 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-based Condition Monitoring Assistance with Multimodal Industrial Database Retrieval Augmented Generation
Jun 10, 2025Condition monitoring (CM) plays a crucial role in ensuring reliability and efficiency in the process industry. Although computerised maintenance systems effectively detect and classify faults, tasks like fault severity estimation, and maintenance decisions still largely depend on human expert analysis. The analysis and decision making automatically performed by current systems typically exhibit considerable uncertainty and high false alarm rates, leading to increased workload and reduced efficiency. This work integrates large language model (LLM)-based reasoning agents with CM workflows to address analyst and industry needs, namely reducing false alarms, enhancing fault severity estimation, improving decision support, and offering explainable interfaces. We propose MindRAG, a modular framework combining multimodal retrieval-augmented generation (RAG) with novel vector store structures designed specifically for CM data. The framework leverages existing annotations and maintenance work orders as surrogates for labels in a supervised learning protocol, addressing the common challenge of training predictive models on unlabelled and noisy real-world datasets. The primary contributions include: (1) an approach for structuring industry CM data into a semi-structured multimodal vector store compatible with LLM-driven workflows; (2) developing multimodal RAG techniques tailored for CM data; (3) developing practical reasoning agents capable of addressing real-world CM queries; and (4) presenting an experimental framework for integrating and evaluating such agents in realistic industrial scenarios. Preliminary results, evaluated with the help of an experienced analyst, indicate that MindRAG provide meaningful decision support for more efficient management of alarms, thereby improving the interpretability of CM systems.
Neuromorphic Readout for Hadron Calorimeters
Feb 18, 2025We simulate hadrons impinging on a homogeneous lead-tungstate (PbWO4) calorimeter to investigate how the resulting light yield and its temporal structure, as detected by an array of light-sensitive sensors, can be processed by a neuromorphic computing system. Our model encodes temporal photon distributions as spike trains and employs a fully connected spiking neural network to estimate the total deposited energy, as well as the position and spatial distribution of the light emissions within the sensitive material. The extracted primitives offer valuable topological information about the shower development in the material, achieved without requiring a segmentation of the active medium. A potential nanophotonic implementation using III-V semiconductor nanowires is discussed. It can be both fast and energy efficient.
Unsupervised Particle Tracking with Neuromorphic Computing
Feb 10, 2025



We study the application of a neural network architecture for identifying charged particle trajectories via unsupervised learning of delays and synaptic weights using a spike-time-dependent plasticity rule. In the considered model, the neurons receive time-encoded information on the position of particle hits in a tracking detector for a particle collider, modeled according to the geometry of the Compact Muon Solenoid Phase II detector. We show how a spiking neural network is capable of successfully identifying in a completely unsupervised way the signal left by charged particles in the presence of conspicuous noise from accidental or combinatorial hits. These results open the way to applications of neuromorphic computing to particle tracking, motivating further studies into its potential for real-time, low-power particle tracking in future high-energy physics experiments.
Learning the Approach During the Short-loading Cycle Using Reinforcement Learning
Jun 19, 2024The short-loading cycle is a repetitive task performed in high quantities, making it a great alternative for automation. In the short-loading cycle, an expert operator navigates towards a pile, fills the bucket with material, navigates to a dump truck, and dumps the material into the tipping body. The operator has to balance the productivity goal while minimising the fuel usage, to maximise the overall efficiency of the cycle. In addition, difficult interactions, such as the tyre-to-surface interaction further complicate the cycle. These types of hard-to-model interactions that can be difficult to address with rule-based systems, together with the efficiency requirements, motivate us to examine the potential of data-driven approaches. In this paper, the possibility of teaching an agent through reinforcement learning to approach a dump truck's tipping body and get in position to dump material in the tipping body is examined. The agent is trained in a 3D simulated environment to perform a simplified navigation task. The trained agent is directly transferred to a real vehicle, to perform the same task, with no additional training. The results indicate that the agent can successfully learn to navigate towards the dump truck with a limited amount of control signals in simulation and when transferred to a real vehicle, exhibits the correct behaviour.
