. We optimize multiple DRL agents in simulated environments with different input choices and study their robustness and their sim-to-real transfer capabilities with zero-shot adaptation. We believe that the outcomes and discussions presented in this work supported by extensive experimental results could be an important milestone in guiding future research on the development of DRL agents for aerial robot tasks.
Exploring Deep Reinforcement Learning for Robust Target Tracking using Micro Aerial Vehicles
Dec 29, 2023The capability to autonomously track a non-cooperative target is a key technological requirement for micro aerial vehicles. In this paper, we propose an output feedback control scheme based on deep reinforcement learning for controlling a micro aerial vehicle to persistently track a flying target while maintaining visual contact. The proposed method leverages relative position data for control, relaxing the assumption of having access to full state information which is typical of related approaches in literature. Moreover, we exploit classical robustness indicators in the learning process through domain randomization to increase the robustness of the learned policy. Experimental results validate the proposed approach for target tracking, demonstrating high performance and robustness with respect to mass mismatches and control delays. The resulting nonlinear controller significantly outperforms a standard model-based design in numerous off-nominal scenarios.
D-VAT: End-to-End Visual Active Tracking for Micro Aerial Vehicles
Aug 31, 2023



Visual active tracking is a growing research topic in robotics due to its key role in applications such as human assistance, disaster recovery, and surveillance. In contrast to passive tracking, active tracking approaches combine vision and control capabilities to detect and actively track the target. Most of the work in this area focuses on ground robots, while the very few contributions on aerial platforms still pose important design constraints that limit their applicability. To overcome these limitations, in this paper we propose D-VAT, a novel end-to-end visual active tracking methodology based on deep reinforcement learning that is tailored to micro aerial vehicle platforms. The D-VAT agent computes the vehicle thrust and angular velocity commands needed to track the target by directly processing monocular camera measurements. We show that the proposed approach allows for precise and collision-free tracking operations, outperforming different state-of-the-art baselines on simulated environments which differ significantly from those encountered during training.
GaPT: Gaussian Process Toolkit for Online Regression with Application to Learning Quadrotor Dynamics
Mar 14, 2023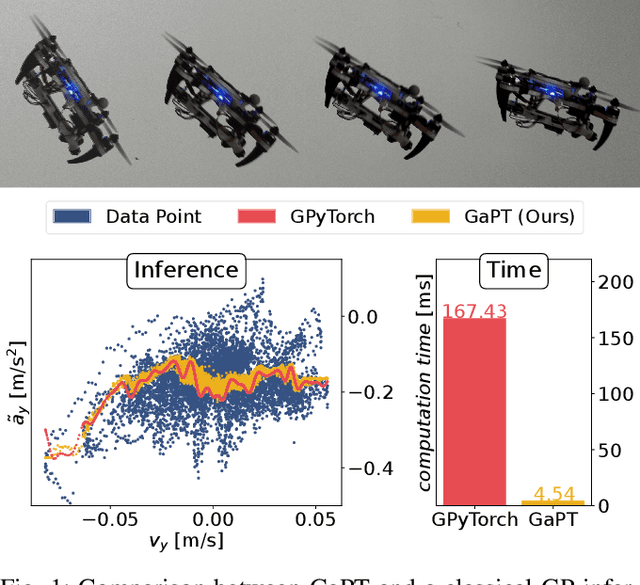
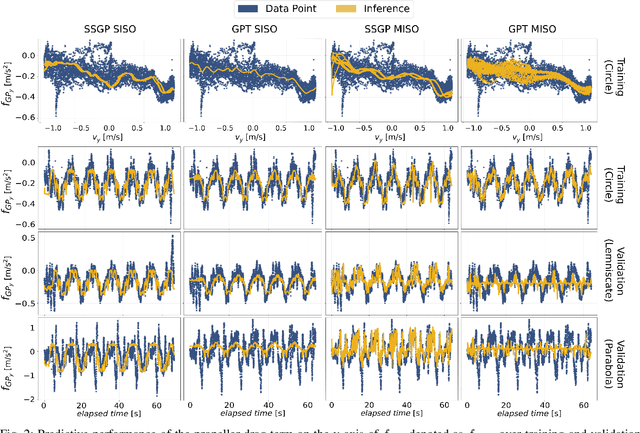
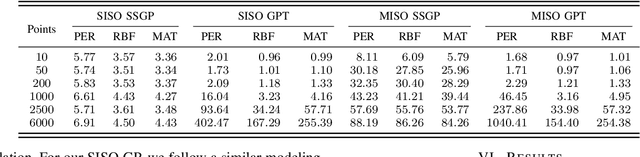
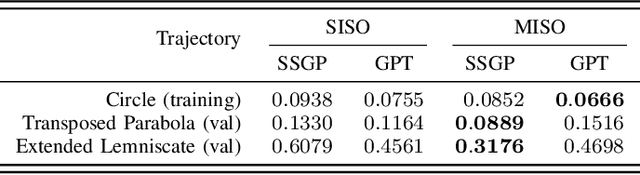
