 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Sparsity: Learning Optimal Sparse Structures in Multi-task Networks through Meta-learning
Jan 21, 2025This paper presents meta-sparsity, a framework for learning model sparsity, basically learning the parameter that controls the degree of sparsity, that allows deep neural networks (DNNs) to inherently generate optimal sparse shared structures in multi-task learning (MTL) setting. This proposed approach enables the dynamic learning of sparsity patterns across a variety of tasks, unlike traditional sparsity methods that rely heavily on manual hyperparameter tuning. Inspired by Model Agnostic Meta-Learning (MAML), the emphasis is on learning shared and optimally sparse parameters in multi-task scenarios by implementing a penalty-based, channel-wise structured sparsity during the meta-training phase. This method improves the model's efficacy by removing unnecessary parameters and enhances its ability to handle both seen and previously unseen tasks. The effectiveness of meta-sparsity is rigorously evaluated by extensive experiments on two datasets, NYU-v2 and CelebAMask-HQ, covering a broad spectrum of tasks ranging from pixel-level to image-level predictions. The results show that the proposed approach performs well across many tasks, indicating its potential as a versatile tool for creating efficient and adaptable sparse neural networks. This work, therefore, presents an approach towards learning sparsity, contributing to the efforts in the field of sparse neural networks and suggesting new directions for research towards parsimonious models.
Giving each task what it needs -- leveraging structured sparsity for tailored multi-task learning
Jun 05, 2024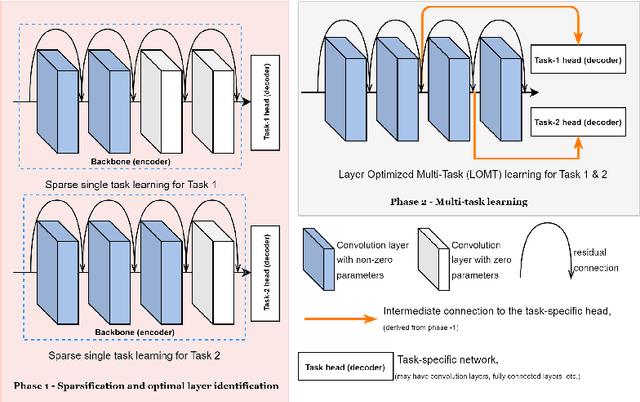
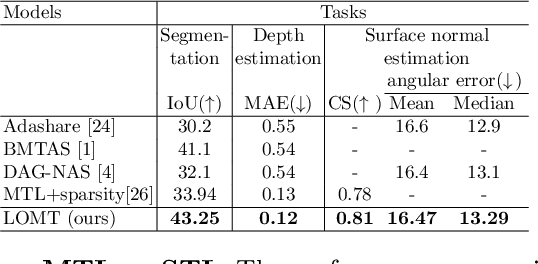


Every task demands distinct feature representations, ranging from low-level to high-level attributes, so it is vital to address the specific needs of each task, especially in the Multi-task Learning (MTL) framework. This work, therefore, introduces Layer-Optimized Multi-Task (LOMT) models that utilize structured sparsity to refine feature selection for individual tasks and enhance the performance of all tasks in a multi-task scenario. Structured or group sparsity systematically eliminates parameters from trivial channels and, eventually, entire layers within a convolution neural network during training. Consequently, the remaining layers provide the most optimal features for a given task. In this two-step approach, we subsequently leverage this sparsity-induced optimal layer information to build the LOMT models by connecting task-specific decoders to these strategically identified layers, deviating from conventional approaches that uniformly connect decoders at the end of the network. This tailored architecture optimizes the network, focusing on essential features while reducing redundancy. We validate the efficacy of the proposed approach on two datasets, ie NYU-v2 and CelebAMask-HD datasets, for multiple heterogeneous tasks. A detailed performance analysis of the LOMT models, in contrast to the conventional MTL models, reveals that the LOMT models outperform for most task combinations. The excellent qualitative and quantitative outcomes highlight the effectiveness of employing structured sparsity for optimal layer (or feature) selection.