ReLU and Addition-based Gated RNN
Aug 10, 2023We replace the multiplication and sigmoid function of the conventional recurrent gate with addition and ReLU activation. This mechanism is designed to maintain long-term memory for sequence processing but at a reduced computational cost, thereby opening up for more efficient execution or larger models on restricted hardware. Recurrent Neural Networks (RNNs) with gating mechanisms such as LSTM and GRU have been widely successful in learning from sequential data due to their ability to capture long-term dependencies. Conventionally, the update based on current inputs and the previous state history is each multiplied with dynamic weights and combined to compute the next state. However, multiplication can be computationally expensive, especially for certain hardware architectures or alternative arithmetic systems such as homomorphic encryption. It is demonstrated that the novel gating mechanism can capture long-term dependencies for a standard synthetic sequence learning task while significantly reducing computational costs such that execution time is reduced by half on CPU and by one-third under encryption. Experimental results on handwritten text recognition tasks furthermore show that the proposed architecture can be trained to achieve comparable accuracy to conventional GRU and LSTM baselines. The gating mechanism introduced in this paper may enable privacy-preserving AI applications operating under homomorphic encryption by avoiding the multiplication of encrypted variables. It can also support quantization in (unencrypted) plaintext applications, with the potential for substantial performance gains since the addition-based formulation can avoid the expansion to double precision often required for multiplication.
Deep Perceptual Similarity is Adaptable to Ambiguous Contexts
Apr 05, 2023



The concept of image similarity is ambiguous, meaning that images that are considered similar in one context might not be in another. This ambiguity motivates the creation of metrics for specific contexts. This work explores the ability of the successful deep perceptual similarity (DPS) metrics to adapt to a given context. Recently, DPS metrics have emerged using the deep features of neural networks for comparing images. These metrics have been successful on datasets that leverage the average human perception in limited settings. But the question remains if they could be adapted to specific contexts of similarity. No single metric can suit all definitions of similarity and previous metrics have been rule-based which are labor intensive to rewrite for new contexts. DPS metrics, on the other hand, use neural networks which might be retrained for each context. However, retraining networks takes resources and might ruin performance on previous tasks. This work examines the adaptability of DPS metrics by training positive scalars for the deep features of pretrained CNNs to correctly measure similarity for different contexts. Evaluation is performed on contexts defined by randomly ordering six image distortions (e.g. rotation) by which should be considered more similar when applied to an image. This also gives insight into whether the features in the CNN is enough to discern different distortions without retraining. Finally, the trained metrics are evaluated on a perceptual similarity dataset to evaluate if adapting to an ordering affects their performance on established scenarios. The findings show that DPS metrics can be adapted with high performance. While the adapted metrics have difficulties with the same contexts as baselines, performance is improved in 99% of cases. Finally, it is shown that the adaption is not significantly detrimental to prior performance on perceptual similarity.
A Systematic Performance Analysis of Deep Perceptual Loss Networks Breaks Transfer Learning Conventions
Feb 08, 2023Deep perceptual loss is a type of loss function in computer vision that aims to mimic human perception by using the deep features extracted from neural networks. In recent years the method has been applied to great effect on a host of interesting computer vision tasks, especially for tasks with image or image-like outputs. Many applications of the method use pretrained networks, often convolutional networks, for loss calculation. Despite the increased interest and broader use, more effort is needed toward exploring which networks to use for calculating deep perceptual loss and from which layers to extract the features. This work aims to rectify this by systematically evaluating a host of commonly used and readily available, pretrained networks for a number of different feature extraction points on four existing use cases of deep perceptual loss. The four use cases are implementations of previous works where the selected networks and extraction points are evaluated instead of the networks and extraction points used in the original work. The experimental tasks are dimensionality reduction, image segmentation, super-resolution, and perceptual similarity. The performance on these four tasks, attributes of the networks, and extraction points are then used as a basis for an in-depth analysis. This analysis uncovers essential information regarding which architectures provide superior performance for deep perceptual loss and how to choose an appropriate extraction point for a particular task and dataset. Furthermore, the work discusses the implications of the results for deep perceptual loss and the broader field of transfer learning. The results break commonly held assumptions in transfer learning, which imply that deep perceptual loss deviates from most transfer learning settings or that these assumptions need a thorough re-evaluation.
