 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBipol: Multi-axes Evaluation of Bias with Explainability in Benchmark Datasets
Jan 28, 2023



We evaluate five English NLP benchmark datasets (available on the superGLUE leaderboard) for bias, along multiple axes. The datasets are the following: Boolean Question (Boolq), CommitmentBank (CB), Winograd Schema Challenge (WSC), Winogender diagnostic (AXg), and Recognising Textual Entailment (RTE). Bias can be harmful and it is known to be common in data, which ML models learn from. In order to mitigate bias in data, it is crucial to be able to estimate it objectively. We use bipol, a novel multi-axes bias metric with explainability, to quantify and explain how much bias exists in these datasets. Multilingual, multi-axes bias evaluation is not very common. Hence, we also contribute a new, large labelled Swedish bias-detection dataset, with about 2 million samples; translated from the English version. In addition, we contribute new multi-axes lexica for bias detection in Swedish. We train a SotA model on the new dataset for bias detection. We make the codes, model, and new dataset publicly available.
A Comparison of Temporal Encoders for Neuromorphic Keyword Spotting with Few Neurons
Jan 24, 2023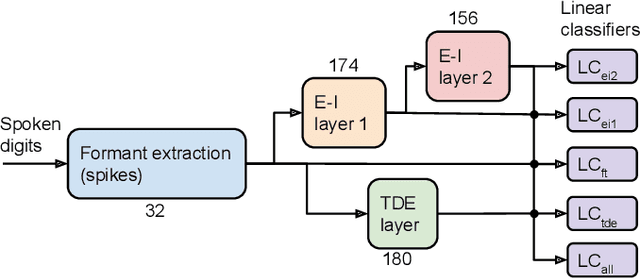
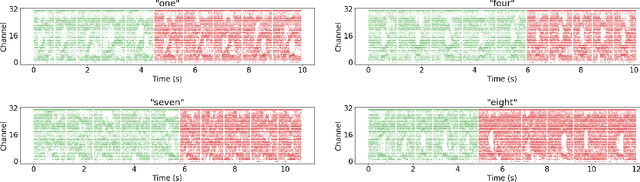
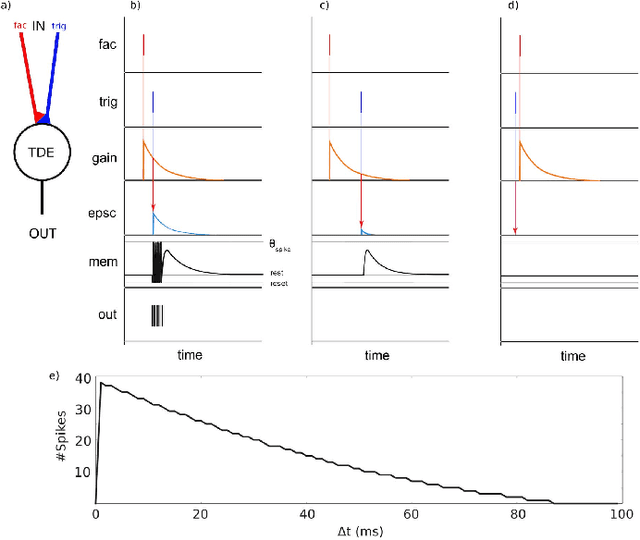
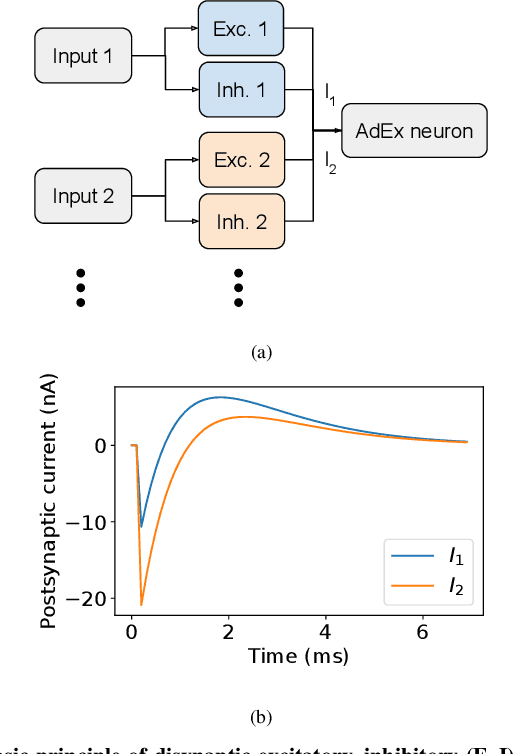
With the expansion of AI-powered virtual assistants, there is a need for low-power keyword spotting systems providing a "wake-up" mechanism for subsequent computationally expensive speech recognition. One promising approach is the use of neuromorphic sensors and spiking neural networks (SNNs) implemented in neuromorphic processors for sparse event-driven sensing. However, this requires resource-efficient SNN mechanisms for temporal encoding, which need to consider that these systems process information in a streaming manner, with physical time being an intrinsic property of their operation. In this work, two candidate neurocomputational elements for temporal encoding and feature extraction in SNNs described in recent literature - the spiking time-difference