 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating and Benchmarking a Synthetic Dataset for Cloud Optical Thickness Estimation
Nov 23, 2023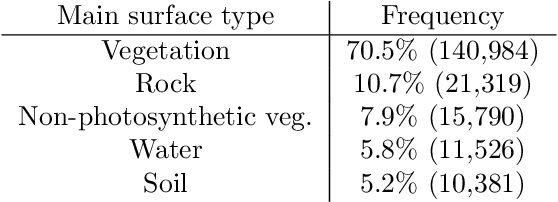
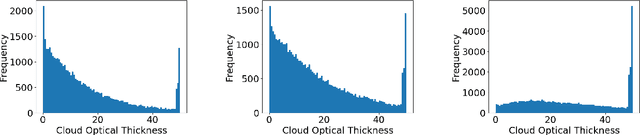
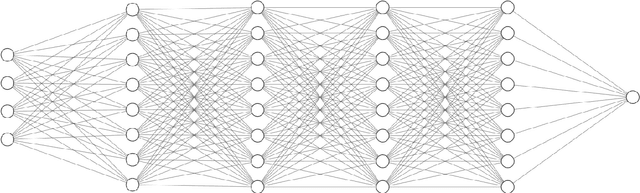
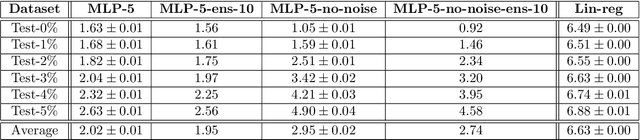
Cloud formations often obscure optical satellite-based monitoring of the Earth's surface, thus limiting Earth observation (EO) activities such as land cover mapping, ocean color analysis, and cropland monitoring. The integration of machine learning (ML) methods within the remote sensing domain has significantly improved performance on a wide range of EO tasks, including cloud detection and filtering, but there is still much room for improvement. A key bottleneck is that ML methods typically depend on large amounts of annotated data for training, which is often difficult to come by in EO contexts. This is especially true for the task of cloud optical thickness (COT) estimation. A reliable estimation of COT enables more fine-grained and application-dependent control compared to using pre-specified cloud categories, as is commonly done in practice. To alleviate the COT data scarcity problem, in this work we propose a novel synthetic dataset for COT estimation, where top-of-atmosphere radiances have been simulated for 12 of the spectral bands of the Multi-Spectral Instrument (MSI) sensor onboard Sentinel-2 platforms. These data points have been simulated under consideration of different cloud types, COTs, and ground surface and atmospheric profiles. Extensive experimentation of training several ML models to predict COT from the measured reflectivity of the spectral bands demonstrates the usefulness of our proposed dataset. Generalization to real data is also demonstrated on two satellite image datasets -- one that is publicly available, and one which we have collected and annotated. The synthetic data, the newly collected real dataset, code and models have been made publicly available at https://github.com/aleksispi/ml-cloud-opt-thick.
