 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric Hub: A metric library and practical selection workflow for use-case-driven data quality assessment in medical AI
Jan 30, 2026Machine learning (ML) in medicine has transitioned from research to concrete applications aimed at supporting several medical purposes like therapy selection, monitoring and treatment. Acceptance and effective adoption by clinicians and patients, as well as regulatory approval, require evidence of trustworthiness. A major factor for the development of trustworthy AI is the quantification of data quality for AI model training and testing. We have recently proposed the METRIC-framework for systematically evaluating the suitability (fit-for-purpose) of data for medical ML for a given task. Here, we operationalize this theoretical framework by introducing a collection of data quality metrics - the metric library - for practically measuring data quality dimensions. For each metric, we provide a metric card with the most important information, including definition, applicability, examples, pitfalls and recommendations, to support the understanding and implementation of these metrics. Furthermore, we discuss strategies and provide decision trees for choosing an appropriate set of data quality metrics from the metric library given specific use cases. We demonstrate the impact of our approach exemplarily on the PTB-XL ECG-dataset. This is a first step to enable fit-for-purpose evaluation of training and test data in practice as the base for establishing trustworthy AI in medicine.
AIM 2024 Challenge on Compressed Video Quality Assessment: Methods and Results
Aug 21, 2024
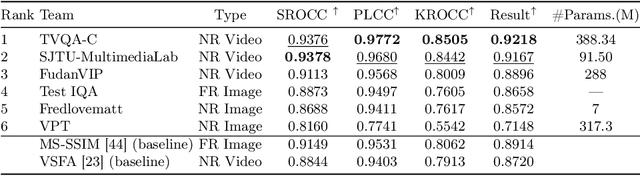
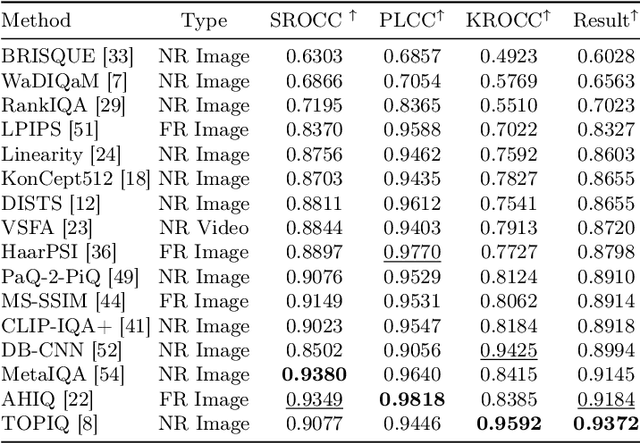
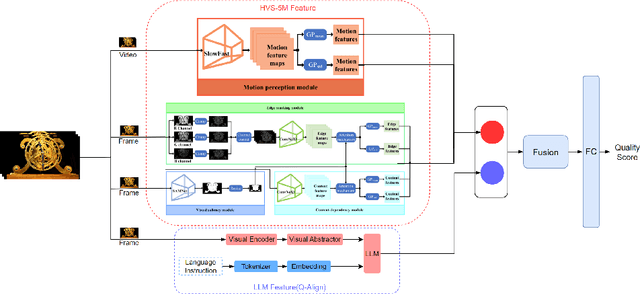
Video quality assessment (VQA) is a crucial task in the development of video compression standards, as it directly impacts the viewer experience. This paper presents the results of the Compressed Video Quality Assessment challenge, held in conjunction with the Advances in Image Manipulation (AIM) workshop at ECCV 2024. The challenge aimed to evaluate the performance of VQA methods on a diverse dataset of 459 videos, encoded with 14 codecs of various compression standards (AVC/H.264, HEVC/H.265, AV1, and VVC/H.266) and containing a comprehensive collection of compression artifacts. To measure the methods performance, we employed traditional correlation coefficients between their predictions and subjective scores, which were collected via large-scale crowdsourced pairwise human comparisons. For training purposes, participants were provided with the Compressed Video Quality Assessment Dataset (CVQAD), a previously developed dataset of 1022 videos. Up to 30 participating teams registered for the challenge, while we report the results of 6 teams, which submitted valid final solutions and code for reproducing the results. Moreover, we calculated and present the performance of state-of-the-art VQA methods on the developed dataset, providing a comprehensive benchmark for future research. The dataset, results, and online leaderboard are publicly available at https://challenges.videoprocessing.ai/challenges/compressed-video-quality-assessment.html.
