 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Orthogonal Guidance for Robust Diffusion-based Handwritten Text Generation
Aug 23, 2025Diffusion-based Handwritten Text Generation (HTG) approaches achieve impressive results on frequent, in-vocabulary words observed at training time and on regular styles. However, they are prone to memorizing training samples and often struggle with style variability and generation clarity. In particular, standard diffusion models tend to produce artifacts or distortions that negatively affect the readability of the generated text, especially when the style is hard to produce. To tackle these issues, we propose a novel sampling guidance strategy, Dual Orthogonal Guidance (DOG), that leverages an orthogonal projection of a negatively perturbed prompt onto the original positive prompt. This approach helps steer the generation away from artifacts while maintaining the intended content, and encourages more diverse, yet plausible, outputs. Unlike standard Classifier-Free Guidance (CFG), which relies on unconditional predictions and produces noise at high guidance scales, DOG introduces a more stable, disentangled direction in the latent space. To control the strength of the guidance across the denoising process, we apply a triangular schedule: weak at the start and end of denoising, when the process is most sensitive, and strongest in the middle steps. Experimental results on the state-of-the-art DiffusionPen and One-DM demonstrate that DOG improves both content clarity and style variability, even for out-of-vocabulary words and challenging writing styles.
Quo Vadis Handwritten Text Generation for Handwritten Text Recognition?
Aug 13, 2025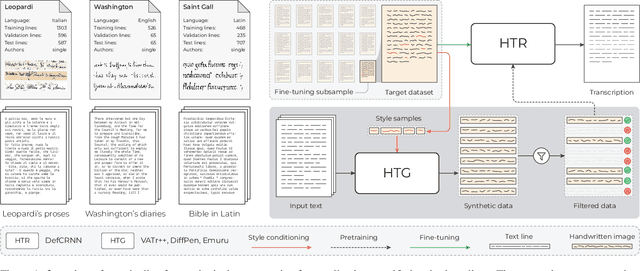
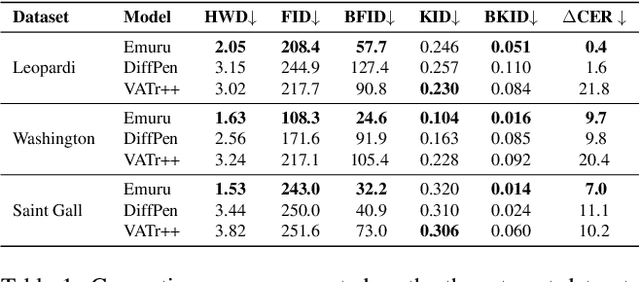

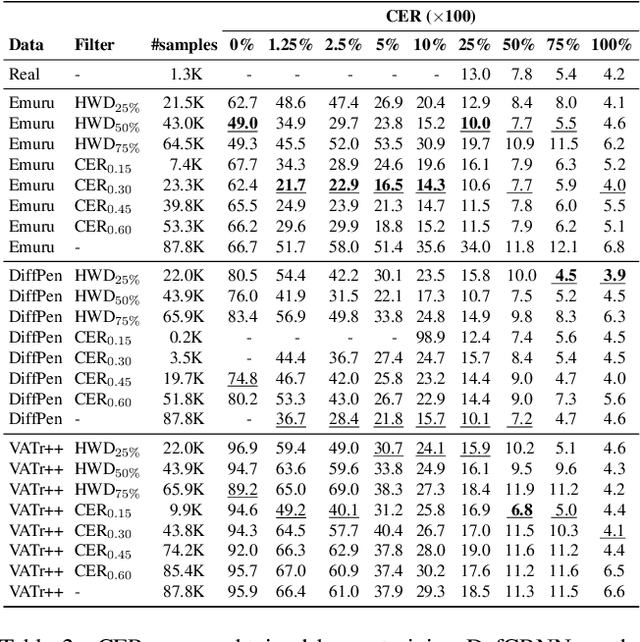
The digitization of historical manuscripts presents significant challenges for Handwritten Text Recognition (HTR) systems, particularly when dealing with small, author-specific collections that diverge from the training data distributions. Handwritten Text Generation (HTG) techniques, which generate synthetic data tailored to specific handwriting styles, offer a promising solution to address these challenges. However, the effectiveness of various HTG models in enhancing HTR performance, especially in low-resource transcription settings, has not been thoroughly evaluated. In this work, we systematically compare three state-of-the-art styled HTG models (representing the generative adversarial, diffusion, and autoregressive paradigms for HTG) to assess their impact on HTR fine-tuning. We analyze how visual and linguistic characteristics of synthetic data influence fine-tuning outcomes and provide quantitative guidelines for selecting the most effective HTG model. The results of our analysis provide insights into the current capabilities of HTG methods and highlight key areas for further improvement in their application to low-resource HTR.
