 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth-edged Perturbations Improve Perturbation-based Image Explanations
Sep 06, 2024Perturbation-based post-hoc image explanation methods are commonly used to explain image prediction models by perturbing parts of the input to measure how those parts affect the output. Due to the intractability of perturbing each pixel individually, images are typically attributed to larger segments. The Randomized Input Sampling for Explanations (RISE) method solved this issue by using smooth perturbation masks. While this method has proven effective and popular, it has not been investigated which parts of the method are responsible for its success. This work tests many combinations of mask sampling, segmentation techniques, smoothing, and attribution calculation. The results show that the RISE-style pixel attribution is beneficial to all evaluated methods. Furthermore, it is shown that attribution calculation is the least impactful parameter. The implementation of this work is available online: https://github.com/guspih/post-hoc-image-perturbation.
Deep Perceptual Similarity is Adaptable to Ambiguous Contexts
Apr 05, 2023



The concept of image similarity is ambiguous, meaning that images that are considered similar in one context might not be in another. This ambiguity motivates the creation of metrics for specific contexts. This work explores the ability of the successful deep perceptual similarity (DPS) metrics to adapt to a given context. Recently, DPS metrics have emerged using the deep features of neural networks for comparing images. These metrics have been successful on datasets that leverage the average human perception in limited settings. But the question remains if they could be adapted to specific contexts of similarity. No single metric can suit all definitions of similarity and previous metrics have been rule-based which are labor intensive to rewrite for new contexts. DPS metrics, on the other hand, use neural networks which might be retrained for each context. However, retraining networks takes resources and might ruin performance on previous tasks. This work examines the adaptability of DPS metrics by training positive scalars for the deep features of pretrained CNNs to correctly measure similarity for different contexts. Evaluation is performed on contexts defined by randomly ordering six image distortions (e.g. rotation) by which should be considered more similar when applied to an image. This also gives insight into whether the features in the CNN is enough to discern different distortions without retraining. Finally, the trained metrics are evaluated on a perceptual similarity dataset to evaluate if adapting to an ordering affects their performance on established scenarios. The findings show that DPS metrics can be adapted with high performance. While the adapted metrics have difficulties with the same contexts as baselines, performance is improved in 99% of cases. Finally, it is shown that the adaption is not significantly detrimental to prior performance on perceptual similarity.
A Systematic Performance Analysis of Deep Perceptual Loss Networks Breaks Transfer Learning Conventions
Feb 08, 2023Deep perceptual loss is a type of loss function in computer vision that aims to mimic human perception by using the deep features extracted from neural networks. In recent years the method has been applied to great effect on a host of interesting computer vision tasks, especially for tasks with image or image-like outputs. Many applications of the method use pretrained networks, often convolutional networks, for loss calculation. Despite the increased interest and broader use, more effort is needed toward exploring which networks to use for calculating deep perceptual loss and from which layers to extract the features. This work aims to rectify this by systematically evaluating a host of commonly used and readily available, pretrained networks for a number of different feature extraction points on four existing use cases of deep perceptual loss. The four use cases are implementations of previous works where the selected networks and extraction points are evaluated instead of the networks and extraction points used in the original work. The experimental tasks are dimensionality reduction, image segmentation, super-resolution, and perceptual similarity. The performance on these four tasks, attributes of the networks, and extraction points are then used as a basis for an in-depth analysis. This analysis uncovers essential information regarding which architectures provide superior performance for deep perceptual loss and how to choose an appropriate extraction point for a particular task and dataset. Furthermore, the work discusses the implications of the results for deep perceptual loss and the broader field of transfer learning. The results break commonly held assumptions in transfer learning, which imply that deep perceptual loss deviates from most transfer learning settings or that these assumptions need a thorough re-evaluation.
