 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlfie: Democratising RGBA Image Generation With No $$$
Paper and Code



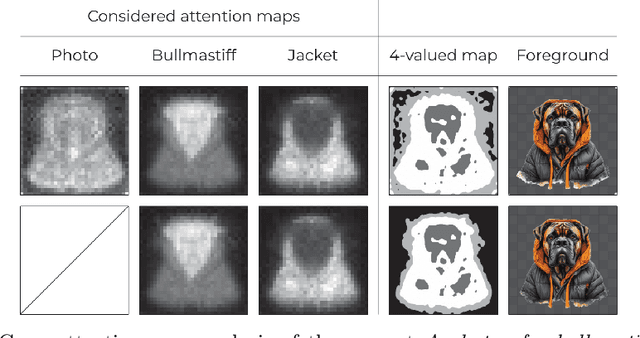
Designs and artworks are ubiquitous across various creative fields, requiring graphic design skills and dedicated software to create compositions that include many graphical elements, such as logos, icons, symbols, and art scenes, which are integral to visual storytelling. Automating the generation of such visual elements improves graphic designers' productivity, democratizes and innovates the creative industry, and helps generate more realistic synthetic data for related tasks. These illustration elements are mostly RGBA images with irregular shapes and cutouts, facilitating blending and scene composition. However, most image generation models are incapable of generating such images and achieving this capability requires expensive computational resources, specific training recipes, or post-processing solutions. In this work, we propose a fully-automated approach for obtaining RGBA illustrations by modifying the inference-time behavior of a pre-trained Diffusion Transformer model, exploiting the prompt-guided controllability and visual quality offered by such models with no additional computational cost. We force the generation of entire subjects without sharp croppings, whose background is easily removed for seamless integration into design projects or artistic scenes. We show with a user study that, in most cases, users prefer our solution over generating and then matting an image, and we show that our generated illustrations yield good results when used as inputs for composite scene generation pipelines. We release the code at https://github.com/aimagelab/Alfie.