Less is More -- Towards parsimonious multi-task models using structured sparsity
Aug 31, 2023Model sparsification in deep learning promotes simpler, more interpretable models with fewer parameters. This not only reduces the model's memory footprint and computational needs but also shortens inference time. This work focuses on creating sparse models optimized for multiple tasks with fewer parameters. These parsimonious models also possess the potential to match or outperform dense models in terms of performance. In this work, we introduce channel-wise l1/l2 group sparsity in the shared convolutional layers parameters (or weights) of the multi-task learning model. This approach facilitates the removal of extraneous groups i.e., channels (due to l1 regularization) and also imposes a penalty on the weights, further enhancing the learning efficiency for all tasks (due to l2 regularization). We analyzed the results of group sparsity in both single-task and multi-task settings on two widely-used Multi-Task Learning (MTL) datasets: NYU-v2 and CelebAMask-HQ. On both datasets, which consist of three different computer vision tasks each, multi-task models with approximately 70% sparsity outperform their dense equivalents. We also investigate how changing the degree of sparsification influences the model's performance, the overall sparsity percentage, the patterns of sparsity, and the inference time.
Functional Knowledge Transfer with Self-supervised Representation Learning
Mar 12, 2023



This work investigates the unexplored usability of self-supervised representation learning in the direction of functional knowledge transfer. In this work, functional knowledge transfer is achieved by joint optimization of self-supervised learning pseudo task and supervised learning task, improving supervised learning task performance. Recent progress in self-supervised learning uses a large volume of data, which becomes a constraint for its applications on small-scale datasets. This work shares a simple yet effective joint training framework that reinforces human-supervised task learning by learning self-supervised representations just-in-time and vice versa. Experiments on three public datasets from different visual domains, Intel Image, CIFAR, and APTOS, reveal a consistent track of performance improvements on classification tasks during joint optimization. Qualitative analysis also supports the robustness of learnt representations. Source code and trained models are available on GitHub.
Depth Contrast: Self-Supervised Pretraining on 3DPM Images for Mining Material Classification
Oct 18, 2022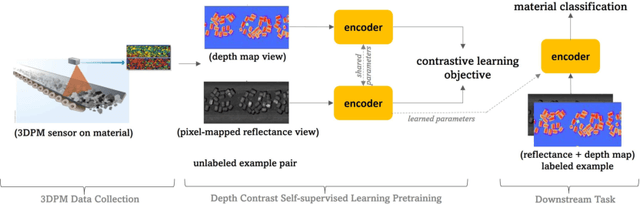
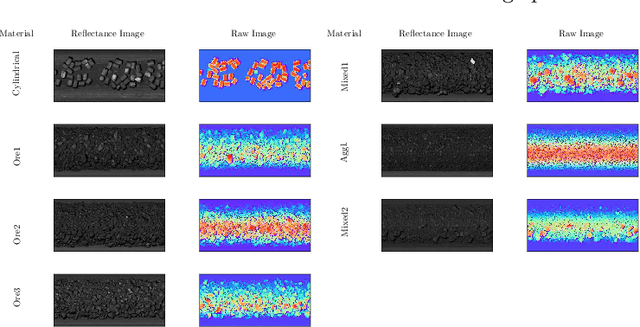
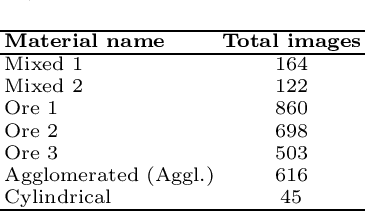
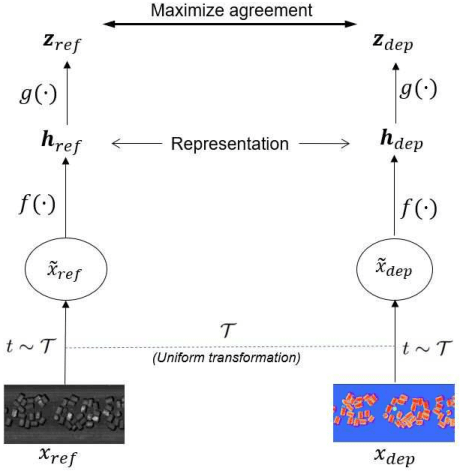
This work presents a novel self-supervised representation learning method to learn efficient representations without labels on images from a 3DPM sensor (3-Dimensional Particle Measurement; estimates the particle size distribution of material) utilizing RGB images and depth maps of mining material on the conveyor belt. Human annotations for material categories on sensor-generated data are scarce and cost-intensive. Currently, representation learning without human annotations remains unexplored for mining materials and does not leverage on utilization of sensor-generated data. The proposed method, Depth Contrast, enables self-supervised learning of representations without labels on the 3DPM dataset by exploiting depth maps and inductive transfer. The proposed method outperforms material classification over ImageNet transfer learning performance in fully supervised learning settings and achieves an F1 score of 0.73. Further, The proposed method yields an F1 score of 0.65 with an 11% improvement over ImageNet transfer learning performance in a semi-supervised setting when only 20% of labels are used in fine-tuning. Finally, the Proposed method showcases improved performance generalization on linear evaluation. The implementation of proposed method is available on GitHub.