Identifying and Mitigating Flaws of Deep Perceptual Similarity Metrics
Jul 06, 2022


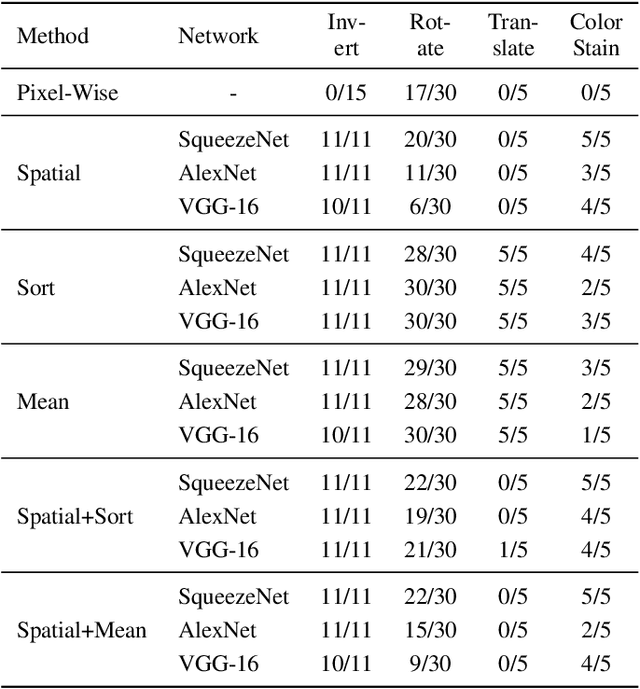
Measuring the similarity of images is a fundamental problem to computer vision for which no universal solution exists. While simple metrics such as the pixel-wise L2-norm have been shown to have significant flaws, they remain popular. One group of recent state-of-the-art metrics that mitigates some of those flaws are Deep Perceptual Similarity (DPS) metrics, where the similarity is evaluated as the distance in the deep features of neural networks. However, DPS metrics themselves have been less thoroughly examined for their benefits and, especially, their flaws. This work investigates the most common DPS metric, where deep features are compared by spatial position, along with metrics comparing the averaged and sorted deep features. The metrics are analyzed in-depth to understand the strengths and weaknesses of the metrics by using images designed specifically to challenge them. This work contributes with new insights into the flaws of DPS, and further suggests improvements to the metrics. An implementation of this work is available online: https://github.com/guspih/deep_perceptual_similarity_analysis/
Magnification Prior: A Self-Supervised Method for Learning Representations on Breast Cancer Histopathological Images
Mar 15, 2022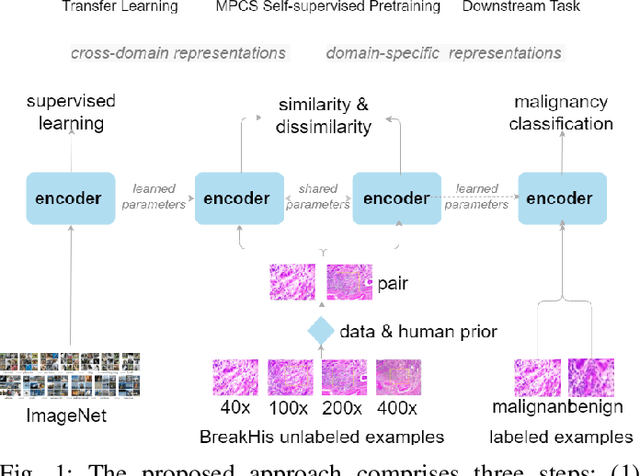
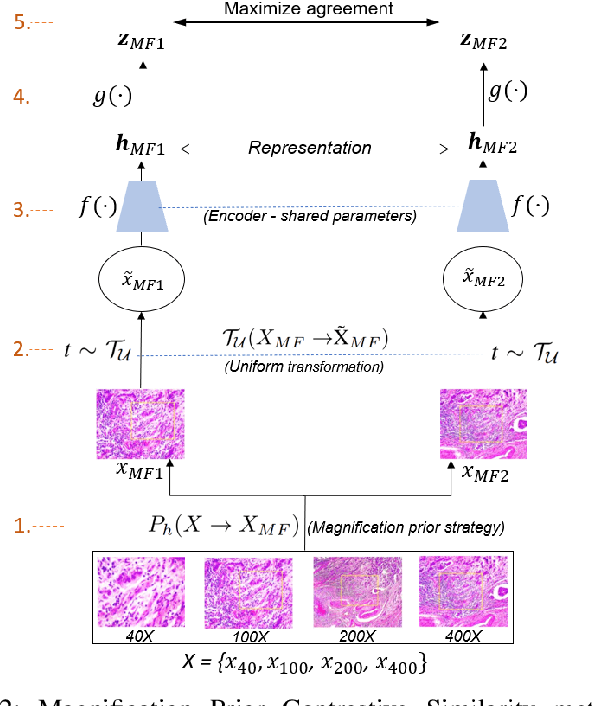
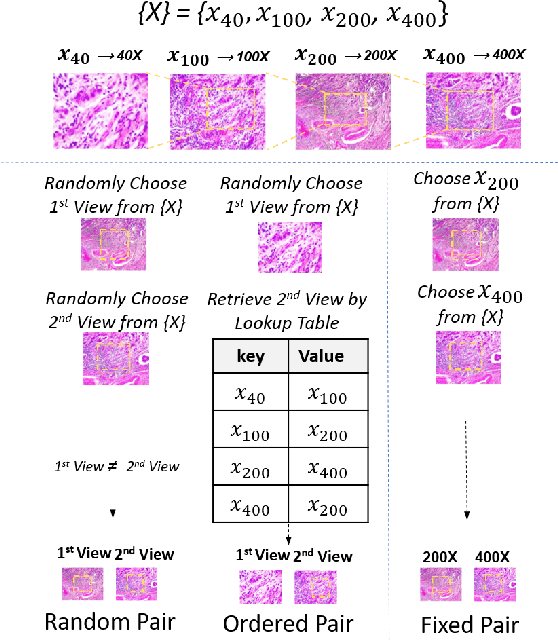
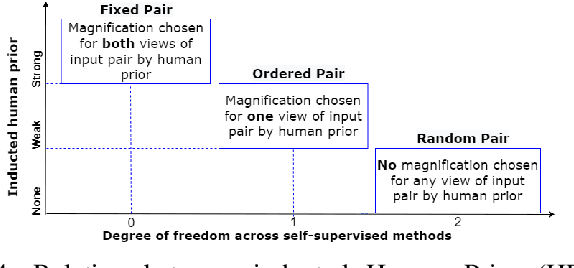
This work presents a novel self-supervised pre-training method to learn efficient representations without labels on histopathology medical images utilizing magnification factors. Other state-of-theart works mainly focus on fully supervised learning approaches that rely heavily on human annotations. However, the scarcity of labeled and unlabeled data is a long-standing challenge in