 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Orthogonal Guidance for Robust Diffusion-based Handwritten Text Generation
Aug 23, 2025Diffusion-based Handwritten Text Generation (HTG) approaches achieve impressive results on frequent, in-vocabulary words observed at training time and on regular styles. However, they are prone to memorizing training samples and often struggle with style variability and generation clarity. In particular, standard diffusion models tend to produce artifacts or distortions that negatively affect the readability of the generated text, especially when the style is hard to produce. To tackle these issues, we propose a novel sampling guidance strategy, Dual Orthogonal Guidance (DOG), that leverages an orthogonal projection of a negatively perturbed prompt onto the original positive prompt. This approach helps steer the generation away from artifacts while maintaining the intended content, and encourages more diverse, yet plausible, outputs. Unlike standard Classifier-Free Guidance (CFG), which relies on unconditional predictions and produces noise at high guidance scales, DOG introduces a more stable, disentangled direction in the latent space. To control the strength of the guidance across the denoising process, we apply a triangular schedule: weak at the start and end of denoising, when the process is most sensitive, and strongest in the middle steps. Experimental results on the state-of-the-art DiffusionPen and One-DM demonstrate that DOG improves both content clarity and style variability, even for out-of-vocabulary words and challenging writing styles.
Quo Vadis Handwritten Text Generation for Handwritten Text Recognition?
Aug 13, 2025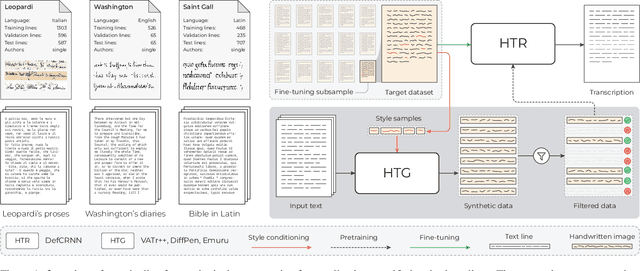
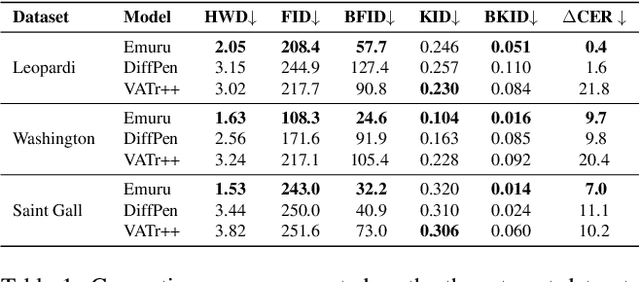

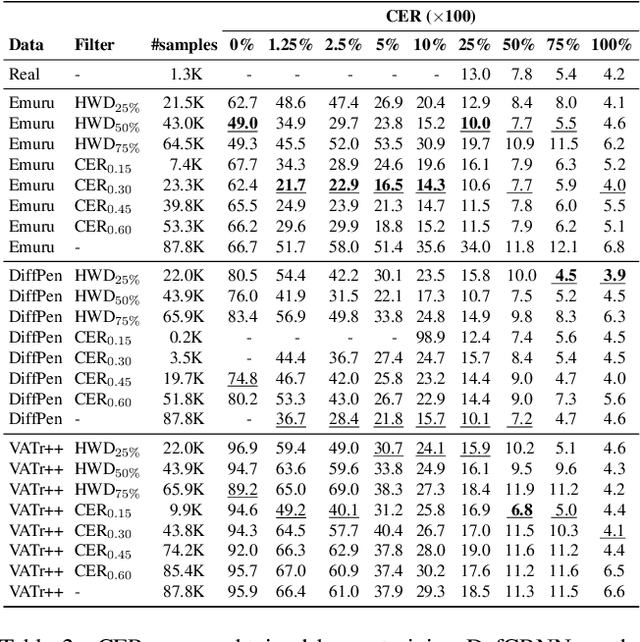
The digitization of historical manuscripts presents significant challenges for Handwritten Text Recognition (HTR) systems, particularly when dealing with small, author-specific collections that diverge from the training data distributions. Handwritten Text Generation (HTG) techniques, which generate synthetic data tailored to specific handwriting styles, offer a promising solution to address these challenges. However, the effectiveness of various HTG models in enhancing HTR performance, especially in low-resource transcription settings, has not been thoroughly evaluated. In this work, we systematically compare three state-of-the-art styled HTG models (representing the generative adversarial, diffusion, and autoregressive paradigms for HTG) to assess their impact on HTR fine-tuning. We analyze how visual and linguistic characteristics of synthetic data influence fine-tuning outcomes and provide quantitative guidelines for selecting the most effective HTG model. The results of our analysis provide insights into the current capabilities of HTG methods and highlight key areas for further improvement in their application to low-resource HTR.
ToFu: Visual Tokens Reduction via Fusion for Multi-modal, Multi-patch, Multi-image Task
Mar 06, 2025



