 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Illumination for Visual Ego-Motion Estimation in the Dark
Feb 19, 2025



Visual Odometry (VO) and Visual SLAM (V-SLAM) systems often struggle in low-light and dark environments due to the lack of robust visual features. In this paper, we propose a novel active illumination framework to enhance the performance of VO and V-SLAM algorithms in these challenging conditions. The developed approach dynamically controls a moving light source to illuminate highly textured areas, thereby improving feature extraction and tracking. Specifically, a detector block, which incorporates a deep learning-based enhancing network, identifies regions with relevant features. Then, a pan-tilt controller is responsible for guiding the light beam toward these areas, so that to provide information-rich images to the ego-motion estimation algorithm. Experimental results on a real robotic platform demonstrate the effectiveness of the proposed method, showing a reduction in the pose estimation error up to 75% with respect to a traditional fixed lighting technique.
The Role of the Input in Natural Language Video Description
Feb 09, 2021
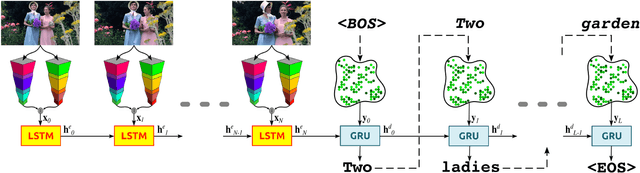


Natural Language Video Description (NLVD) has recently received strong interest in the Computer Vision, Natural Language Processing (NLP), Multimedia, and Autonomous Robotics communities. The State-of-the-Art (SotA) approaches obtained remarkable results when tested on the benchmark datasets. However, those approaches poorly generalize to new datasets. In addition, none of the existing works focus on the processing of the input to the NLVD systems, which is both visual and textual. In this work, it is presented an extensive study dealing with the role of the visual input, evaluated with respect to the overall NLP performance. This is achieved performing data augmentation of the visual component, applying common transformations to model camera distortions, noise, lighting, and camera positioning, that are typical in real-world operative scenarios. A t-SNE based analysis is proposed to evaluate the effects of the considered transformations on the overall visual data distribution. For this study, it is considered the English subset of Microsoft Research Video Description (MSVD) dataset, which is used commonly for NLVD. It was observed that this dataset contains a relevant amount of syntactic and semantic errors. These errors have been amended manually, and the new version of the dataset (called MSVD-v2) is used in the experimentation. The MSVD-v2 dataset is released to help to gain insight into the NLVD problem.
* In IEEE Transactions on Multimedia
J-MOD$^{2}$: Joint Monocular Obstacle Detection and Depth Estimation
Dec 13, 2017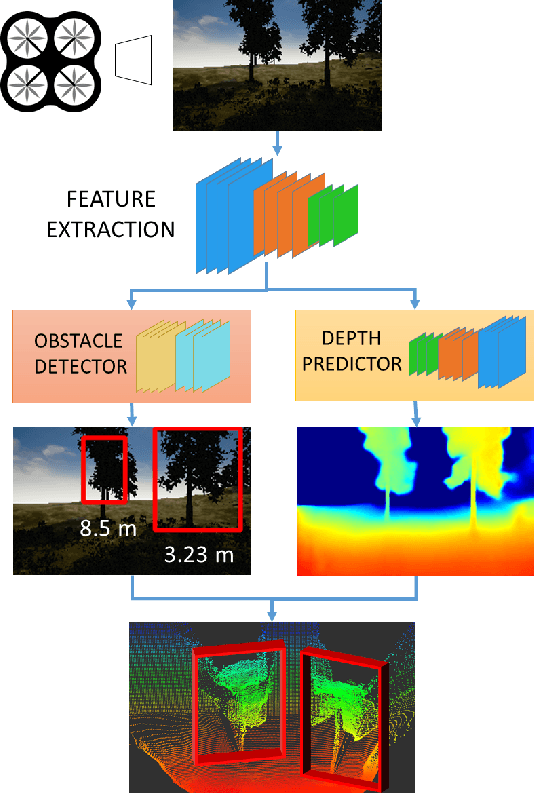
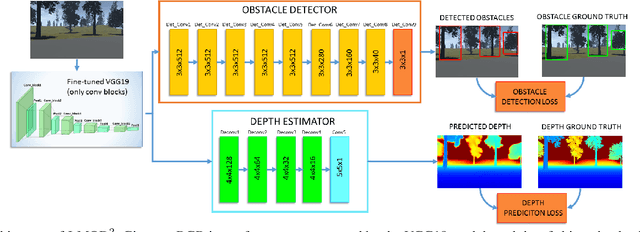
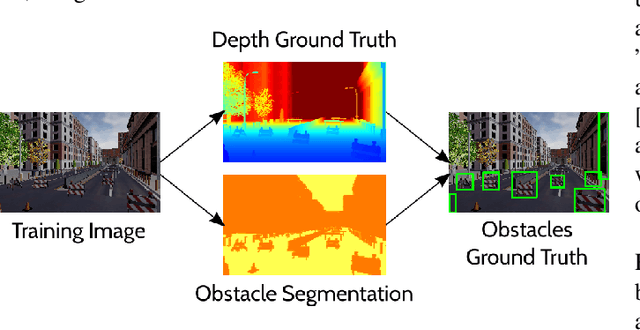
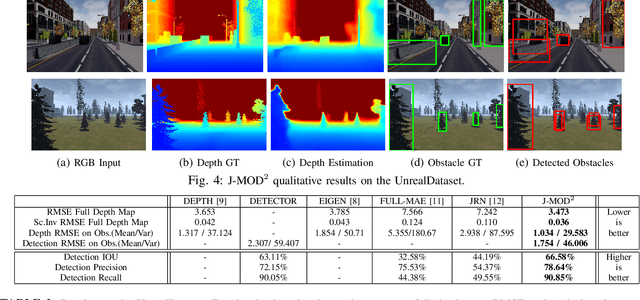
In this work, we propose an end-to-end deep architecture that jointly learns to detect obstacles and estimate their depth for MAV flight applications. Most of the existing approaches either rely on Visual SLAM systems or on depth estimation models to build 3D maps and detect obstacles. However, for the task of avoiding obstacles this level of complexity is not required. Recent works have proposed multi task architectures to both perform scene understanding and depth estimation. We follow their track and propose a specific architecture to jointly estimate depth and obstacles, without the need to compute a global map, but maintaining compatibility with a global SLAM system if needed. The network architecture is devised to exploit the joint information of the obstacle detection task, that produces more reliable bounding boxes, with the depth estimation one, increasing the robustness of both to scenario changes. We call this architecture J-MOD$^{2}$. We test the effectiveness of our approach with experiments on sequences with different appearance and focal lengths and compare it to SotA multi task methods that jointly perform semantic segmentation and depth estimation. In addition, we show the integration in a full system using a set of simulated navigation experiments where a MAV explores an unknown scenario and plans safe trajectories by using our detection model.
Perception-aware Path Planning
Feb 10, 2017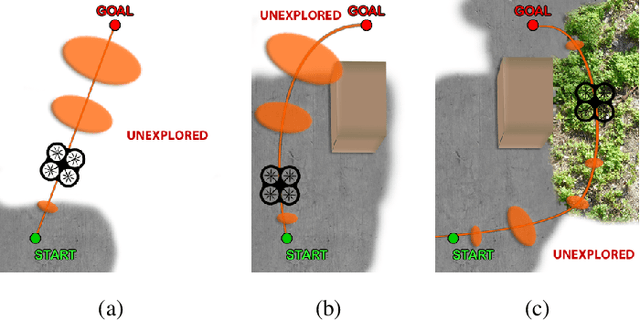
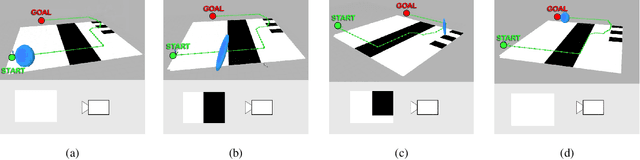


