 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCut-and-Splat: Leveraging Gaussian Splatting for Synthetic Data Generation
Apr 11, 2025



Generating synthetic images is a useful method for cheaply obtaining labeled data for training computer vision models. However, obtaining accurate 3D models of relevant objects is necessary, and the resulting images often have a gap in realism due to challenges in simulating lighting effects and camera artifacts. We propose using the novel view synthesis method called Gaussian Splatting to address these challenges. We have developed a synthetic data pipeline for generating high-quality context-aware instance segmentation training data for specific objects. This process is fully automated, requiring only a video of the target object. We train a Gaussian Splatting model of the target object and automatically extract the object from the video. Leveraging Gaussian Splatting, we then render the object on a random background image, and monocular depth estimation is employed to place the object in a believable pose. We introduce a novel dataset to validate our approach and show superior performance over other data generation approaches, such as Cut-and-Paste and Diffusion model-based generation.
Genetic Learning for Designing Sim-to-Real Data Augmentations
Mar 11, 2024Data augmentations are useful in closing the sim-to-real domain gap when training on synthetic data. This is because they widen the training data distribution, thus encouraging the model to generalize better to other domains. Many image augmentation techniques exist, parametrized by different settings, such as strength and probability. This leads to a large space of different possible augmentation policies. Some policies work better than others for overcoming the sim-to-real gap for specific datasets, and it is unclear why. This paper presents two different interpretable metrics that can be combined to predict how well a certain augmentation policy will work for a specific sim-to-real setting, focusing on object detection. We validate our metrics by training many models with different augmentation policies and showing a strong correlation with performance on real data. Additionally, we introduce GeneticAugment, a genetic programming method that can leverage these metrics to automatically design an augmentation policy for a specific dataset without needing to train a model.
VATr++: Choose Your Words Wisely for Handwritten Text Generation
Feb 16, 2024Styled Handwritten Text Generation (HTG) has received significant attention in recent years, propelled by the success of learning-based solutions employing GANs, Transformers, and, preliminarily, Diffusion Models. Despite this surge in interest, there remains a critical yet understudied aspect - the impact of the input, both visual and textual, on the HTG model training and its subsequent influence on performance. This study delves deeper into a cutting-edge Styled-HTG approach, proposing strategies for input preparation and training regularization that allow the model to achieve better performance and generalize better. These aspects are validated through extensive analysis on several different settings and datasets. Moreover, in this work, we go beyond performance optimization and address a significant hurdle in HTG research - the lack of a standardized evaluation protocol. In particular, we propose a standardization of the evaluation protocol for HTG and conduct a comprehensive benchmarking of existing approaches. By doing so, we aim to establish a foundation for fair and meaningful comparisons between HTG strategies, fostering progress in the field.
Analysis of Training Object Detection Models with Synthetic Data
Nov 29, 2022



Recently, the use of synthetic training data has been on the rise as it offers correctly labelled datasets at a lower cost. The downside of this technique is that the so-called domain gap between the real target images and synthetic training data leads to a decrease in performance. In this paper, we attempt to provide a holistic overview of how to use synthetic data for object detection. We analyse aspects of generating the data as well as techniques used to train the models. We do so by devising a number of experiments, training models on the Dataset of Industrial Metal Objects (DIMO). This dataset contains both real and synthetic images. The synthetic part has different subsets that are either exact synthetic copies of the real data or are copies with certain aspects randomised. This allows us to analyse what types of variation are good for synthetic training data and which aspects should be modelled to closely match the target data. Furthermore, we investigate what types of training techniques are beneficial towards generalisation to real data, and how to use them. Additionally, we analyse how real images can be leveraged when training on synthetic images. All these experiments are validated on real data and benchmarked to models trained on real data. The results offer a number of interesting takeaways that can serve as basic guidelines for using synthetic data for object detection. Code to reproduce results is available at https://github.com/EDM-Research/DIMO_ObjectDetection.
* published in BMVC 2022, https://bmvc2022.mpi-inf.mpg.de/833/
CAD2Render: A Modular Toolkit for GPU-accelerated Photorealistic Synthetic Data Generation for the Manufacturing Industry
Nov 25, 2022



The use of computer vision for product and assembly quality control is becoming ubiquitous in the manufacturing industry. Lately, it is apparent that machine learning based solutions are outperforming classical computer vision algorithms in terms of performance and robustness. However, a main drawback is that they require sufficiently large and labeled training datasets, which are often not available or too tedious and too time consuming to acquire. This is especially true for low-volume and high-variance manufacturing. Fortunately, in this industry, CAD models of the manufactured or assembled products are available. This paper introduces CAD2Render, a GPU-accelerated synthetic data generator based on the Unity High Definition Render Pipeline (HDRP). CAD2Render is designed to add variations in a modular fashion, making it possible for high customizable data generation, tailored to the needs of the industrial use case at hand. Although CAD2Render is specifically designed for manufacturing use cases, it can be used for other domains as well. We validate CAD2Render by demonstrating state of the art performance in two industrial relevant setups. We demonstrate that the data generated by our approach can be used to train object detection and pose estimation models with a high enough accuracy to direct a robot. The code for CAD2Render is available at https://github.com/EDM-Research/CAD2Render.
Automatic Camera Control and Directing with an Ultra-High-Definition Collaborative Recording System
Aug 10, 2022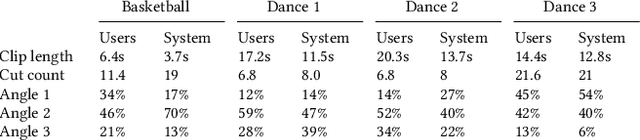

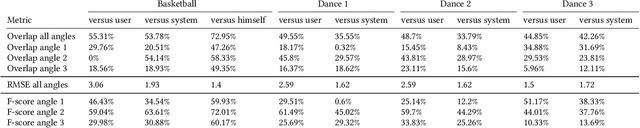

Capturing an event from multiple camera angles can give a viewer the most complete and interesting picture of that event. To be suitable for broadcasting, a human director needs to decide what to show at each point in time. This can become cumbersome with an increasing number of camera angles. The introduction of omnidirectional or wide-angle cameras has allowed for events to be captured more completely, making it even more difficult for the director to pick a good shot. In this paper, a system is presented that, given multiple ultra-high resolution video streams of an event, can generate a visually pleasing sequence of shots that manages to follow the relevant action of an event. Due to the algorithm being general purpose, it can be applied to most scenarios that feature humans. The proposed method allows for online processing when real-time broadcasting is required, as well as offline processing when the quality of the camera operation is the priority. Object detection is used to detect humans and other objects of interest in the input streams. Detected persons of interest, along with a set of rules based on cinematic conventions, are used to determine which video stream to show and what part of that stream is virtually framed. The user can provide a number of settings that determine how these rules are interpreted. The system is able to handle input from different wide-angle video streams by removing lens distortions. Using a user study it is shown, for a number of different scenarios, that the proposed automated director is able to capture an event with aesthetically pleasing video compositions and human-like shot switching behavior.