Large Multimodal Models (LMMs) are powerful tools that are capable of reasoning and understanding multimodal information beyond text and language. Despite their entrenched impact, the development of LMMs is hindered by the higher computational requirements compared to their unimodal counterparts. One of the main causes of this is the large amount of tokens needed to encode the visual input, which is especially evident for multi-image multimodal tasks. Recent approaches to reduce visual tokens depend on the visual encoder architecture, require fine-tuning the LLM to maintain the performance, and only consider single-image scenarios. To address these limitations, we propose ToFu, a visual encoder-agnostic, training-free Token Fusion strategy that combines redundant visual tokens of LMMs for high-resolution, multi-image, tasks. The core intuition behind our method is straightforward yet effective: preserve distinctive tokens while combining similar ones. We achieve this by sequentially examining visual tokens and deciding whether to merge them with others or keep them as separate entities. We validate our approach on the well-established LLaVA-Interleave Bench, which covers challenging multi-image tasks. In addition, we push to the extreme our method by testing it on a newly-created benchmark, ComPairs, focused on multi-image comparisons where a larger amount of images and visual tokens are inputted to the LMMs. Our extensive analysis, considering several LMM architectures, demonstrates the benefits of our approach both in terms of efficiency and performance gain.
μgat: Improving Single-Page Document Parsing by Providing Multi-Page Context
Aug 28, 2024



Regesta are catalogs of summaries of other documents and, in some cases, are the only source of information about the content of such full-length documents. For this reason, they are of great interest to scholars in many social and humanities fields. In this work, we focus on Regesta Pontificum Romanum, a large collection of papal registers. Regesta are visually rich documents, where the layout is as important as the text content to convey the contained information through the structure, and are inherently multi-page documents. Among Digital Humanities techniques that can help scholars efficiently exploit regesta and other documental sources in the form of scanned documents, Document Parsing has emerged as a task to process document images and convert them into machine-readable structured representations, usually markup language. However, current models focus on scientific and business documents, and most of them consider only single-paged documents. To overcome this limitation, in this work, we propose {\mu}gat, an extension of the recently proposed Document parsing Nougat architecture, which can handle elements spanning over the single page limits. Specifically, we adapt Nougat to process a larger, multi-page context, consisting of the previous and the following page, while parsing the current page. Experimental results, both qualitative and quantitative, demonstrate the effectiveness of our proposed approach also in the case of the challenging Regesta Pontificum Romanorum.
Merging and Splitting Diffusion Paths for Semantically Coherent Panoramas
Aug 28, 2024