Multi-Task Meta Learning: learn how to adapt to unseen tasks
Oct 13, 2022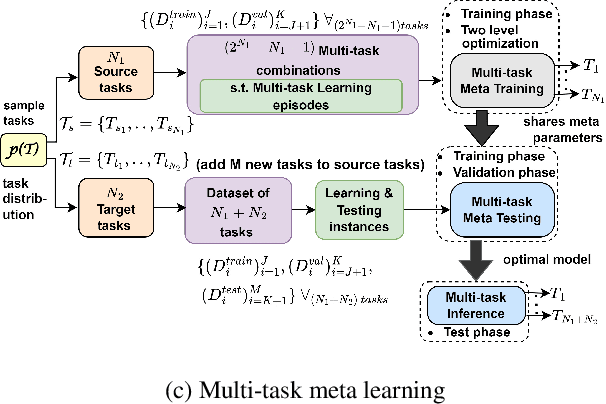
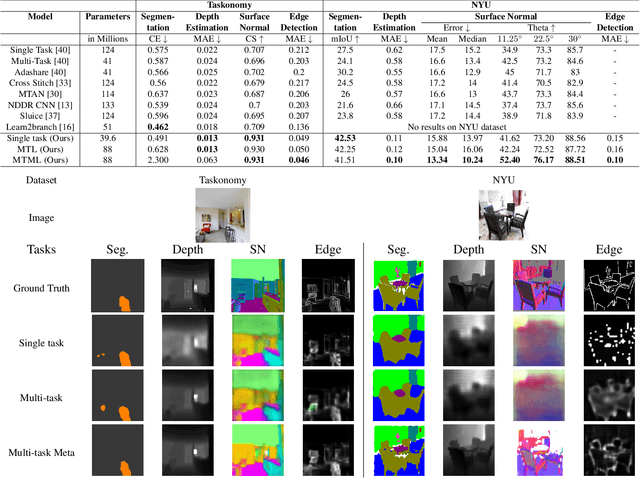
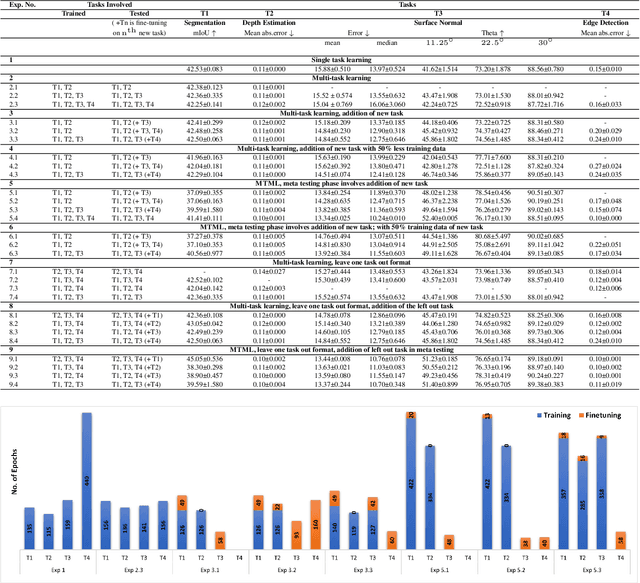
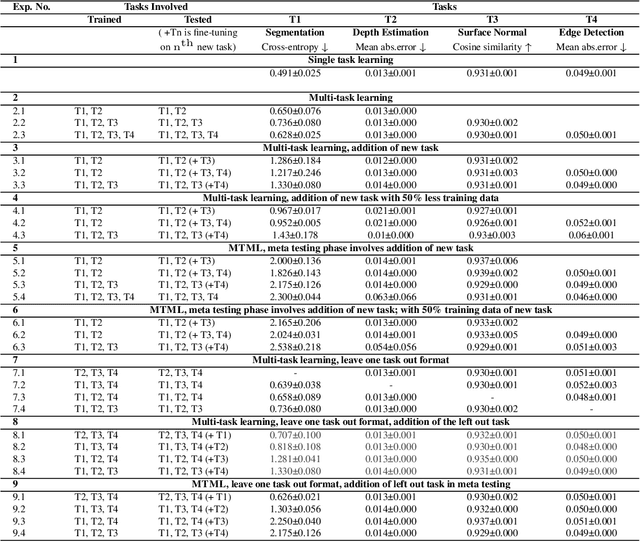
This work aims to integrate two learning paradigms Multi-Task Learning (MTL) and meta learning, to bring together the best of both worlds, i.e., simultaneous learning of multiple tasks, an element of MTL and promptly adapting to new tasks with fewer data, a quality of meta learning. We propose Multi-task Meta Learning (MTML), an approach to enhance MTL compared to single task learning by employing meta learning. The fundamental idea of this work is to train a multi-task model, such that when an unseen task is introduced, it can learn in fewer steps whilst offering a performance at least as good as conventional single task learning on the new task or inclusion within the MTL. By conducting various experiments, we demonstrate this paradigm on two datasets and four tasks: NYU-v2 and the taskonomy dataset for which we perform semantic segmentation, depth estimation, surface normal estimation, and edge detection. MTML achieves state-of-the-art results for most of the tasks, and MTL also performs reasonably well for all tasks compared to single task learning.