Gaussian Processes (GPs) are expressive models for capturing signal statistics and expressing prediction uncertainty. As a result, the robotics community has gathered interest in leveraging these methods for inference, planning, and control. Unfortunately, despite providing a closed-form inference solution, GPs are non-parametric models that typically scale cubically with the dataset size, hence making them difficult to be used especially on onboard Size, Weight, and Power (SWaP) constrained aerial robots. In addition, the integration of popular libraries with GPs for different kernels is not trivial. In this paper, we propose GaPT, a novel toolkit that converts GPs to their state space form and performs regression in linear time. GaPT is designed to be highly compatible with several optimizers popular in robotics. We thoroughly validate the proposed approach for learning quadrotor dynamics on both single and multiple input GP settings. GaPT accurately captures the system behavior in multiple flight regimes and operating conditions, including those producing highly nonlinear effects such as aerodynamic forces and rotor interactions. Moreover, the results demonstrate the superior computational performance of GaPT compared to a classical GP inference approach on both single and multi-input settings especially when considering large number of data points, enabling real-time regression speed on embedded platforms used on SWaP-constrained aerial robots.
Development of a Cooperative Localization System using a UWB Network and BLE Technology
Dec 13, 2022This paper presents the development of a system able to estimate the 2D relative position of nodes in a wireless network, based on distance measurements between the nodes. The system uses ultra wide band ranging technology and the Bluetooth Low Energy protocol to acquire data. Furthermore, a nonlinear least squares problem is formulated and solved numerically for estimating the relative positions of the nodes. The localization performance of the system is validated by experimental tests, demonstrating the capability of measuring the relative position of a network comprised of 4 nodes with an accuracy of the order of 3 cm and an update rate of 10 Hz. This shows the feasibility of applying the proposed system for multi-robot cooperative localization and formation control scenarios.
The Role of the Input in Natural Language Video Description
Feb 09, 2021
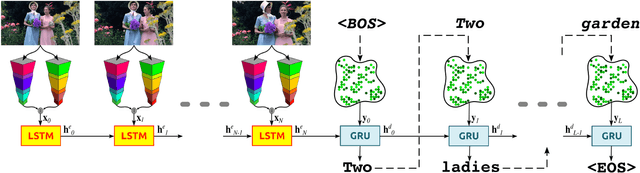


Natural Language Video Description (NLVD) has recently received strong interest in the Computer Vision, Natural Language Processing (NLP), Multimedia, and Autonomous Robotics communities. The State-of-the-Art (SotA) approaches obtained remarkable results when tested on the benchmark datasets. However, those approaches poorly generalize to new datasets. In addition, none of the existing works focus on the processing of the input to the NLVD systems, which is both visual and textual. In this work, it is presented an extensive study dealing with the role of the visual input, evaluated with respect to the overall NLP performance. This is achieved performing data augmentation of the visual component, applying common transformations to model camera distortions, noise, lighting, and camera positioning, that are typical in real-world operative scenarios. A t-SNE based analysis is proposed to evaluate the effects of the considered transformations on the overall visual data distribution. For this study, it is considered the English subset of Microsoft Research Video Description (MSVD) dataset, which is used commonly for NLVD. It was observed that this dataset contains a relevant amount of syntactic and semantic errors. These errors have been amended manually, and the new version of the dataset (called MSVD-v2) is used in the experimentation. The MSVD-v2 dataset is released to help to gain insight into the NLVD problem.