A Comparison of Temporal Encoders for Neuromorphic Keyword Spotting with Few Neurons
Jan 24, 2023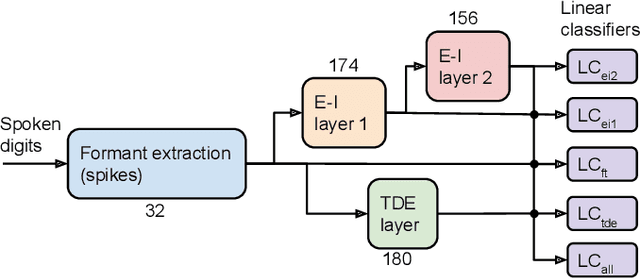
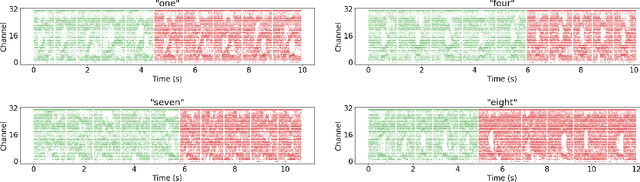
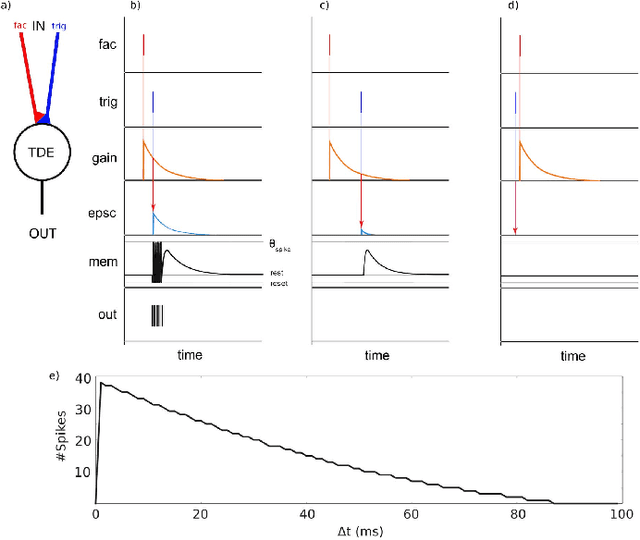
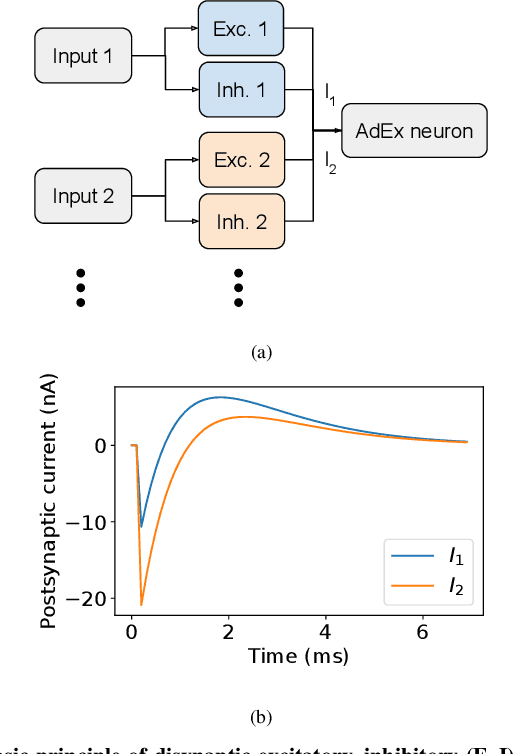
With the expansion of AI-powered virtual assistants, there is a need for low-power keyword spotting systems providing a "wake-up" mechanism for subsequent computationally expensive speech recognition. One promising approach is the use of neuromorphic sensors and spiking neural networks (SNNs) implemented in neuromorphic processors for sparse event-driven sensing. However, this requires resource-efficient SNN mechanisms for temporal encoding, which need to consider that these systems process information in a streaming manner, with physical time being an intrinsic property of their operation. In this work, two candidate neurocomputational elements for temporal encoding and feature extraction in SNNs described in recent literature - the spiking time-difference encoder (TDE) and disynaptic excitatory-inhibitory (E-I) elements - are comparatively investigated in a keyword-spotting task on formants computed from spoken digits in the TIDIGITS dataset. While both encoders improve performance over direct classification of the formant features in the training data, enabling a complete binary classification with a logistic regression model, they show no clear improvements on the test set. Resource-efficient keyword spotting applications may benefit from the use of these encoders, but further work on methods for learning the time constants and weights is required to investigate their full potential.