Magnification Prior: A Self-Supervised Method for Learning Representations on Breast Cancer Histopathological Images
Mar 15, 2022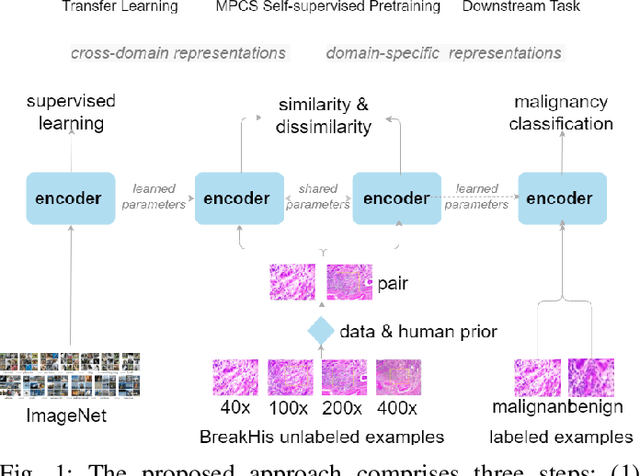
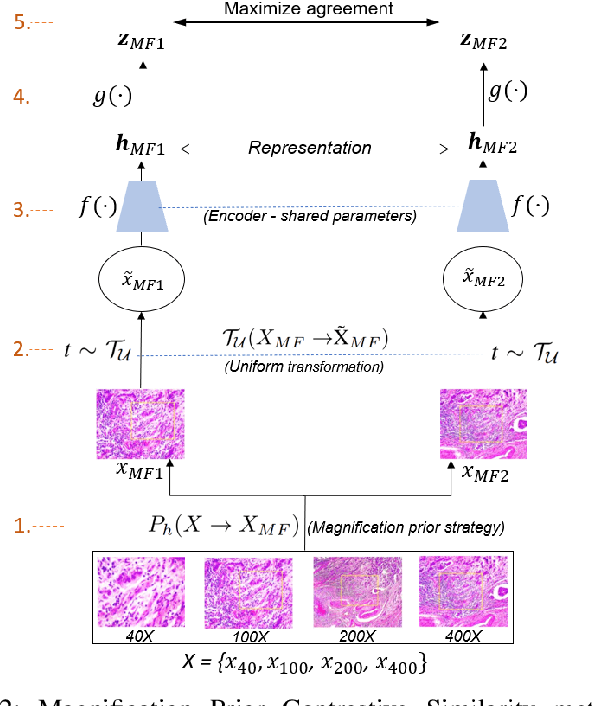
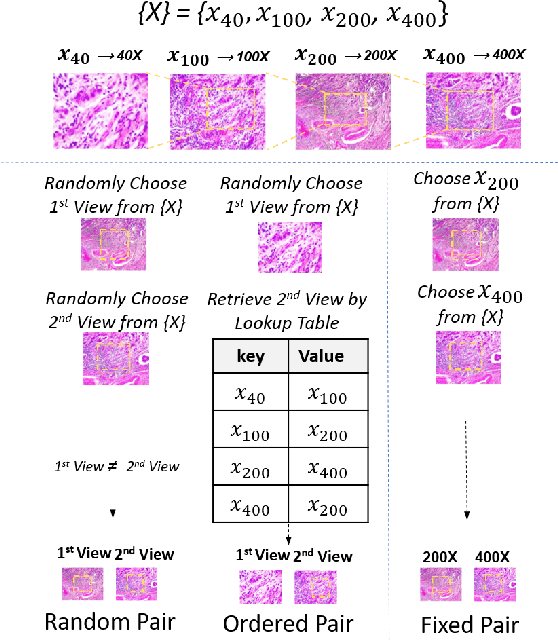
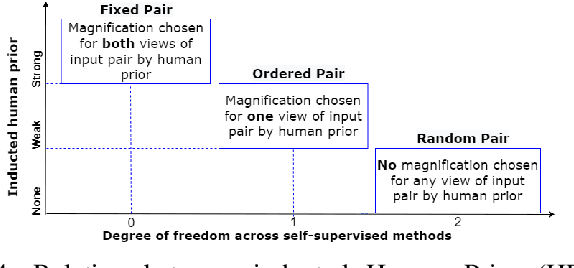
This work presents a novel self-supervised pre-training method to learn efficient representations without labels on histopathology medical images utilizing magnification factors. Other state-of-theart works mainly focus on fully supervised learning approaches that rely heavily on human annotations. However, the scarcity of labeled and unlabeled data is a long-standing challenge in histopathology. Currently, representation learning without labels remains unexplored for the histopathology domain. The proposed method, Magnification Prior Contrastive Similarity (MPCS), enables self-supervised learning of representations without labels on small-scale breast cancer dataset BreakHis by exploiting magnification factor, inductive transfer, and reducing human prior. The proposed method matches fully supervised learning state-of-the-art performance in malignancy classification when only 20% of labels are used in fine-tuning and outperform previous works in fully supervised learning settings. It formulates a hypothesis and provides empirical