DiffusionPen: Towards Controlling the Style of Handwritten Text Generation
Sep 09, 2024



Handwritten Text Generation (HTG) conditioned on text and style is a challenging task due to the variability of inter-user characteristics and the unlimited combinations of characters that form new words unseen during training. Diffusion Models have recently shown promising results in HTG but still remain under-explored. We present DiffusionPen (DiffPen), a 5-shot style handwritten text generation approach based on Latent Diffusion Models. By utilizing a hybrid style extractor that combines metric learning and classification, our approach manages to capture both textual and stylistic characteristics of seen and unseen words and styles, generating realistic handwritten samples. Moreover, we explore several variation strategies of the data with multi-style mixtures and noisy embeddings, enhancing the robustness and diversity of the generated data. Extensive experiments using IAM offline handwriting database show that our method outperforms existing methods qualitatively and quantitatively, and its additional generated data can improve the performance of Handwriting Text Recognition (HTR) systems. The code is available at: https://github.com/koninik/DiffusionPen.
Rethinking HTG Evaluation: Bridging Generation and Recognition
Sep 04, 2024The evaluation of generative models for natural image tasks has been extensively studied. Similar protocols and metrics are used in cases with unique particularities, such as Handwriting Generation, even if they might not be completely appropriate. In this work, we introduce three measures tailored for HTG evaluation, $ \text{HTG}_{\text{HTR}} $, $ \text{HTG}_{\text{style}} $, and $ \text{HTG}_{\text{OOV}} $, and argue that they are more expedient to evaluate the quality of generated handwritten images. The metrics rely on the recognition error/accuracy of Handwriting Text Recognition and Writer Identification models and emphasize writing style, textual content, and diversity as the main aspects that adhere to the content of handwritten images. We conduct comprehensive experiments on the IAM handwriting database, showcasing that widely used metrics such as FID fail to properly quantify the diversity and the practical utility of generated handwriting samples. Our findings show that our metrics are richer in information and underscore the necessity of standardized evaluation protocols in HTG. The proposed metrics provide a more robust and informative protocol for assessing HTG quality, contributing to improved performance in HTR. Code for the evaluation protocol is available at: https://github.com/koninik/HTG_evaluation.
WordStylist: Styled Verbatim Handwritten Text Generation with Latent Diffusion Models
Mar 29, 2023
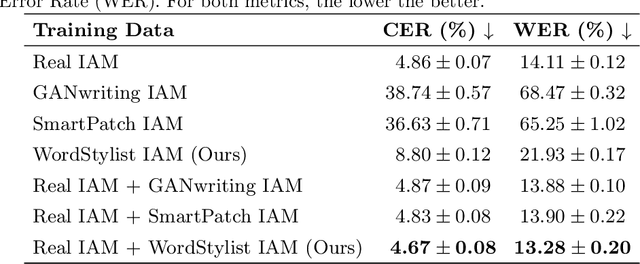
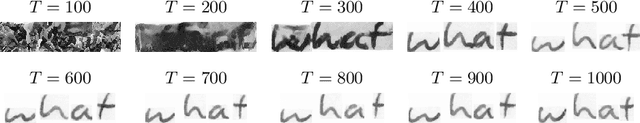

Text-to-Image synthesis is the task of generating an image according to a specific text description. Generative Adversarial Networks have been considered the standard method for image synthesis virtually since their introduction; today, Denoising Diffusion Probabilistic Models are recently setting a new baseline, with remarkable results in Text-to-Image synthesis, among other fields. Aside its usefulness per se, it can also be particularly relevant as a tool for data augmentation to aid training models for other document image processing tasks. In this work, we present a latent diffusion-based method for styled text-to-text-content-image generation on word-level. Our proposed method manages to generate realistic word image samples from different writer styles, by using class index styles and text content prompts without the need of adversarial training, writer recognition, or text recognition. We gauge system performance with Frechet Inception Distance, writer recognition accuracy, and writer retrieval. We show that the proposed model produces samples that are aesthetically pleasing, help boosting text recognition performance, and gets similar writer retrieval score as real data.