Performance of data-driven inner speech decoding with same-task EEG-fMRI data fusion and bimodal models
Jun 19, 2023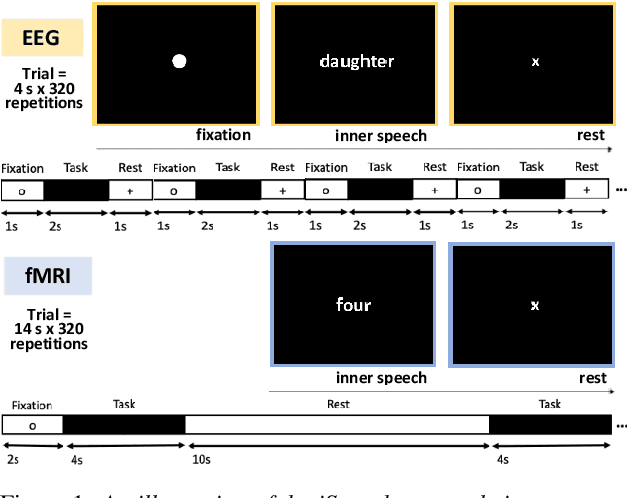
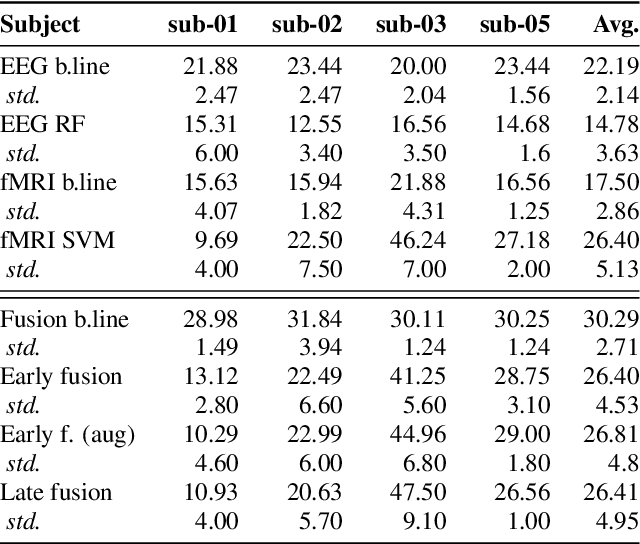
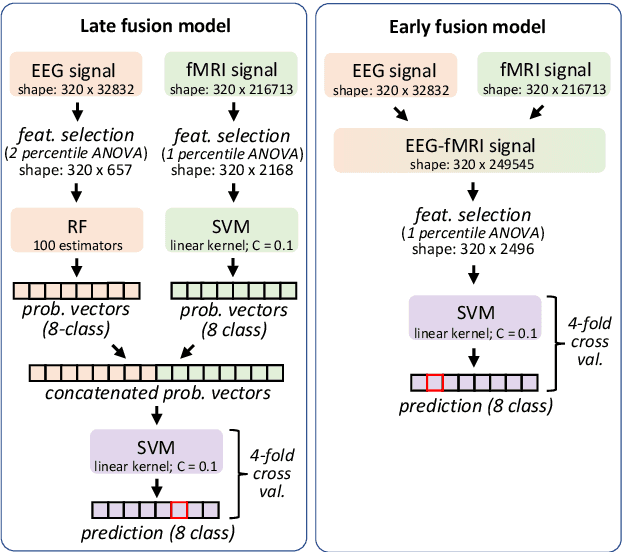
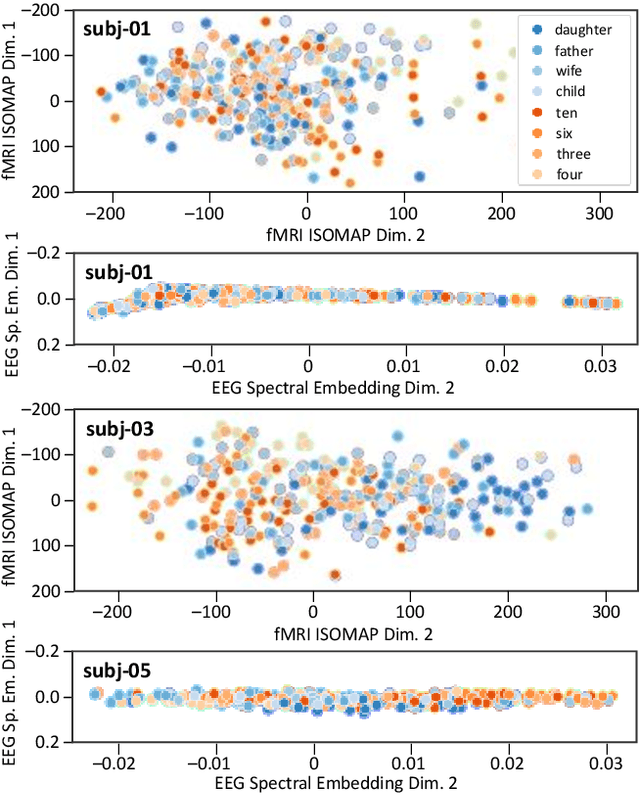
Decoding inner speech from the brain signal via hybridisation of fMRI and EEG data is explored to investigate the performance benefits over unimodal models. Two different bimodal fusion approaches are examined: concatenation of probability vectors output from unimodal fMRI and EEG machine learning models, and data fusion with feature engineering. Same task inner speech data are recorded from four participants, and different processing strategies are compared and contrasted to previously-employed hybridisation methods. Data across participants are discovered to encode different underlying structures, which results in varying decoding performances between subject-dependent fusion models. Decoding performance is demonstrated as improved when pursuing bimodal fMRI-EEG fusion strategies, if the data show underlying structure.