In this paper, we give a double twist to the problem of planning under uncertainty. State-of-the-art planners seek to minimize the localization uncertainty by only considering the geometric structure of the scene. In this paper, we argue that motion planning for vision-controlled robots should be perception aware in that the robot should also favor texture-rich areas to minimize the localization uncertainty during a goal-reaching task. Thus, we describe how to optimally incorporate the photometric information (i.e., texture) of the scene, in addition to the the geometric one, to compute the uncertainty of vision-based localization during path planning. To avoid the caveats of feature-based localization systems (i.e., dependence on feature type and user-defined thresholds), we use dense, direct methods. This allows us to compute the localization uncertainty directly from the intensity values of every pixel in the image. We also describe how to compute trajectories online, considering also scenarios with no prior knowledge about the map. The proposed framework is general and can easily be adapted to different robotic platforms and scenarios. The effectiveness of our approach is demonstrated with extensive experiments in both simulated and real-world environments using a vision-controlled micro aerial vehicle.
Fast Robust Monocular Depth Estimation for Obstacle Detection with Fully Convolutional Networks
Jul 21, 2016
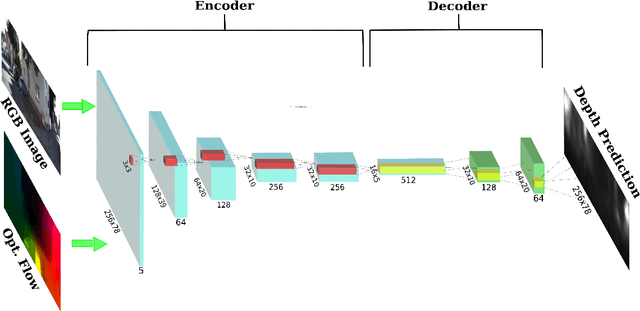


Obstacle Detection is a central problem for any robotic system, and critical for autonomous systems that travel at high speeds in unpredictable environment. This is often achieved through scene depth estimation, by various means. When fast motion is considered, the detection range must be longer enough to allow for safe avoidance and path planning. Current solutions often make assumption on the motion of the vehicle that limit their applicability, or work at very limited ranges due to intrinsic constraints. We propose a novel appearance-based Object Detection system that is able to detect obstacles at very long range and at a very high speed (~300Hz), without making assumptions on the type of motion. We achieve these results using a Deep Neural Network approach trained on real and synthetic images and trading some depth accuracy for fast, robust and consistent operation. We show how photo-realistic synthetic images are able to solve the problem of training set dimension and variety typical of machine learning approaches, and how our system is robust to massive blurring of test images.