Diffusion models have become the State-of-the-Art for text-to-image generation, and increasing research effort has been dedicated to adapting the inference process of pretrained diffusion models to achieve zero-shot capabilities. An example is the generation of panorama images, which has been tackled in recent works by combining independent diffusion paths over overlapping latent features, which is referred to as joint diffusion, obtaining perceptually aligned panoramas. However, these methods often yield semantically incoherent outputs and trade-off diversity for uniformity. To overcome this limitation, we propose the Merge-Attend-Diffuse operator, which can be plugged into different types of pretrained diffusion models used in a joint diffusion setting to improve the perceptual and semantical coherence of the generated panorama images. Specifically, we merge the diffusion paths, reprogramming self- and cross-attention to operate on the aggregated latent space. Extensive quantitative and qualitative experimental analysis, together with a user study, demonstrate that our method maintains compatibility with the input prompt and visual quality of the generated images while increasing their semantic coherence. We release the code at https://github.com/aimagelab/MAD.
Alfie: Democratising RGBA Image Generation With No $$$
Aug 27, 2024


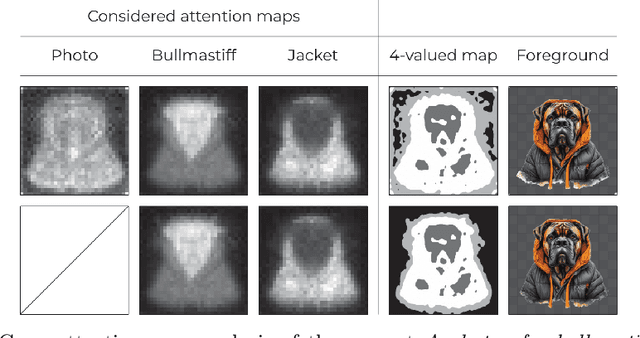
Designs and artworks are ubiquitous across various creative fields, requiring graphic design skills and dedicated software to create compositions that include many graphical elements, such as logos, icons, symbols, and art scenes, which are integral to visual storytelling. Automating the generation of such visual elements improves graphic designers' productivity, democratizes and innovates the creative industry, and helps generate more realistic synthetic data for related tasks. These illustration elements are mostly RGBA images with irregular shapes and cutouts, facilitating blending and scene composition. However, most image generation models are incapable of generating such images and achieving this capability requires expensive computational resources, specific training recipes, or post-processing solutions. In this work, we propose a fully-automated approach for obtaining RGBA illustrations by modifying the inference-time behavior of a pre-trained Diffusion Transformer model, exploiting the prompt-guided controllability and visual quality offered by such models with no additional computational cost. We force the generation of entire subjects without sharp croppings, whose background is easily removed for seamless integration into design projects or artistic scenes. We show with a user study that, in most cases, users prefer our solution over generating and then matting an image, and we show that our generated illustrations yield good results when used as inputs for composite scene generation pipelines. We release the code at https://github.com/aimagelab/Alfie.
Binarizing Documents by Leveraging both Space and Frequency
Apr 26, 2024Document Image Binarization is a well-known problem in Document Analysis and Computer Vision, although it is far from being solved. One of the main challenges of this task is that documents generally exhibit degradations and acquisition artifacts that can greatly vary throughout the page. Nonetheless, even when dealing with a local patch of the document, taking into account the overall appearance of a wide portion of the page can ease the prediction by enriching it with semantic information on the ink and background conditions. In this respect, approaches able to model both local and global information have been proven suitable for this task. In particular, recent applications of Vision Transformer (ViT)-based models, able to model short and long-range dependencies via the attention mechanism, have demonstrated their superiority over standard Convolution-based models, which instead struggle to model global dependencies. In this work, we propose an alternative solution based on the recently introduced Fast Fourier Convolutions, which overcomes the limitation of standard convolutions in modeling global information while requiring fewer parameters than ViTs. We validate the effectiveness of our approach via extensive experimental analysis considering different types of degradations.
VATr++: Choose Your Words Wisely for Handwritten Text Generation
Feb 16, 2024Styled Handwritten Text Generation (HTG) has received significant attention in recent years, propelled by the success of learning-based solutions employing GANs, Transformers, and, preliminarily, Diffusion Models. Despite this surge in interest, there remains a critical yet understudied aspect - the impact of the input, both visual and textual, on the HTG model training and its subsequent influence on performance. This study delves deeper into a cutting-edge Styled-HTG approach, proposing strategies for input preparation and training regularization that allow the model to achieve better performance and generalize better. These aspects are validated through extensive analysis on several different settings and datasets. Moreover, in this work, we go beyond performance optimization and address a significant hurdle in HTG research - the lack of a standardized evaluation protocol. In particular, we propose a standardization of the evaluation protocol for HTG and conduct a comprehensive benchmarking of existing approaches. By doing so, we aim to establish a foundation for fair and meaningful comparisons between HTG strategies, fostering progress in the field.
HWD: A Novel Evaluation Score for Styled Handwritten Text Generation
Oct 31, 2023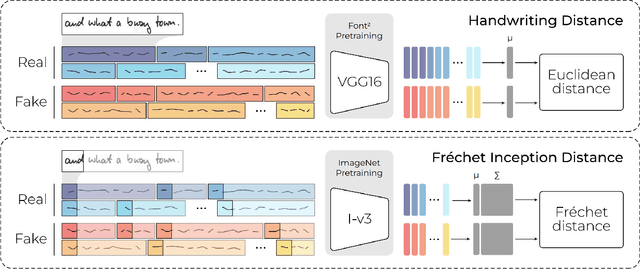