encoder (TDE) and disynaptic excitatory-inhibitory (E-I) elements - are comparatively investigated in a keyword-spotting task on formants computed from spoken digits in the TIDIGITS dataset. While both encoders improve performance over direct classification of the formant features in the training data, enabling a complete binary classification with a logistic regression model, they show no clear improvements on the test set. Resource-efficient keyword spotting applications may benefit from the use of these encoders, but further work on methods for learning the time constants and weights is required to investigate their full potential.
T5 for Hate Speech, Augmented Data and Ensemble
Oct 11, 2022

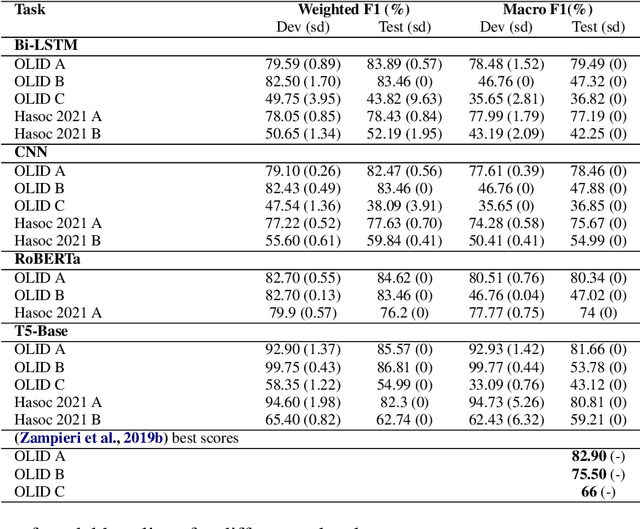
We conduct relatively extensive investigations of automatic hate speech (HS) detection using different state-of-the-art (SoTA) baselines over 11 subtasks of 6 different datasets. Our motivation is to determine which of the recent SoTA models is best for automatic hate speech detection and what advantage methods like data augmentation and ensemble may have on the best model, if any. We carry out 6 cross-task investigations. We achieve new SoTA on two subtasks - macro F1 scores of 91.73% and 53.21% for subtasks A and B of the HASOC 2020 dataset, where previous SoTA are 51.52% and 26.52%, respectively. We achieve near-SoTA on two others - macro F1 scores of 81.66% for subtask A of the OLID 2019 dataset and 82.54% for subtask A of the HASOC 2021 dataset, where SoTA are 82.9% and 83.05%, respectively. We perform error analysis and use two explainable artificial intelligence (XAI) algorithms (IG and SHAP) to reveal how two of the models (Bi-LSTM and T5) make the predictions they do by using examples. Other contributions of this work are 1) the introduction of a simple, novel mechanism for correcting out-of-class (OOC) predictions in T5, 2) a detailed description of the data augmentation methods, 3) the revelation of the poor data annotations in the HASOC 2021 dataset by using several examples and XAI (buttressing the need for better quality control), and 4) the public release of our model checkpoints and codes to foster transparency.