Can Self-Supervised Representation Learning Methods Withstand Distribution Shifts and Corruptions?
Aug 11, 2023Self-supervised learning in computer vision aims to leverage the inherent structure and relationships within data to learn meaningful representations without explicit human annotation, enabling a holistic understanding of visual scenes. Robustness in vision machine learning ensures reliable and consistent performance, enhancing generalization, adaptability, and resistance to noise, variations, and adversarial attacks. Self-supervised paradigms, namely contrastive learning, knowledge distillation, mutual information maximization, and clustering, have been considered to have shown advances in invariant learning representations. This work investigates the robustness of learned representations of self-supervised learning approaches focusing on distribution shifts and image corruptions in computer vision. Detailed experiments have been conducted to study the robustness of self-supervised learning methods on distribution shifts and image corruptions. The empirical analysis demonstrates a clear relationship between the performance of learned representations within self-supervised paradigms and the severity of distribution shifts and corruptions. Notably, higher levels of shifts and corruptions are found to significantly diminish the robustness of the learned representations. These findings highlight the critical impact of distribution shifts and image corruptions on the performance and resilience of self-supervised learning methods, emphasizing the need for effective strategies to mitigate their adverse effects. The study strongly advocates for future research in the field of self-supervised representation learning to prioritize the key aspects of safety and robustness in order to ensure practical applicability. The source code and results are available on GitHub.
Performance of data-driven inner speech decoding with same-task EEG-fMRI data fusion and bimodal models
Jun 19, 2023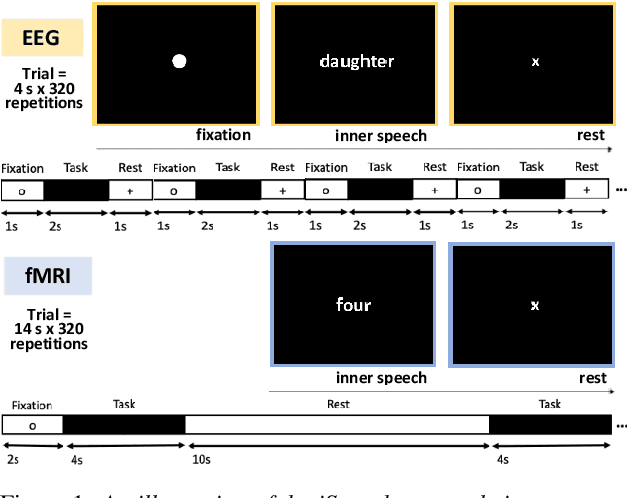
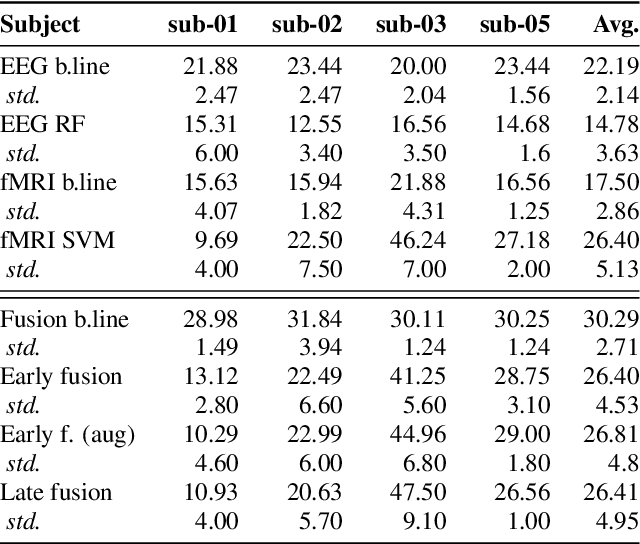
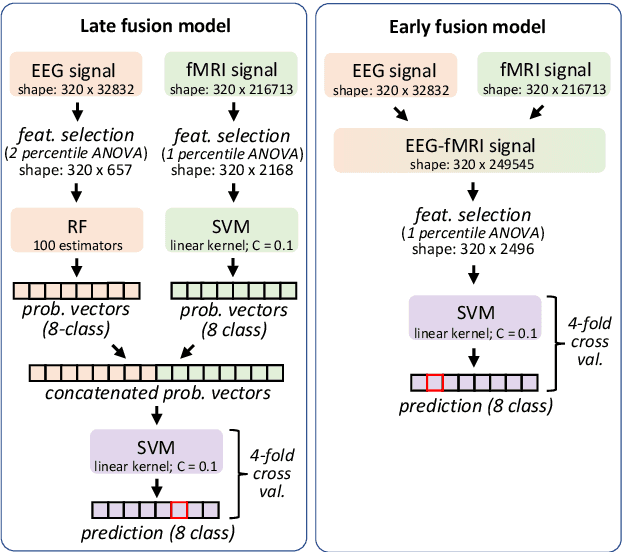
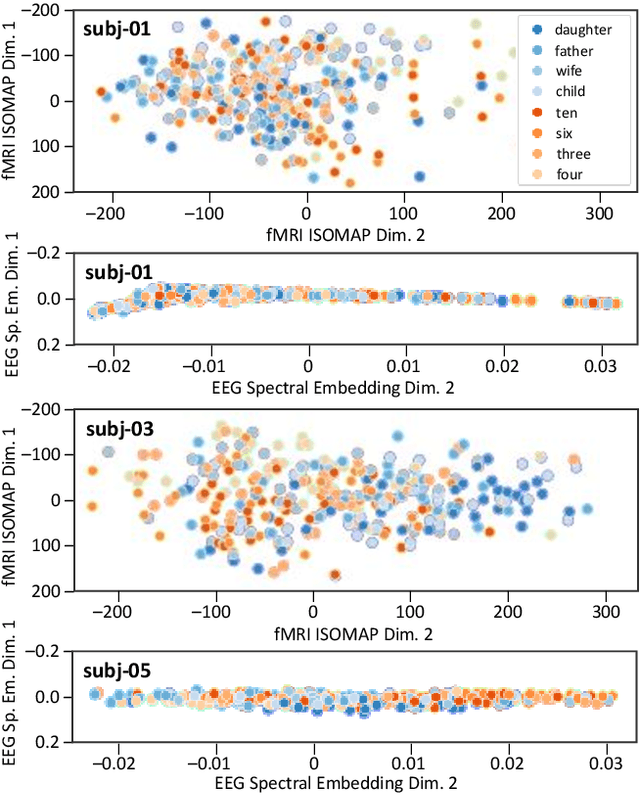
Decoding inner speech from the brain signal via hybridisation of fMRI and EEG data is explored to investigate the performance benefits over unimodal models. Two different bimodal fusion approaches are examined: concatenation of probability vectors output from unimodal fMRI and EEG machine learning models, and data fusion with feature engineering. Same task inner speech data are recorded from four participants, and different processing strategies are compared and contrasted to previously-employed hybridisation methods. Data across participants are discovered to encode different underlying structures, which results in varying decoding performances between subject-dependent fusion models. Decoding performance is demonstrated as improved when pursuing bimodal fMRI-EEG fusion strategies, if the data show underlying structure.