A Systematic Performance Analysis of Deep Perceptual Loss Networks Breaks Transfer Learning Conventions
Feb 08, 2023Deep perceptual loss is a type of loss function in computer vision that aims to mimic human perception by using the deep features extracted from neural networks. In recent years the method has been applied to great effect on a host of interesting computer vision tasks, especially for tasks with image or image-like outputs. Many applications of the method use pretrained networks, often convolutional networks, for loss calculation. Despite the increased interest and broader use, more effort is needed toward exploring which networks to use for calculating deep perceptual loss and from which layers to extract the features. This work aims to rectify this by systematically evaluating a host of commonly used and readily available, pretrained networks for a number of different feature extraction points on four existing use cases of deep perceptual loss. The four use cases are implementations of previous works where the selected networks and extraction points are evaluated instead of the networks and extraction points used in the original work. The experimental tasks are dimensionality reduction, image segmentation, super-resolution, and perceptual similarity. The performance on these four tasks, attributes of the networks, and extraction points are then used as a basis for an in-depth analysis. This analysis uncovers essential information regarding which architectures provide superior performance for deep perceptual loss and how to choose an appropriate extraction point for a particular task and dataset. Furthermore, the work discusses the implications of the results for deep perceptual loss and the broader field of transfer learning. The results break commonly held assumptions in transfer learning, which imply that deep perceptual loss deviates from most transfer learning settings or that these assumptions need a thorough re-evaluation.
A Survey of Historical Document Image Datasets
Mar 16, 2022
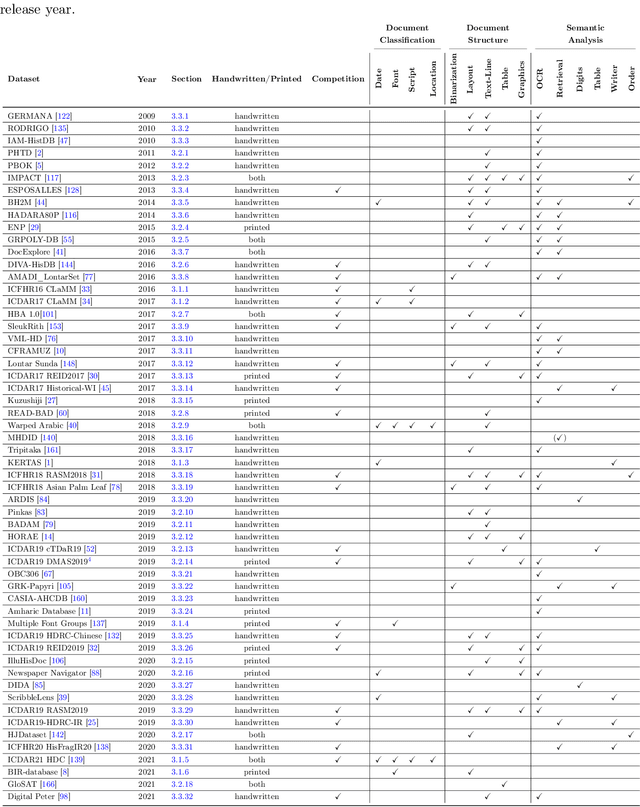
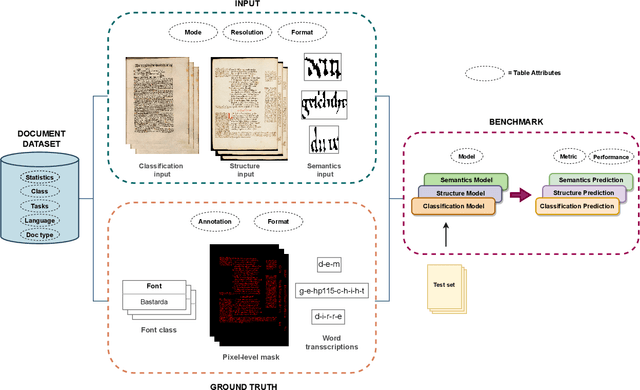
This paper presents a systematic literature review of image datasets for document image analysis, focusing on historical documents, such as handwritten manuscripts and early prints. Finding appropriate datasets for historical document analysis is a crucial prerequisite to facilitate research using different machine learning algorithms. However, because of the very large variety of the actual data (e.g., scripts, tasks, dates, support systems, and amount of deterioration), the different formats for data and label representation, and the different evaluation processes and benchmarks, finding appropriate datasets is a difficult task. This work fills this gap, presenting a meta-study on existing datasets. After a systematic selection process (according to PRISMA guidelines), we select 56 studies that are chosen based on different factors, such as the year of publication, number of methods implemented in the article, reliability of the chosen algorithms, dataset size, and journal outlet. We summarize each study by assigning it to one of three pre-defined tasks: document classification, layout structure, or semantic analysis. We present the statistics, document type, language, tasks, input visual aspects, and ground truth information for every dataset. In addition, we provide the benchmark tasks and results from these papers or recent competitions. We further discuss gaps and challenges in this domain. We advocate for providing conversion tools to common formats (e.g., COCO format for computer vision tasks) and always providing a set of evaluation metrics, instead of just one, to make results comparable across studies.