Vector Representations of Idioms in Conversational Systems
May 07, 2022



We demonstrate, in this study, that an open-domain conversational system trained on idioms or figurative language generates more fitting responses to prompts containing idioms. Idioms are part of everyday speech in many languages, across many cultures, but they pose a great challenge for many Natural Language Processing (NLP) systems that involve tasks such as Information Retrieval (IR) and Machine Translation (MT), besides conversational AI. We utilize the Potential Idiomatic Expression (PIE)-English idioms corpus for the two tasks that we investigate: classification and conversation generation. We achieve state-of-the-art (SoTA) result of 98% macro F1 score on the classification task by using the SoTA T5 model. We experiment with three instances of the SoTA dialogue model, Dialogue Generative Pre-trained Transformer (DialoGPT), for conversation generation. Their performances are evaluated using the automatic metric perplexity and human evaluation. The results show that the model trained on the idiom corpus generates more fitting responses to prompts containing idioms 71.9% of the time, compared to a similar model not trained on the idioms corpus. We contribute the model checkpoint/demo and code on the HuggingFace hub for public access.
State-of-the-art in Open-domain Conversational AI: A Survey
May 02, 2022

We survey SoTA open-domain conversational AI models with the purpose of presenting the prevailing challenges that still exist to spur future research. In addition, we provide statistics on the gender of conversational AI in order to guide the ethics discussion surrounding the issue. Open-domain conversational AI are known to have several challenges, including bland responses and performance degradation when prompted with figurative language, among others. First, we provide some background by discussing some topics of interest in conversational AI. We then discuss the method applied to the two investigations carried out that make up this study. The first investigation involves a search for recent SoTA open-domain conversational AI models while the second involves the search for 100 conversational AI to assess their gender. Results of the survey show that progress has been made with recent SoTA conversational AI, but there are still persistent challenges that need to be solved, and the female gender is more common than the male for conversational AI. One main take-away is that hybrid models of conversational AI offer more advantages than any single architecture. The key contributions of this survey are 1) the identification of prevailing challenges in SoTA open-domain conversational AI, 2) the unusual discussion about open-domain conversational AI for low-resource languages, and 3) the discussion about the ethics surrounding the gender of conversational AI.
