 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBipol: A Novel Multi-Axes Bias Evaluation Metric with Explainability for NLP
Apr 08, 2023



We introduce bipol, a new metric with explainability, for estimating social bias in text data. Harmful bias is prevalent in many online sources of data that are used for training machine learning (ML) models. In a step to address this challenge we create a novel metric that involves a two-step process: corpus-level evaluation based on model classification and sentence-level evaluation based on (sensitive) term frequency (TF). After creating new models to detect bias along multiple axes using SotA architectures, we evaluate two popular NLP datasets (COPA and SQUAD). As additional contribution, we created a large dataset (with almost 2 million labelled samples) for training models in bias detection and make it publicly available. We also make public our codes.
Bipol: Multi-axes Evaluation of Bias with Explainability in Benchmark Datasets
Jan 28, 2023



We evaluate five English NLP benchmark datasets (available on the superGLUE leaderboard) for bias, along multiple axes. The datasets are the following: Boolean Question (Boolq), CommitmentBank (CB), Winograd Schema Challenge (WSC), Winogender diagnostic (AXg), and Recognising Textual Entailment (RTE). Bias can be harmful and it is known to be common in data, which ML models learn from. In order to mitigate bias in data, it is crucial to be able to estimate it objectively. We use bipol, a novel multi-axes bias metric with explainability, to quantify and explain how much bias exists in these datasets. Multilingual, multi-axes bias evaluation is not very common. Hence, we also contribute a new, large labelled Swedish bias-detection dataset, with about 2 million samples; translated from the English version. In addition, we contribute new multi-axes lexica for bias detection in Swedish. We train a SotA model on the new dataset for bias detection. We make the codes, model, and new dataset publicly available.
T5 for Hate Speech, Augmented Data and Ensemble
Oct 11, 2022

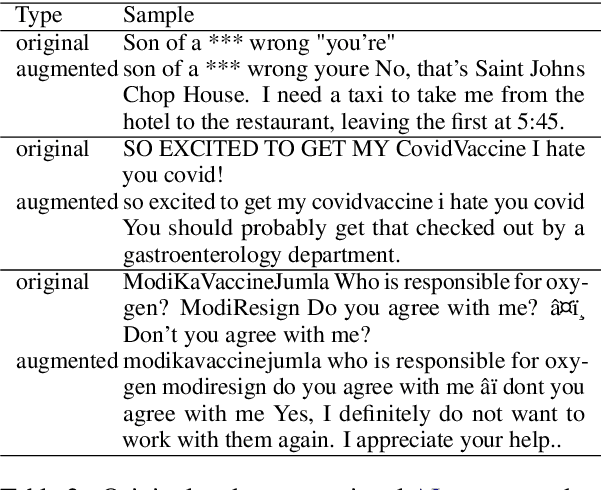
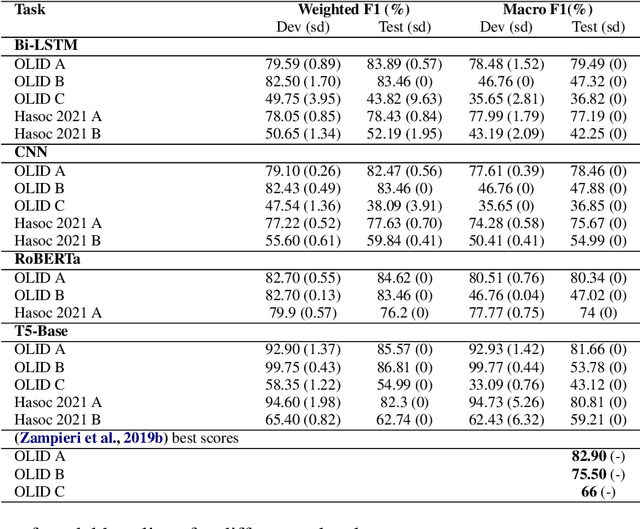
We conduct relatively extensive investigations of automatic hate speech (HS) detection using different state-of-the-art (SoTA) baselines over 11 subtasks of 6 different datasets. Our motivation is to determine which of the recent SoTA models is best for automatic hate speech detection and what advantage methods like data augmentation and ensemble may have on the best model, if any. We carry out 6 cross-task investigations. We achieve new SoTA on two subtasks - macro F1 scores of 91.73% and 53.21% for subtasks A and B of the HASOC 2020 dataset, where previous SoTA are 51.52% and 26.52%, respectively. We achieve near-SoTA on two others - macro F1 scores of 81.66% for subtask A of the OLID 2019 dataset and 82.54% for subtask A of the HASOC 2021 dataset, where SoTA are 82.9% and 83.05%, respectively. We perform error analysis and use two explainable artificial intelligence (XAI) algorithms (IG and SHAP) to reveal how two of the models (Bi-LSTM and T5) make the predictions they do by using examples. Other contributions of this work are 1) the introduction of a simple, novel mechanism for correcting out-of-class (OOC) predictions in T5, 2) a detailed description of the data augmentation methods, 3) the revelation of the poor data annotations in the HASOC 2021 dataset by using several examples and XAI (buttressing the need for better quality control), and 4) the public release of our model checkpoints and codes to foster transparency.
HaT5: Hate Language Identification using Text-to-Text Transfer Transformer
Feb 11, 2022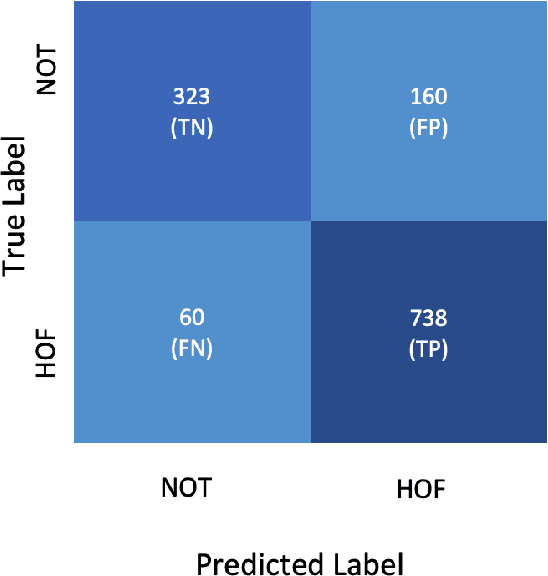