* In IEEE Transactions on Multimedia
Enhancing Continuous Control of Mobile Robots for End-to-End Visual Active Tracking
Sep 28, 2020

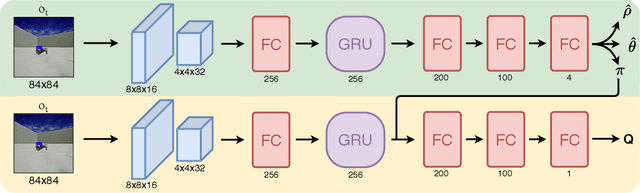

In the last decades, visual target tracking has been one of the primary research interests of the Robotics research community. The recent advances in Deep Learning technologies have made the exploitation of visual tracking approaches effective and possible in a wide variety of applications, ranging from automotive to surveillance and human assistance. However, the majority of the existing works focus exclusively on passive visual tracking, i.e., tracking elements in sequences of images by assuming that no actions can be taken to adapt the camera position to the motion of the tracked entity. On the contrary, in this work, we address visual active tracking, in which the tracker has to actively search for and track a specified target. Current State-of-the-Art approaches use Deep Reinforcement Learning (DRL) techniques to address the problem in an end-to-end manner. However, two main problems arise: i) most of the contributions focus only on discrete action spaces and the ones that consider continuous control do not achieve the same level of performance; and ii) if not properly tuned, DRL models can be challenging to train, resulting in a considerably slow learning progress and poor final performance. To address these challenges, we propose a novel DRL-based visual active tracking system that provides continuous action policies. To accelerate training and improve the overall performance, we introduce additional objective functions and a Heuristic Trajectory Generator (HTG) to facilitate learning. Through an extensive experimentation, we show that our method can reach and surpass other State-of-the-Art approaches performances, and demonstrate that, even if trained exclusively in simulation, it can successfully perform visual active tracking even in real scenarios.
Towards Monocular Digital Elevation Model (DEM) Estimation by Convolutional Neural Networks - Application on Synthetic Aperture Radar Images
Mar 14, 2018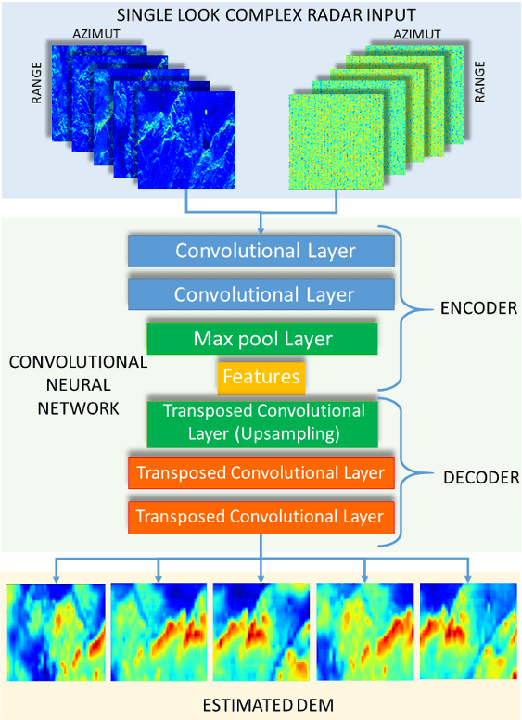
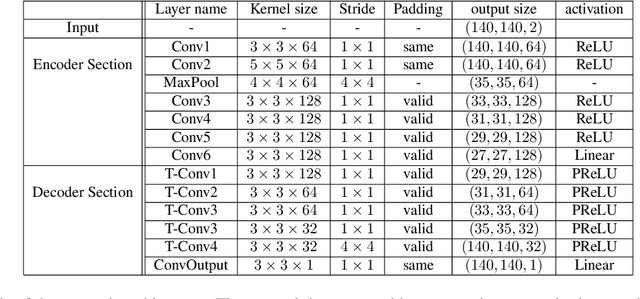
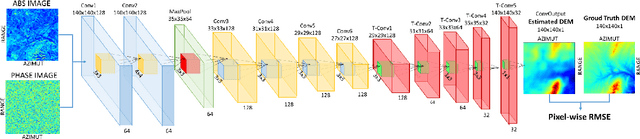

Synthetic aperture radar (SAR) interferometry (InSAR) is performed using repeat-pass geometry. InSAR technique is used to estimate the topographic reconstruction of the earth surface. The main problem of the range-Doppler focusing technique is the nature of the two-dimensional SAR result, affected by the layover indetermination. In order to resolve this problem, a minimum of two sensor acquisitions, separated by a baseline and extended in the cross-slant-range, are needed. However, given its multi-temporal nature, these techniques are vulnerable to atmosphere and Earth environment parameters variation in addition to physical platform instabilities. Furthermore, either two radars are needed or an interferometric cycle is required (that spans from days to weeks), which makes real time DEM estimation impossible. In this work, the authors propose a novel experimental alternative to the InSAR method that uses single-pass acquisitions, using a data driven approach implemented by Deep Neural Networks. We propose a fully Convolutional Neural Network (CNN) Encoder-Decoder architecture, training it on radar images in order to estimate DEMs from single pass image acquisitions. Our results on a set of Sentinel images show that this method is able to learn to some extent the statistical properties of the DEM. The results of this exploratory analysis are encouraging and open the way to the solution of single-pass DEM estimation problem with data driven approaches.