Ìtàkúròso: Exploiting Cross-Lingual Transferability for Natural Language Generation of Dialogues in Low-Resource, African Languages
Apr 17, 2022
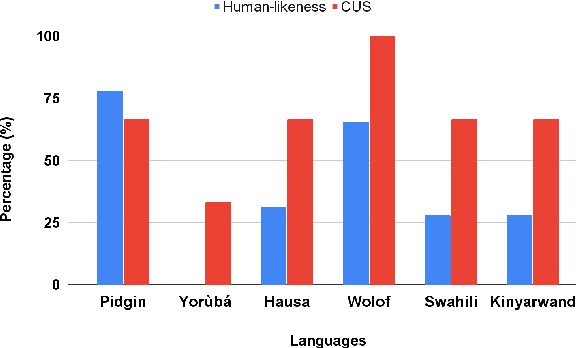
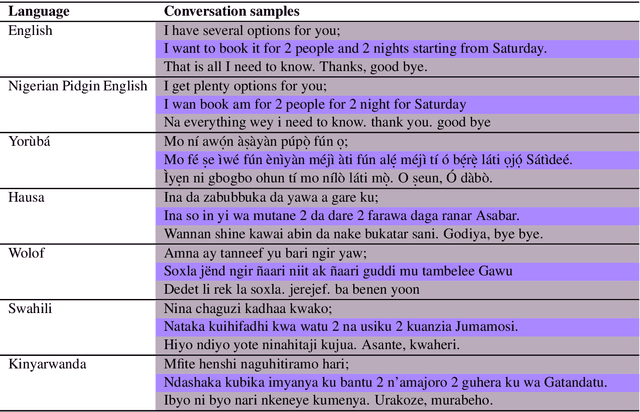
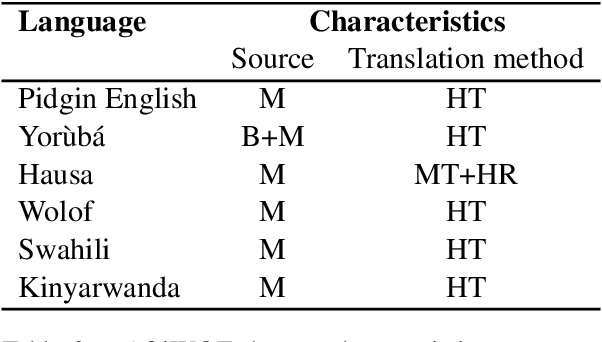
We investigate the possibility of cross-lingual transfer from a state-of-the-art (SoTA) deep monolingual model (DialoGPT) to 6 African languages and compare with 2 baselines (BlenderBot 90M, another SoTA, and a simple Seq2Seq). The languages are Swahili, Wolof, Hausa, Nigerian Pidgin English, Kinyarwanda & Yor\`ub\'a. Generation of dialogues is known to be a challenging task for many reasons. It becomes more challenging for African languages which are low-resource in terms of data. Therefore, we translate a small portion of the English multi-domain MultiWOZ dataset for each target language. Besides intrinsic evaluation (i.e. perplexity), we conduct human evaluation of single-turn conversations by using majority votes and measure inter-annotator agreement (IAA). The results show that the hypothesis that deep monolingual models learn some abstractions that generalise across languages holds. We observe human-like conversations in 5 out of the 6 languages. It, however, applies to different degrees in different languages, which is expected. The language with the most transferable properties is the Nigerian Pidgin English, with a human-likeness score of 78.1%, of which 34.4% are unanimous. The main contributions of this paper include the representation (through the provision of high-quality dialogue data) of under-represented African languages and demonstrating the cross-lingual transferability hypothesis for dialogue systems. We also provide the datasets and host the model checkpoints/demos on the HuggingFace hub for public access.
ML_LTU at SemEval-2022 Task 4: T5 Towards Identifying Patronizing and Condescending Language
Apr 15, 2022


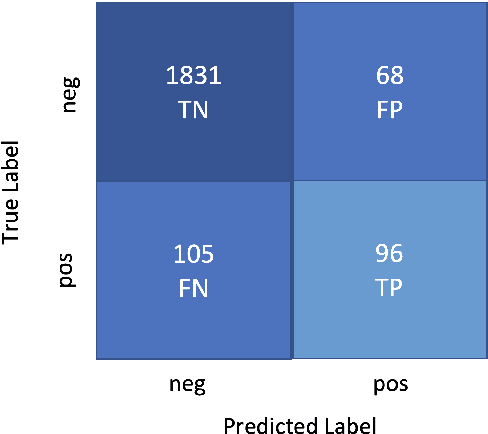
This paper describes the system used by the Machine Learning Group of LTU in subtask 1 of the SemEval-2022 Task 4: Patronizing and Condescending Language (PCL) Detection. Our system consists of finetuning a pretrained Text-to-Text-Transfer Transformer (T5) and innovatively reducing its out-of-class predictions. The main contributions of this paper are 1) the description of the implementation details of the T5 model we used, 2) analysis of the successes & struggles of the model in this task, and 3) ablation studies beyond the official submission to ascertain the relative importance of data split. Our model achieves an F1 score of 0.5452 on the official test set.