Nordic Vehicle Dataset (NVD): Performance of vehicle detectors using newly captured NVD from UAV in different snowy weather conditions
Apr 27, 2023
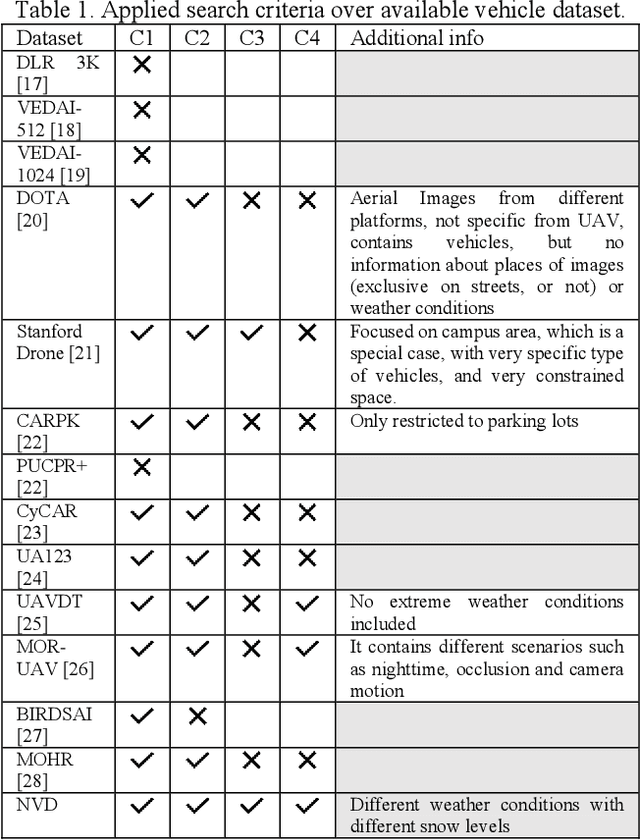
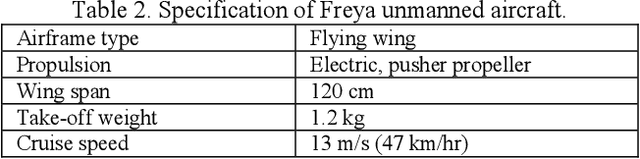
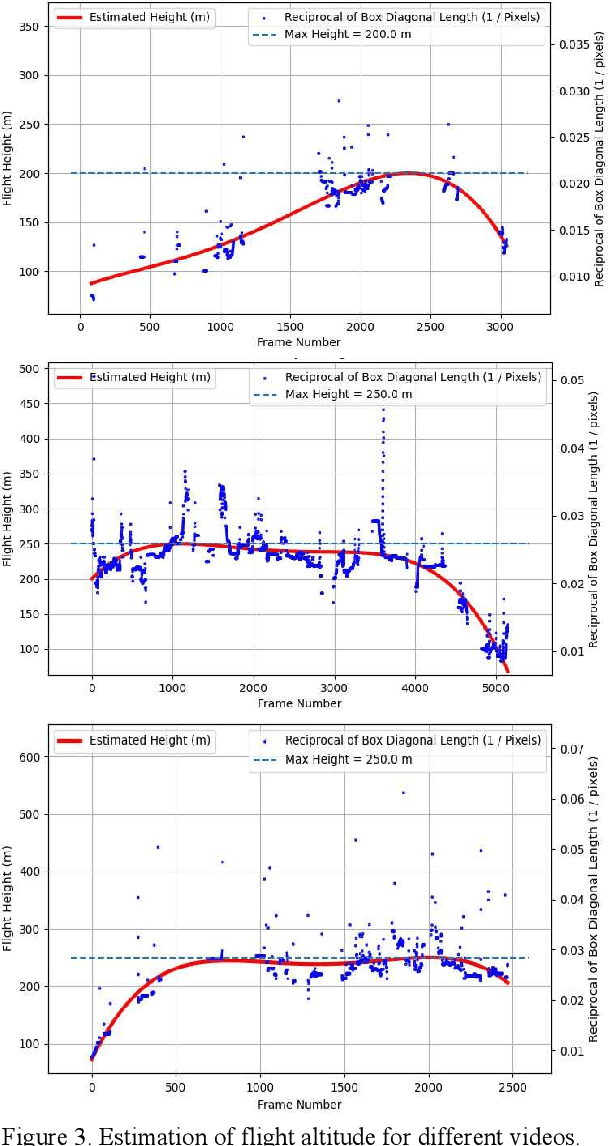
Vehicle detection and recognition in drone images is a complex problem that has been used for different safety purposes. The main challenge of these images is captured at oblique angles and poses several challenges like non-uniform illumination effect, degradations, blur, occlusion, loss of visibility, etc. Additionally, weather conditions play a crucial role in causing safety concerns and add another high level of challenge to the collected data. Over the past few decades, various techniques have been employed to detect and track vehicles in different weather conditions. However, detecting vehicles in heavy snow is still in the early stages because of a lack of available data. Furthermore, there has been no research on detecting vehicles in snowy weather using real images captured by unmanned aerial vehicles (UAVs). This study aims to address this gap by providing the scientific community with data on vehicles captured by UAVs in different settings and under various snow cover conditions in the Nordic region. The data covers different adverse weather conditions like overcast with snowfall, low light and low contrast conditions with patchy snow cover, high brightness, sunlight, fresh snow, and the temperature reaching far below -0 degrees Celsius. The study also evaluates the performance of commonly used object detection methods such as Yolo v8, Yolo v5, and fast RCNN. Additionally, data augmentation techniques are explored, and those that enhance the detectors' performance in such scenarios are proposed. The code and the dataset will be available at https://nvd.ltu-ai.dev
Functional Knowledge Transfer with Self-supervised Representation Learning
Mar 12, 2023