We investigate the performance of a state-of-the art (SoTA) architecture T5 (available on the SuperGLUE) and compare with it 3 other previous SoTA architectures across 5 different tasks from 2 relatively diverse datasets. The datasets are diverse in terms of the number and types of tasks they have. To improve performance, we augment the training data by using an autoregressive model. We achieve near-SoTA results on a couple of the tasks - macro F1 scores of 81.66% for task A of the OLID 2019 dataset and 82.54% for task A of the hate speech and offensive content (HASOC) 2021 dataset, where SoTA are 82.9% and 83.05%, respectively. We perform error analysis and explain why one of the models (Bi-LSTM) makes the predictions it does by using a publicly available algorithm: Integrated Gradient (IG). This is because explainable artificial intelligence (XAI) is essential for earning the trust of users. The main contributions of this work are the implementation method of T5, which is discussed; the data augmentation using a new conversational AI model checkpoint, which brought performance improvements; and the revelation on the shortcomings of HASOC 2021 dataset. It reveals the difficulties of poor data annotation by using a small set of examples where the T5 model made the correct predictions, even when the ground truth of the test set were incorrect (in our opinion). We also provide our model checkpoints on the HuggingFace hub1 to foster transparency.
Småprat: DialoGPT for Natural Language Generation of Swedish Dialogue by Transfer Learning
Oct 12, 2021

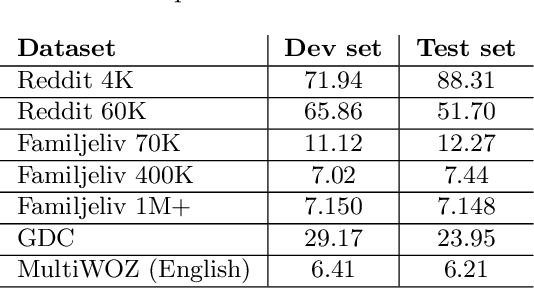
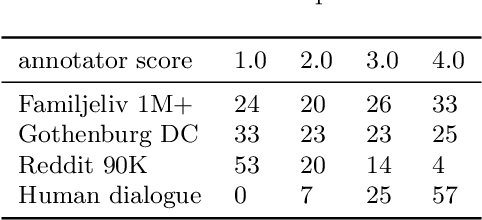
Building open-domain conversational systems (or chatbots) that produce convincing responses is a recognized challenge. Recent state-of-the-art (SoTA) transformer-based models for the generation of natural language dialogue have demonstrated impressive performance in simulating human-like, single-turn conversations in English. This work investigates, by an empirical study, the potential for transfer learning of such models to Swedish language. DialoGPT, an English language pre-trained model, is adapted by training on three different Swedish language conversational datasets obtained from publicly available sources. Perplexity score (an automated intrinsic language model metric) and surveys by human evaluation were used to assess the performances of the fine-tuned models, with results that indicate that the capacity for transfer learning can be exploited with considerable success. Human evaluators asked to score the simulated dialogue judged over 57% of the chatbot responses to be human-like for the model trained on the largest (Swedish) dataset. We provide the demos and model checkpoints of our English and Swedish chatbots on the HuggingFace platform for public use.