HaT5: Hate Language Identification using Text-to-Text Transfer Transformer
Feb 11, 2022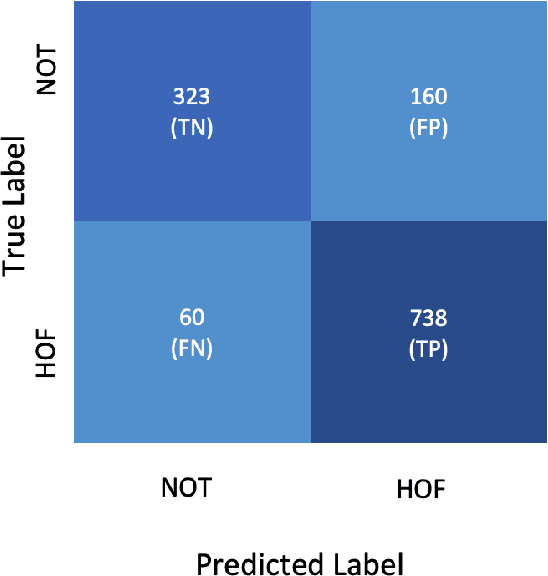



We investigate the performance of a state-of-the art (SoTA) architecture T5 (available on the SuperGLUE) and compare with it 3 other previous SoTA architectures across 5 different tasks from 2 relatively diverse datasets. The datasets are diverse in terms of the number and types of tasks they have. To improve performance, we augment the training data by using an autoregressive model. We achieve near-SoTA results on a couple of the tasks - macro F1 scores of 81.66% for task A of the OLID 2019 dataset and 82.54% for task A of the hate speech and offensive content (HASOC) 2021 dataset, where SoTA are 82.9% and 83.05%, respectively. We perform error analysis and explain why one of the models (Bi-LSTM) makes the predictions it does by using a publicly available algorithm: Integrated Gradient (IG). This is because explainable artificial intelligence (XAI) is essential for earning the trust of users. The main contributions of this work are the implementation method of T5, which is discussed; the data augmentation using a new conversational AI model checkpoint, which brought performance improvements; and the revelation on the shortcomings of HASOC 2021 dataset. It reveals the difficulties of poor data annotation by using a small set of examples where the T5 model made the correct predictions, even when the ground truth of the test set were incorrect (in our opinion). We also provide our model checkpoints on the HuggingFace hub1 to foster transparency.
Småprat: DialoGPT for Natural Language Generation of Swedish Dialogue by Transfer Learning
Oct 12, 2021

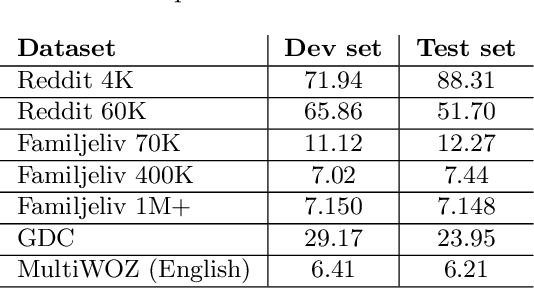
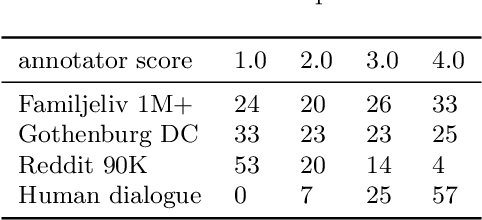
Building open-domain conversational systems (or chatbots) that produce convincing responses is a recognized challenge. Recent state-of-the-art (SoTA) transformer-based models for the generation of natural language dialogue have demonstrated impressive performance in simulating human-like, single-turn conversations in English. This work investigates, by an empirical study, the potential for transfer learning of such models to Swedish language. DialoGPT, an English language pre-trained model, is adapted by training on three different Swedish language conversational datasets obtained from publicly available sources. Perplexity score (an automated intrinsic language model metric) and surveys by human evaluation were used to assess the performances of the fine-tuned models, with results that indicate that the capacity for transfer learning can be exploited with considerable success. Human evaluators asked to score the simulated dialogue judged over 57% of the chatbot responses to be human-like for the model trained on the largest (Swedish) dataset. We provide the demos and model checkpoints of our English and Swedish chatbots on the HuggingFace platform for public use.