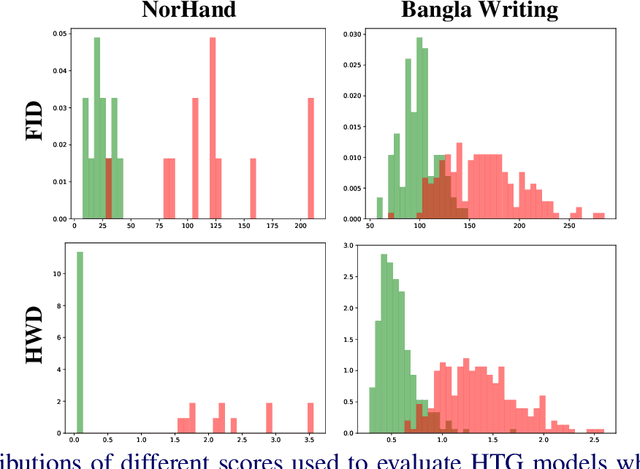

Styled Handwritten Text Generation (Styled HTG) is an important task in document analysis, aiming to generate text images with the handwriting of given reference images. In recent years, there has been significant progress in the development of deep learning models for tackling this task. Being able to measure the performance of HTG models via a meaningful and representative criterion is key for fostering the development of this research topic. However, despite the current adoption of scores for natural image generation evaluation, assessing the quality of generated handwriting remains challenging. In light of this, we devise the Handwriting Distance (HWD), tailored for HTG evaluation. In particular, it works in the feature space of a network specifically trained to extract handwriting style features from the variable-lenght input images and exploits a perceptual distance to compare the subtle geometric features of handwriting. Through extensive experimental evaluation on different word-level and line-level datasets of handwritten text images, we demonstrate the suitability of the proposed HWD as a score for Styled HTG. The pretrained model used as backbone will be released to ease the adoption of the score, aiming to provide a valuable tool for evaluating HTG models and thus contributing to advancing this important research area.
Volumetric Fast Fourier Convolution for Detecting Ink on the Carbonized Herculaneum Papyri
Aug 09, 2023



Recent advancements in Digital Document Restoration (DDR) have led to significant breakthroughs in analyzing highly damaged written artifacts. Among those, there has been an increasing interest in applying Artificial Intelligence techniques for virtually unwrapping and automatically detecting ink on the Herculaneum papyri collection. This collection consists of carbonized scrolls and fragments of documents, which have been digitized via X-ray tomography to allow the development of ad-hoc deep learning-based DDR solutions. In this work, we propose a modification of the Fast Fourier Convolution operator for volumetric data and apply it in a segmentation architecture for ink detection on the challenging Herculaneum papyri, demonstrating its suitability via deep experimental analysis. To encourage the research on this task and the application of the proposed operator to other tasks involving volumetric data, we will release our implementation (https://github.com/aimagelab/vffc)