J-MOD$^{2}$: Joint Monocular Obstacle Detection and Depth Estimation
Dec 13, 2017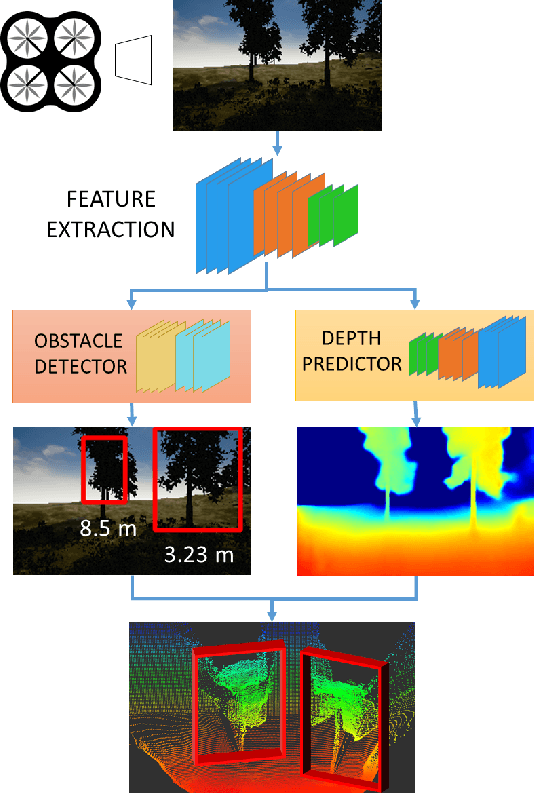
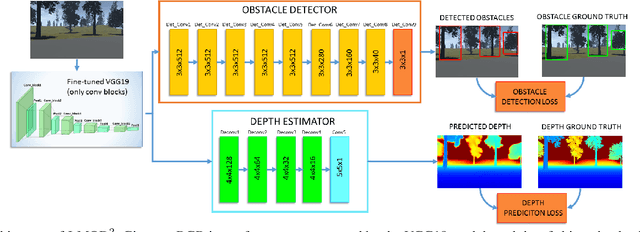
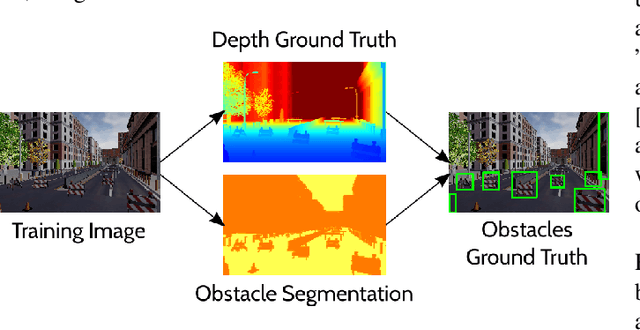
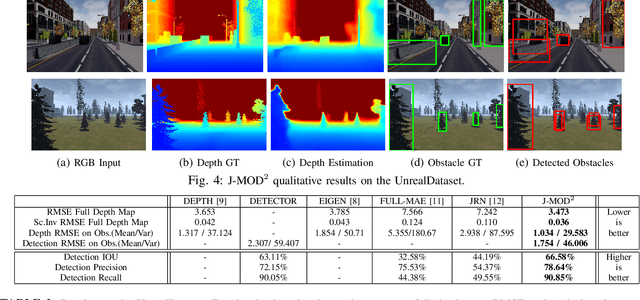
In this work, we propose an end-to-end deep architecture that jointly learns to detect obstacles and estimate their depth for MAV flight applications. Most of the existing approaches either rely on Visual SLAM systems or on depth estimation models to build 3D maps and detect obstacles. However, for the task of avoiding obstacles this level of complexity is not required. Recent works have proposed multi task architectures to both perform scene understanding and depth estimation. We follow their track and propose a specific architecture to jointly estimate depth and obstacles, without the need to compute a global map, but maintaining compatibility with a global SLAM system if needed. The network architecture is devised to exploit the joint information of the obstacle detection task, that produces more reliable bounding boxes, with the depth estimation one, increasing the robustness of both to scenario changes. We call this architecture J-MOD$^{2}$. We test the effectiveness of our approach with experiments on sequences with different appearance and focal lengths and compare it to SotA multi task methods that jointly perform semantic segmentation and depth estimation. In addition, we show the integration in a full system using a set of simulated navigation experiments where a MAV explores an unknown scenario and plans safe trajectories by using our detection model.