Spatiotemporal Spike-Pattern Selectivity in Single Mixed-Signal Neurons with Balanced Synapses
Jun 10, 2021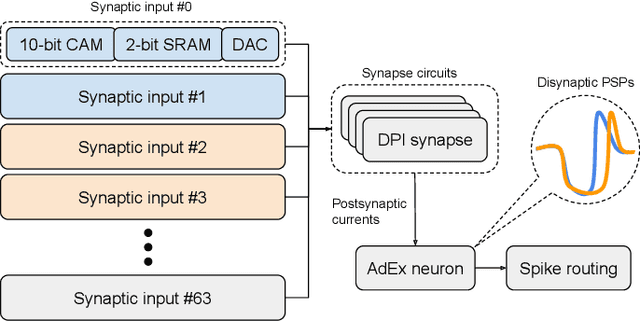
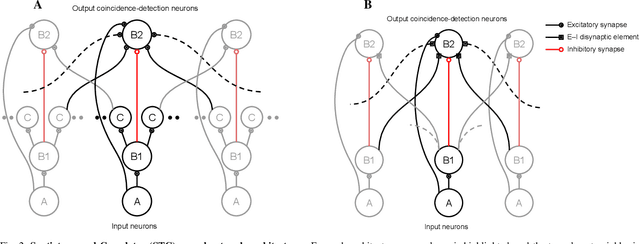
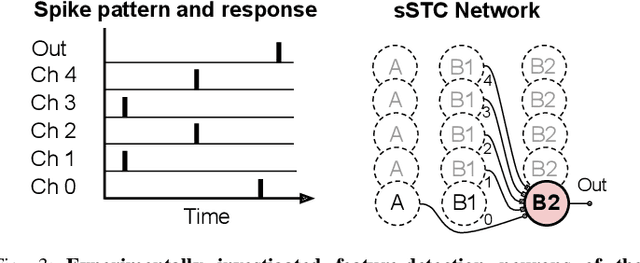
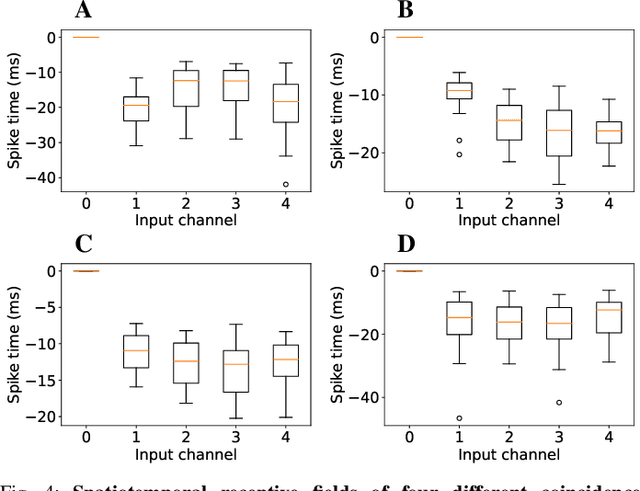
Realizing the potential of mixed-signal neuromorphic processors for ultra-low-power inference and learning requires efficient use of their inhomogeneous analog circuitry as well as sparse, time-based information encoding and processing. Here, we investigate spike-timing-based spatiotemporal receptive fields of output-neurons in the Spatiotemporal Correlator (STC) network, for which we used excitatory-inhibitory balanced disynaptic inputs instead of dedicated axonal or neuronal delays. We present hardware-in-the-loop experiments with a mixed-signal DYNAP-SE neuromorphic processor, in which five-dimensional receptive fields of hardware neurons were mapped by randomly sampling input spike-patterns from a uniform distribution. We find that, when the balanced disynaptic elements are randomly programmed, some of the neurons display distinct receptive fields. Furthermore, we demonstrate how a neuron was tuned to detect a particular spatiotemporal feature, to which it initially was non-selective, by activating a different subset of the inhomogeneous analog synaptic circuits. The energy dissipation of the balanced synaptic elements is one order of magnitude lower per lateral connection (0.65 nJ vs 9.3 nJ per spike) than former delay-based neuromorphic hardware implementations. Thus, we show how the inhomogeneous synaptic circuits could be utilized for resource-efficient implementation of STC network layers, in a way that enables synapse-address reprogramming as a discrete mechanism for feature tuning.