Integration of Neuromorphic AI in Event-Driven Distributed Digitized Systems: Concepts and Research Directions
Oct 20, 2022
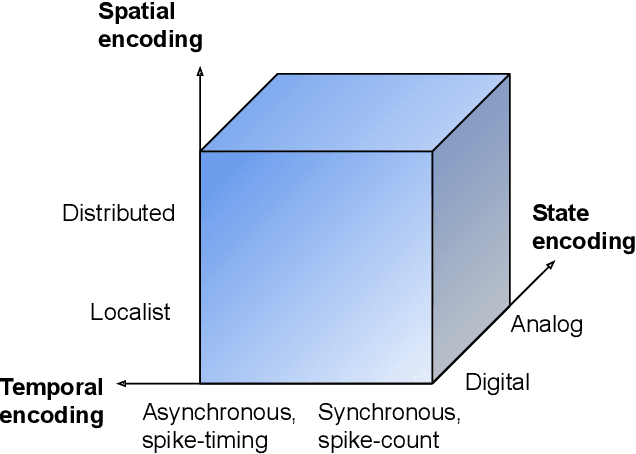
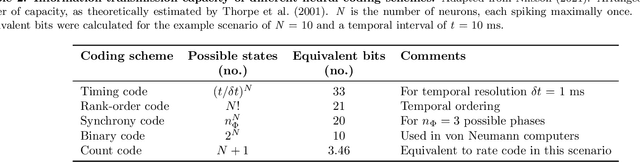
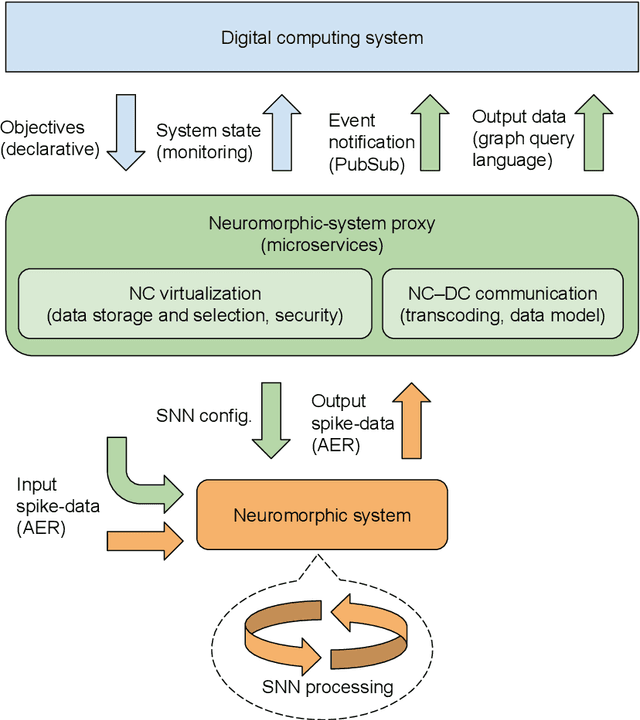
Increasing complexity and data-generation rates in cyber-physical systems and the industrial Internet of things are calling for a corresponding increase in AI capabilities at the resource-constrained edges of the Internet. Meanwhile, the resource requirements of digital computing and deep learning are growing exponentially, in an unsustainable manner. One possible way to bridge this gap is the adoption of resource-efficient brain-inspired "neuromorphic" processing and sensing devices, which use event-driven, asynchronous, dynamic neurosynaptic elements with colocated memory for distributed processing and machine learning. However, since neuromorphic systems are fundamentally different from conventional von Neumann computers and clock-driven sensor systems, several challenges are posed to large-scale adoption and integration of neuromorphic devices into the existing distributed digital-computational infrastructure. Here, we describe the current landscape of neuromorphic computing, focusing on characteristics that pose integration challenges. Based on this analysis, we propose a microservice-based framework for neuromorphic systems integration, consisting of a neuromorphic-system proxy, which provides virtualization and communication capabilities