This work investigates the unexplored usability of self-supervised representation learning in the direction of functional knowledge transfer. In this work, functional knowledge transfer is achieved by joint optimization of self-supervised learning pseudo task and supervised learning task, improving supervised learning task performance. Recent progress in self-supervised learning uses a large volume of data, which becomes a constraint for its applications on small-scale datasets. This work shares a simple yet effective joint training framework that reinforces human-supervised task learning by learning self-supervised representations just-in-time and vice versa. Experiments on three public datasets from different visual domains, Intel Image, CIFAR, and APTOS, reveal a consistent track of performance improvements on classification tasks during joint optimization. Qualitative analysis also supports the robustness of learnt representations. Source code and trained models are available on GitHub.
Perceptual Conditional Generative Adversarial Networks for End-to-End Image Colourization
Nov 27, 2018
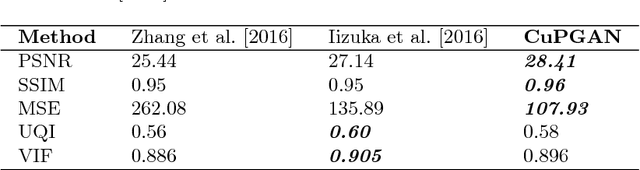
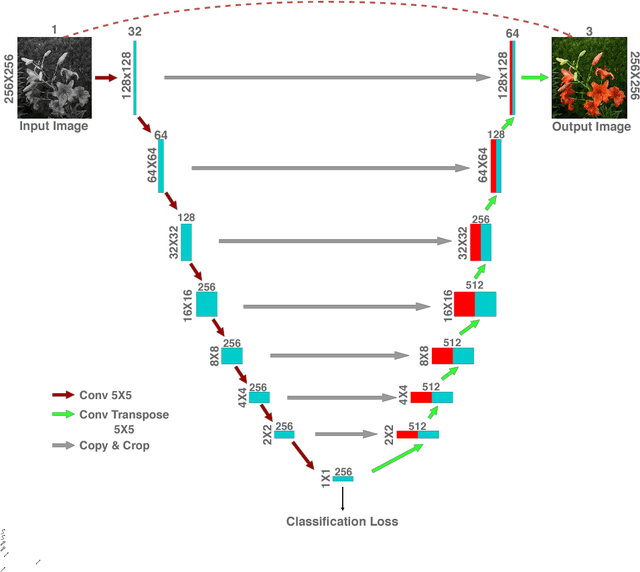
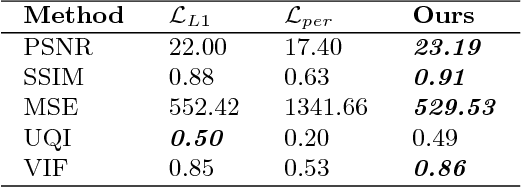
Colours are everywhere. They embody a significant part of human visual perception. In this paper, we explore the paradigm of hallucinating colours from a given gray-scale image. The problem of colourization has been dealt in previous literature but mostly in a supervised manner involving user-interference. With the emergence of Deep Learning methods numerous tasks related to computer vision and pattern recognition have been automatized and carried in an end-to-end fashion due to the availability of large data-sets and high-power computing systems. We investigate and build upon the recent success of Conditional Generative Adversarial Networks (cGANs) for Image-to-Image translations. In addition to using the training scheme in the basic cGAN, we propose an encoder-decoder generator network which utilizes the class-specific cross-entropy loss as well as the perceptual loss in addition to the original objective function of cGAN. We train our model on a large-scale dataset and present illustrative qualitative and quantitative analysis of our results. Our results vividly display the versatility and proficiency of our methods through life-like colourization outcomes.