 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotential Idiomatic Expression (PIE)-English: Corpus for Classes of Idioms
Paper and Code
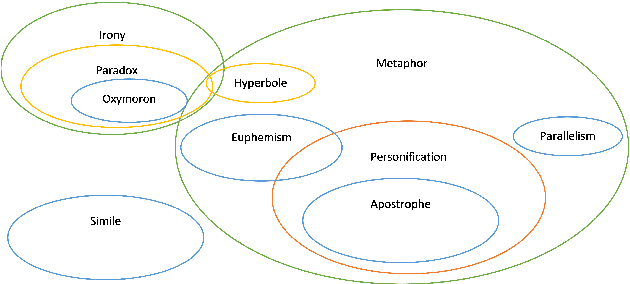
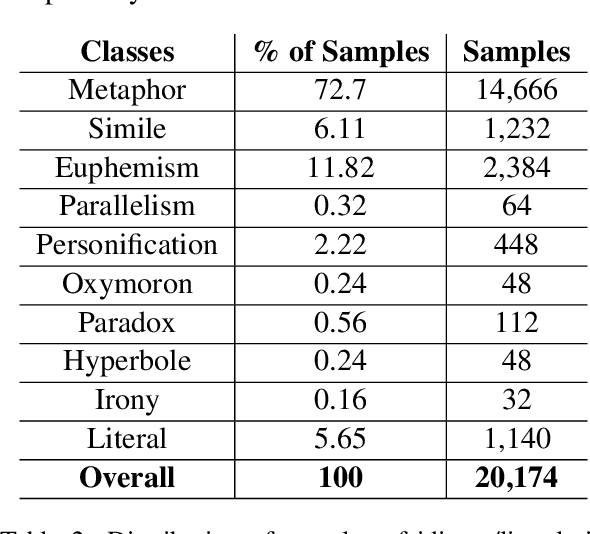
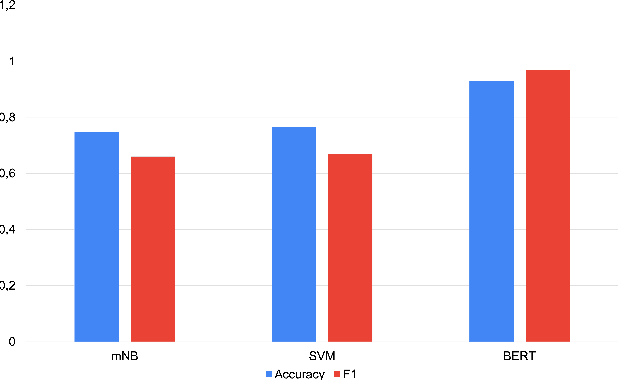
We present a fairly large, Potential Idiomatic Expression (PIE) dataset for Natural Language Processing (NLP) in English. The challenges with NLP systems with regards to tasks such as Machine Translation (MT), word sense disambiguation (WSD) and information retrieval make it imperative to have a labelled idioms dataset with classes such as it is in this work. To the best of the authors' knowledge, this is the first idioms corpus with classes of idioms beyond the literal and the general idioms classification. In particular, the following classes are labelled in the dataset: metaphor, simile, euphemism, parallelism, personification, oxymoron, paradox, hyperbole, irony and literal. Many past efforts have been limited in the corpus size and classes of samples but this dataset contains over 20,100 samples with almost 1,200 cases of idioms (with their meanings) from 10 classes (or senses). The corpus may also be extended by researchers to meet specific needs. The corpus has part of speech (PoS) tagging from the NLTK library. Classification experiments performed on the corpus to obtain a baseline and comparison among three common models, including the BERT model, give good results. We also make publicly available the corpus and the relevant codes for working with it for NLP tasks.