histopathology. Currently, representation learning without labels remains unexplored for the histopathology domain. The proposed method, Magnification Prior Contrastive Similarity (MPCS), enables self-supervised learning of representations without labels on small-scale breast cancer dataset BreakHis by exploiting magnification factor, inductive transfer, and reducing human prior. The proposed method matches fully supervised learning state-of-the-art performance in malignancy classification when only 20% of labels are used in fine-tuning and outperform previous works in fully supervised learning settings. It formulates a hypothesis and provides empirical evidence to support that reducing human-prior leads to efficient representation learning in self-supervision. The implementation of this work is available online on GitHub - https://github.com/prakashchhipa/Magnification-Prior-Self-Supervised-Method
Pretraining Image Encoders without Reconstruction via Feature Prediction Loss
Mar 16, 2020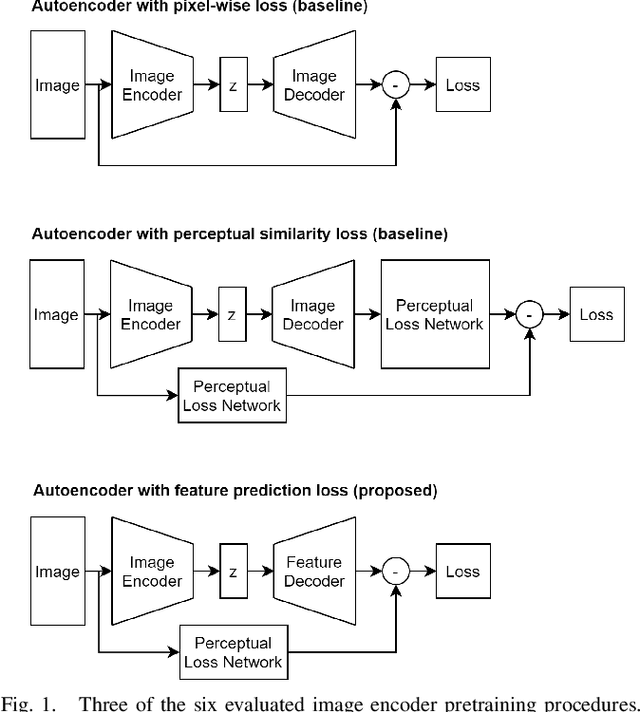

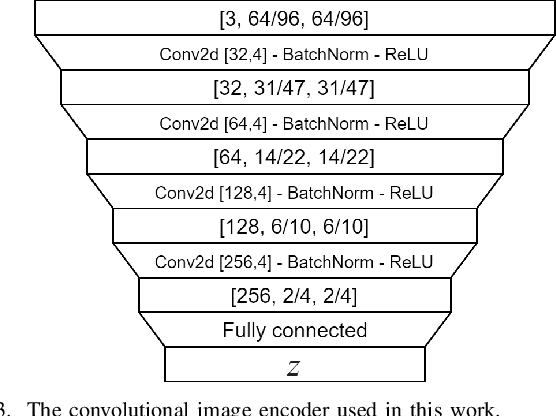
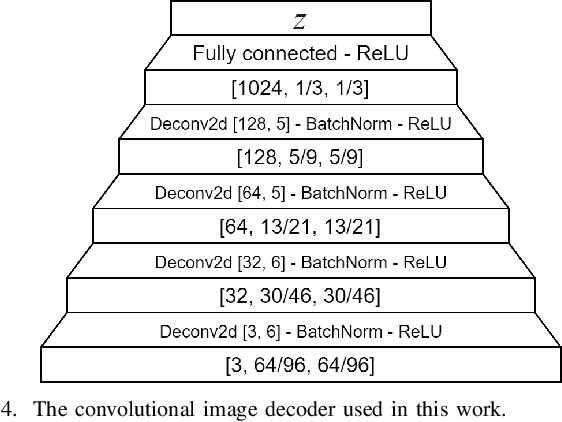
This work investigates three different loss functions for autoencoder-based pretraining of image encoders: The commonly used reconstruction loss, the more recently introduced perceptual similarity loss, and a feature prediction loss proposed here; the latter turning out to be the most efficient choice. Former work shows that predictions based on embeddings generated by image autoencoders can be improved by training with perceptual loss. So far the autoencoders trained with perceptual loss networks implemented an explicit comparison of the original and reconstructed images using the loss network. However, given such a loss network we show that there is no need for the timeconsuming task of decoding the entire image. Instead, we propose to decode the features of the loss network, hence the name "feature prediction loss". To evaluate this method we compare six different procedures for training image encoders based on pixel-wise, perceptual similarity, and feature prediction loss. The embedding-based prediction results show that encoders trained with feature prediction loss is as good or better than those trained with the other two losses. Additionally, the encoder is significantly faster to train using feature prediction loss in comparison to the other losses. The method implementation used in this work is available online: https://github.com/guspih/Perceptual-Autoencoders
Improving Image Autoencoder Embeddings with Perceptual Loss
Jan 10, 2020



Autoencoders are commonly trained using element-wise loss. However, element-wise loss disregards high-level structures in the image which can lead to embeddings that disregard them as well. A recent improvement to autoencoders that help alleviate this problem is the use of perceptual loss. This work investigate perceptual loss from the perspective of encoder embeddings themselves. Autoencoders are trained to embed images from three different computer vision datasets using perceptual loss based on a pretrained model as well as pixel-wise loss. A host of different predictors are trained to perform object positioning and classification on the datasets given the embedded images as input. The two kinds of losses are evaluated by comparing how the predictors performed with embeddings from the differently trained autoencoders. The results show that, in the image domain, the embeddings generated by autoencoders trained with perceptual loss enable more accurate predictions than those trained with element-wise loss. Furthermore, the results show that, on the task of object-positioning of a small-scale feature, perceptual loss can improve the results by a factor 10. The experimental setup is available online: https://github.com/guspih/Perceptual-Autoencoders