Potential Idiomatic Expression (PIE)-English: Corpus for Classes of Idioms
Apr 25, 2021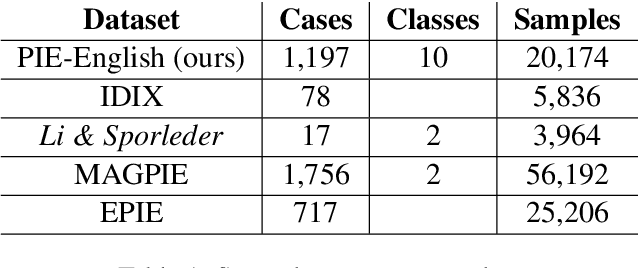
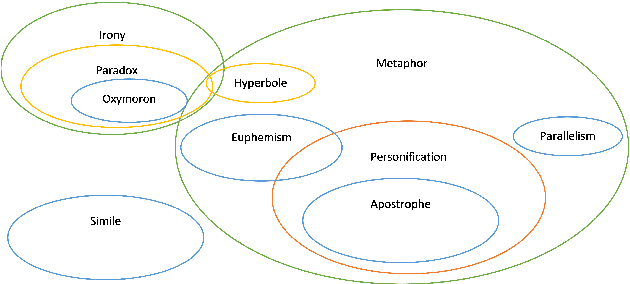
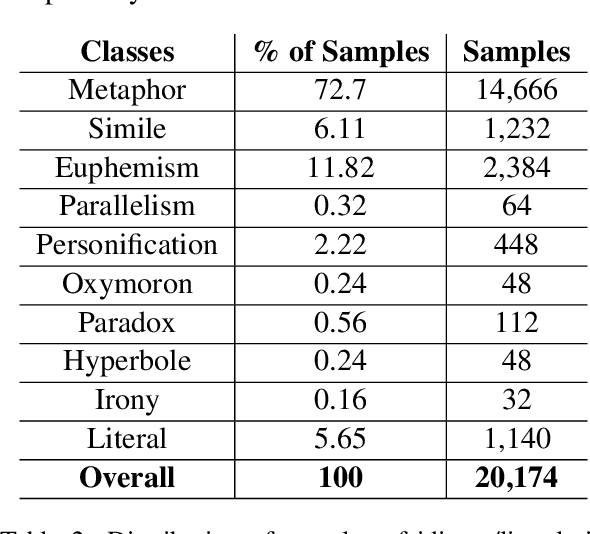
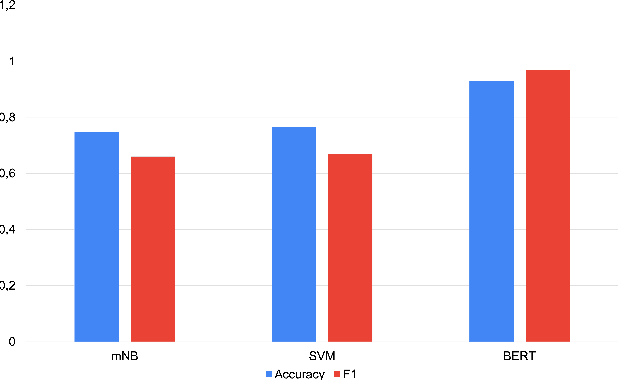
We present a fairly large, Potential Idiomatic Expression (PIE) dataset for Natural Language Processing (NLP) in English. The challenges with NLP systems with regards to tasks such as Machine Translation (MT), word sense disambiguation (WSD) and information retrieval make it imperative to have a labelled idioms dataset with classes such as it is in this work. To the best of the authors' knowledge, this is the first idioms corpus with classes of idioms beyond the literal and the general idioms classification. In particular, the following classes are labelled in the dataset: metaphor, simile, euphemism, parallelism, personification, oxymoron, paradox, hyperbole, irony and literal. Many past efforts have been limited in the corpus size and classes of samples but this dataset contains over 20,100 samples with almost 1,200 cases of idioms (with their meanings) from 10 classes (or senses). The corpus may also be extended by researchers to meet specific needs. The corpus has part of speech (PoS) tagging from the NLTK library. Classification experiments performed on the corpus to obtain a baseline and comparison among three common models, including the BERT model, give good results. We also make publicly available the corpus and the relevant codes for working with it for NLP tasks.