 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiving each task what it needs -- leveraging structured sparsity for tailored multi-task learning
Paper and Code
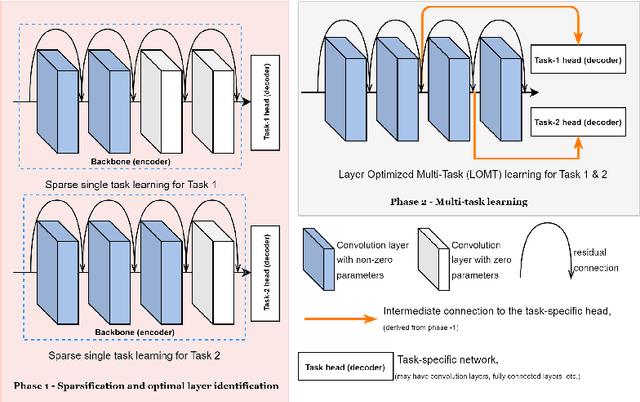
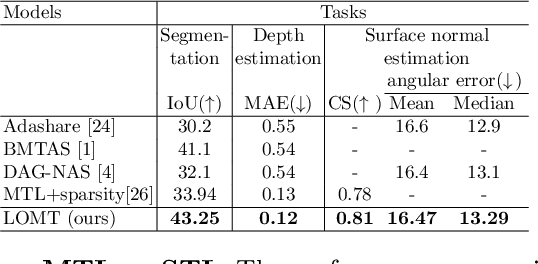


Every task demands distinct feature representations, ranging from low-level to high-level attributes, so it is vital to address the specific needs of each task, especially in the Multi-task Learning (MTL) framework. This work, therefore, introduces Layer-Optimized Multi-Task (LOMT) models that utilize structured sparsity to refine feature selection for individual tasks and enhance the performance of all tasks in a multi-task scenario. Structured or group sparsity systematically eliminates parameters from trivial channels and, eventually, entire layers within a convolution neural network during training. Consequently, the remaining layers provide the most optimal features for a given task. In this two-step approach, we subsequently leverage this sparsity-induced optimal layer information to build the LOMT models by connecting task-specific decoders to these strategically identified layers, deviating from conventional approaches that uniformly connect decoders at the end of the network. This tailored architecture optimizes the network, focusing on essential features while reducing redundancy. We validate the efficacy of the proposed approach on two datasets, ie NYU-v2 and CelebAMask-HD datasets, for multiple heterogeneous tasks. A detailed performance analysis of the LOMT models, in contrast to the conventional MTL models, reveals that the LOMT models outperform for most task combinations. The excellent qualitative and quantitative outcomes highlight the effectiveness of employing structured sparsity for optimal layer (or feature) selection.