A Systematic Performance Analysis of Deep Perceptual Loss Networks Breaks Transfer Learning Conventions
Feb 08, 2023Deep perceptual loss is a type of loss function in computer vision that aims to mimic human perception by using the deep features extracted from neural networks. In recent years the method has been applied to great effect on a host of interesting computer vision tasks, especially for tasks with image or image-like outputs. Many applications of the method use pretrained networks, often convolutional networks, for loss calculation. Despite the increased interest and broader use, more effort is needed toward exploring which networks to use for calculating deep perceptual loss and from which layers to extract the features. This work aims to rectify this by systematically evaluating a host of commonly used and readily available, pretrained networks for a number of different feature extraction points on four existing use cases of deep perceptual loss. The four use cases are implementations of previous works where the selected networks and extraction points are evaluated instead of the networks and extraction points used in the original work. The experimental tasks are dimensionality reduction, image segmentation, super-resolution, and perceptual similarity. The performance on these four tasks, attributes of the networks, and extraction points are then used as a basis for an in-depth analysis. This analysis uncovers essential information regarding which architectures provide superior performance for deep perceptual loss and how to choose an appropriate extraction point for a particular task and dataset. Furthermore, the work discusses the implications of the results for deep perceptual loss and the broader field of transfer learning. The results break commonly held assumptions in transfer learning, which imply that deep perceptual loss deviates from most transfer learning settings or that these assumptions need a thorough re-evaluation.
T5 for Hate Speech, Augmented Data and Ensemble
Oct 11, 2022

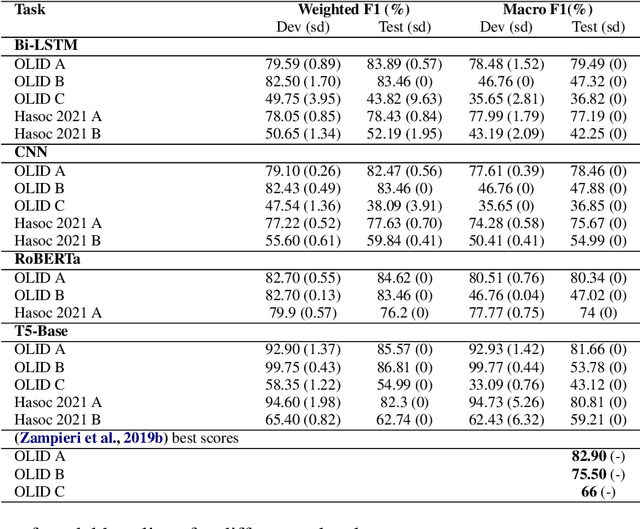
We conduct relatively extensive investigations of automatic hate speech (HS) detection using different state-of-the-art (SoTA) baselines over 11 subtasks of 6 different datasets. Our motivation is to determine which of the recent SoTA models is best for automatic hate speech detection and what advantage methods like data augmentation and ensemble may have on the best model, if any. We carry out 6 cross-task investigations. We achieve new SoTA on two subtasks - macro F1 scores of 91.73% and 53.21% for subtasks A and B of the HASOC 2020 dataset, where previous SoTA are 51.52% and 26.52%, respectively. We achieve near-SoTA on two others - macro F1 scores of 81.66% for subtask A of the OLID 2019 dataset and 82.54% for subtask A of the HASOC 2021 dataset, where SoTA are 82.9% and 83.05%, respectively. We perform error analysis and use two explainable artificial intelligence (XAI) algorithms (IG and SHAP) to reveal how two of the models (Bi-LSTM and T5) make the predictions they do by using examples. Other contributions of this work are 1) the introduction of a simple, novel mechanism for correcting out-of-class (OOC) predictions in T5, 2) a detailed description of the data augmentation methods, 3) the revelation of the poor data annotations in the HASOC 2021 dataset by using several examples and XAI (buttressing the need for better quality control), and 4) the public release of our model checkpoints and codes to foster transparency.
