 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Temporal Encoders for Neuromorphic Keyword Spotting with Few Neurons
Jan 24, 2023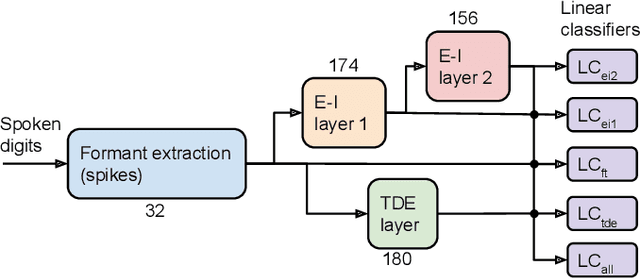
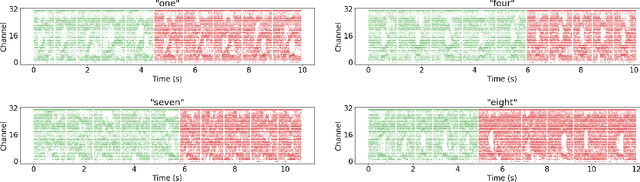
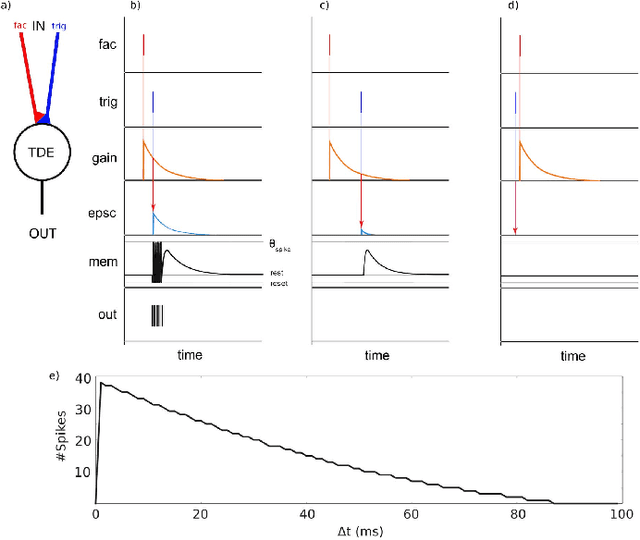
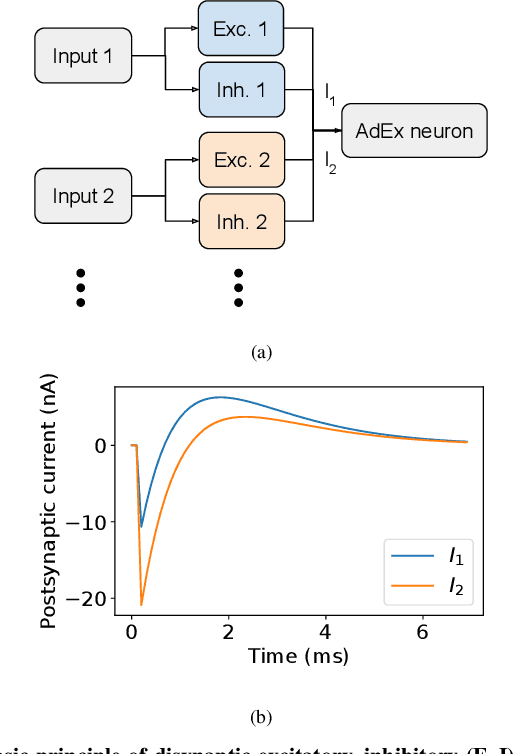
With the expansion of AI-powered virtual assistants, there is a need for low-power keyword spotting systems providing a "wake-up" mechanism for subsequent computationally expensive speech recognition. One promising approach is the use of neuromorphic sensors and spiking neural networks (SNNs) implemented in neuromorphic processors for sparse event-driven sensing. However, this requires resource-efficient SNN mechanisms for temporal encoding, which need to consider that these systems process information in a streaming manner, with physical time being an intrinsic property of their operation. In this work, two candidate neurocomputational elements for temporal encoding and feature extraction in SNNs described in recent literature - the spiking time-difference encoder (TDE) and disynaptic excitatory-inhibitory (E-I) elements - are comparatively investigated in a keyword-spotting task on formants computed from spoken digits in the TIDIGITS dataset. While both encoders improve performance over direct classification of the formant features in the training data, enabling a complete binary classification with a logistic regression model, they show no clear improvements on the test set. Resource-efficient keyword spotting applications may benefit from the use of these encoders, but further work on methods for learning the time constants and weights is required to investigate their full potential.