 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of 3D Model Acquisition Methods for Synthetic Data Generation of Agricultural Products
Jan 07, 2026In the manufacturing industry, computer vision systems based on artificial intelligence (AI) are widely used to reduce costs and increase production. Training these AI models requires a large amount of training data that is costly to acquire and annotate, especially in high-variance, low-volume manufacturing environments. A popular approach to reduce the need for real data is the use of synthetic data that is generated by leveraging computer-aided design (CAD) models available in the industry. However, in the agricultural industry these models are not readily available, increasing the difficulty in leveraging synthetic data. In this paper, we present different techniques for substituting CAD files to create synthetic datasets. We measure their relative performance when used to train an AI object detection model to separate stones and potatoes in a bin picking environment. We demonstrate that using highly representative 3D models acquired by scanning or using image-to-3D approaches can be used to generate synthetic data for training object detection models. Finetuning on a small real dataset can significantly improve the performance of the models and even get similar performance when less representative models are used.
Analysis of Training Object Detection Models with Synthetic Data
Nov 29, 2022



Recently, the use of synthetic training data has been on the rise as it offers correctly labelled datasets at a lower cost. The downside of this technique is that the so-called domain gap between the real target images and synthetic training data leads to a decrease in performance. In this paper, we attempt to provide a holistic overview of how to use synthetic data for object detection. We analyse aspects of generating the data as well as techniques used to train the models. We do so by devising a number of experiments, training models on the Dataset of Industrial Metal Objects (DIMO). This dataset contains both real and synthetic images. The synthetic part has different subsets that are either exact synthetic copies of the real data or are copies with certain aspects randomised. This allows us to analyse what types of variation are good for synthetic training data and which aspects should be modelled to closely match the target data. Furthermore, we investigate what types of training techniques are beneficial towards generalisation to real data, and how to use them. Additionally, we analyse how real images can be leveraged when training on synthetic images. All these experiments are validated on real data and benchmarked to models trained on real data. The results offer a number of interesting takeaways that can serve as basic guidelines for using synthetic data for object detection. Code to reproduce results is available at https://github.com/EDM-Research/DIMO_ObjectDetection.
* published in BMVC 2022, https://bmvc2022.mpi-inf.mpg.de/833/
CAD2Render: A Modular Toolkit for GPU-accelerated Photorealistic Synthetic Data Generation for the Manufacturing Industry
Nov 25, 2022The use of computer vision for product and assembly quality control is becoming ubiquitous in the manufacturing industry. Lately, it is apparent that machine learning based solutions are outperforming classical computer vision algorithms in terms of performance and robustness. However, a main drawback is that they require sufficiently large and labeled training datasets, which are often not available or too tedious and too time consuming to acquire. This is especially true for low-volume and high-variance manufacturing. Fortunately, in this industry, CAD models of the manufactured or assembled products are available. This paper introduces CAD2Render, a GPU-accelerated synthetic data generator based on the Unity High Definition Render Pipeline (HDRP). CAD2Render is designed to add variations in a modular fashion, making it possible for high customizable data generation, tailored to the needs of the industrial use case at hand. Although CAD2Render is specifically designed for manufacturing use cases, it can be used for other domains as well. We validate CAD2Render by demonstrating state of the art performance in two industrial relevant setups. We demonstrate that the data generated by our approach can be used to train object detection and pose estimation models with a high enough accuracy to direct a robot. The code for CAD2Render is available at https://github.com/EDM-Research/CAD2Render.
Dataset of Industrial Metal Objects
Aug 08, 2022


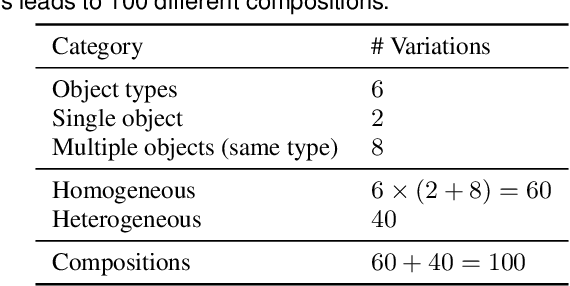
We present a diverse dataset of industrial metal objects. These objects are symmetric, textureless and highly reflective, leading to challenging conditions not captured in existing datasets. Our dataset contains both real-world and synthetic multi-view RGB images with 6D object pose labels. Real-world data is obtained by recording multi-view images of scenes with varying object shapes, materials, carriers, compositions and lighting conditions. This results in over 30,000 images, accurately labelled using a new public tool. Synthetic data is obtained by carefully simulating real-world conditions and varying them in a controlled and realistic way. This leads to over 500,000 synthetic images. The close correspondence between synthetic and real-world data, and controlled variations, will facilitate sim-to-real research. Our dataset's size and challenging nature will facilitate research on various computer vision tasks involving reflective materials. The dataset and accompanying resources are made available on the project website at https://pderoovere.github.io/dimo.