HaT5: Hate Language Identification using Text-to-Text Transfer Transformer
Feb 11, 2022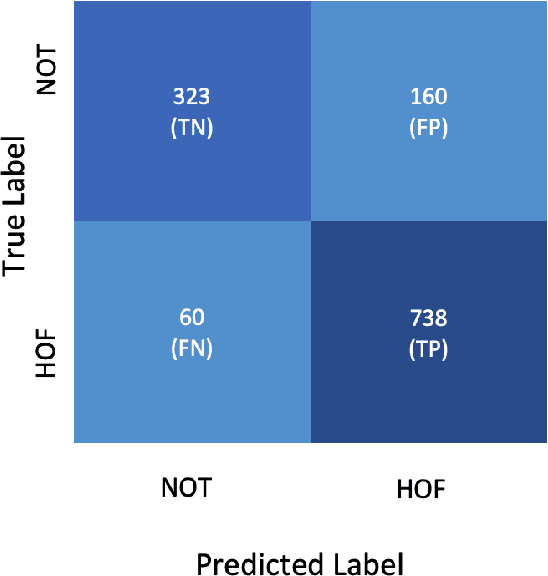



We investigate the performance of a state-of-the art (SoTA) architecture T5 (available on the SuperGLUE) and compare with it 3 other previous SoTA architectures across 5 different tasks from 2 relatively diverse datasets. The datasets are diverse in terms of the number and types of tasks they have. To improve performance, we augment the training data by using an autoregressive model. We achieve near-SoTA results on a couple of the tasks - macro F1 scores of 81.66% for task A of the OLID 2019 dataset and 82.54% for task A of the hate speech and offensive content (HASOC) 2021 dataset, where SoTA are 82.9% and 83.05%, respectively. We perform error analysis and explain why one of the models (Bi-LSTM) makes the predictions it does by using a publicly available algorithm: Integrated Gradient (IG). This is because explainable artificial intelligence (XAI) is essential for earning the trust of users. The main contributions of this work are the implementation method of T5, which is discussed; the data augmentation using a new conversational AI model checkpoint, which brought performance improvements; and the revelation on the shortcomings of HASOC 2021 dataset. It reveals the difficulties of poor data annotation by using a small set of examples where the T5 model made the correct predictions, even when the ground truth of the test set were incorrect (in our opinion). We also provide our model checkpoints on the HuggingFace hub1 to foster transparency.
Småprat: DialoGPT for Natural Language Generation of Swedish Dialogue by Transfer Learning
Oct 12, 2021

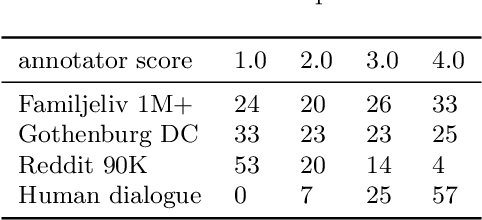
Building open-domain conversational systems (or chatbots) that produce convincing responses is a recognized challenge. Recent state-of-the-art (SoTA) transformer-based models for the generation of natural language dialogue have demonstrated impressive performance in simulating human-like, single-turn conversations in English. This work investigates, by an empirical study, the potential for transfer learning of such models to Swedish language. DialoGPT, an English language pre-trained model, is adapted by training on three different Swedish language conversational datasets obtained from publicly available sources. Perplexity score (an automated intrinsic language model metric) and surveys by human evaluation were used to assess the performances of the fine-tuned models, with results that indicate that the capacity for transfer learning can be exploited with considerable success. Human evaluators asked to score the simulated dialogue judged over 57% of the chatbot responses to be human-like for the model trained on the largest (Swedish) dataset. We provide the demos and model checkpoints of our English and Swedish chatbots on the HuggingFace platform for public use.