evidence to support that reducing human-prior leads to efficient representation learning in self-supervision. The implementation of this work is available online on GitHub - https://github.com/prakashchhipa/Magnification-Prior-Self-Supervised-Method
Sharing to learn and learning to share - Fitting together Meta-Learning, Multi-Task Learning, and Transfer Learning : A meta review
Nov 23, 2021

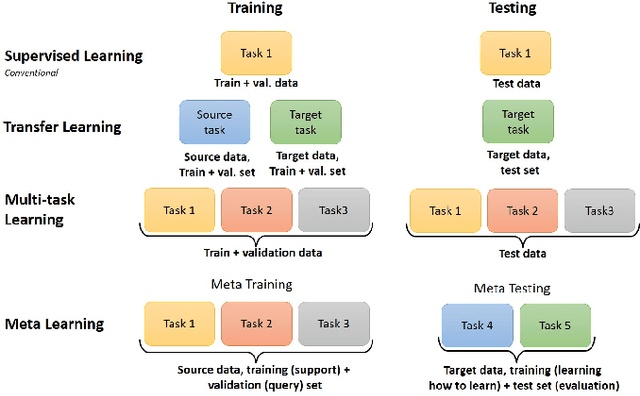
Integrating knowledge across different domains is an essential feature of human learning. Learning paradigms like transfer learning, meta learning, and multi-task learning reflect the human learning process by exploiting the prior knowledge for new tasks, encouraging faster learning and good generalization for new tasks. This article gives a detailed view of these learning paradigms along with a comparative analysis. The weakness of a learning algorithm turns out to be the strength of another, and thereby merging them is a prevalent trait in the literature. This work delivers a literature review of the articles, which fuses two algorithms to accomplish multiple tasks. A global generic learning network, an ensemble of meta learning, transfer learning, and multi-task learning, is also introduced here, along with some open research questions and directions for future research.