required in distributed systems of systems, in combination with a declarative programming approach offering engineering-process abstraction. We also present concepts that could serve as a basis for the realization of this framework, and identify directions for further research required to enable large-scale system integration of neuromorphic devices.
Identifying and Mitigating Flaws of Deep Perceptual Similarity Metrics
Jul 06, 2022


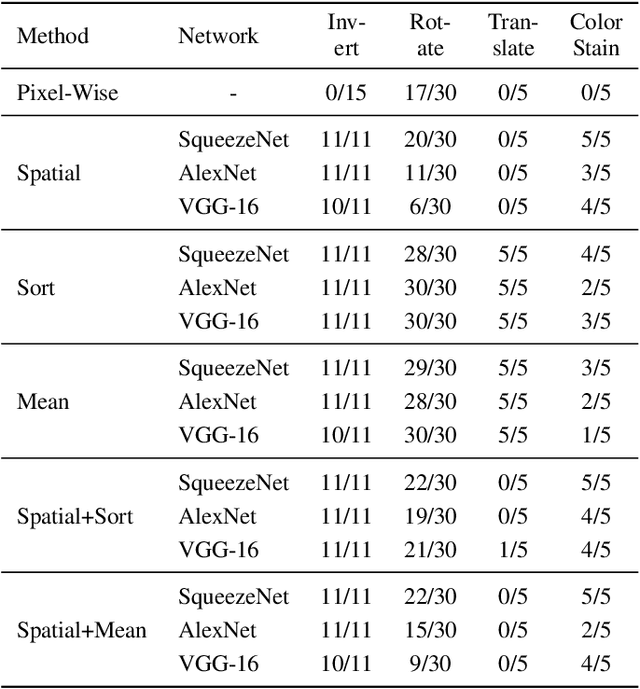
Measuring the similarity of images is a fundamental problem to computer vision for which no universal solution exists. While simple metrics such as the pixel-wise L2-norm have been shown to have significant flaws, they remain popular. One group of recent state-of-the-art metrics that mitigates some of those flaws are Deep Perceptual Similarity (DPS) metrics, where the similarity is evaluated as the distance in the deep features of neural networks. However, DPS metrics themselves have been less thoroughly examined for their benefits and, especially, their flaws. This work investigates the most common DPS metric, where deep features are compared by spatial position, along with metrics comparing the averaged and sorted deep features. The metrics are analyzed in-depth to understand the strengths and weaknesses of the metrics by using images designed specifically to challenge them. This work contributes with new insights into the flaws of DPS, and further suggests improvements to the metrics. An implementation of this work is available online: https://github.com/guspih/deep_perceptual_similarity_analysis/