 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming the Exponential: A Fast Softmax Surrogate for Integer-Native Edge Inference
Apr 02, 2026Softmax can become a computational bottleneck in the Transformer model's Multi-Head Attention (MHA) block, particularly in small models under low-precision inference, where exponentiation and normalization incur significant overhead. As such, we suggest using Head-Calibrated Clipped-Linear Softmax (HCCS), a bounded, monotone surrogate to the exponential softmax function, which uses a clipped linear mapping of the max centered attention logits. This approximation produces a stable probability distribution, maintains the ordering of the original logits and has non-negative values. HCCS differs from previous softmax surrogates as it includes a set of lightweight calibration parameters that are optimized offline based on a representative dataset and calibrated for each individual attention head to preserve the statistical properties of the individual heads. We describe a hardware-motivated implementation of HCCS for high-throughput scenarios targeting the AMD Versal AI Engines. The current reference implementations from AMD for this platform rely upon either bfloat16 arithmetic or LUTs to perform the exponential operation, which might limit the throughput of the platform and fail to utilize the high-throughput integer vector processing units of the AI Engine. In contrast, HCCS provides a natural mapping to the AI Engines' int8 multiply accumulate (MAC) units. To the best of our knowledge, this is the first int8 optimized softmax surrogate for AMD AI engines that significantly exceeds the speed performance of other reference implementations while maintaining competitive task accuracy on small or heavily quantized MHA workloads after quantization-aware retraining.
PQuantML: A Tool for End-to-End Hardware-aware Model Compression
Mar 27, 2026PQuantML is a new open-source, hardware-aware neural network model compression library tailored to end-to-end workflows. Motivated by the need to deploy performant models to environments with strict latency constraints, PQuantML simplifies training of compressed models by providing a unified interface to apply pruning and quantization, either jointly or individually. The library implements multiple pruning methods with different granularities, as well as fixed-point quantization with support for High-Granularity Quantization. We evaluate PQuantML on representative tasks such as the jet substructure classification, so-called jet tagging, an on-edge problem related to real-time LHC data processing. Using various pruning methods with fixed-point quantization, PQuantML achieves substantial parameter and bit-width reductions while maintaining accuracy. The resulting compression is further compared against existing tools, such as QKeras and HGQ.
AIE4ML: An End-to-End Framework for Compiling Neural Networks for the Next Generation of AMD AI Engines
Dec 17, 2025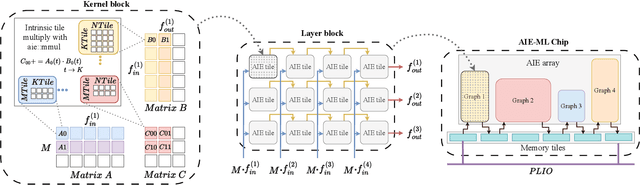
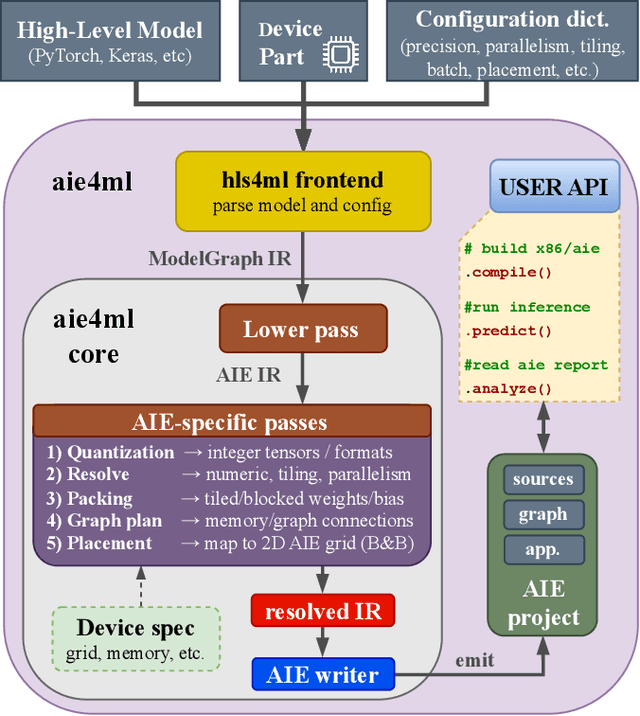
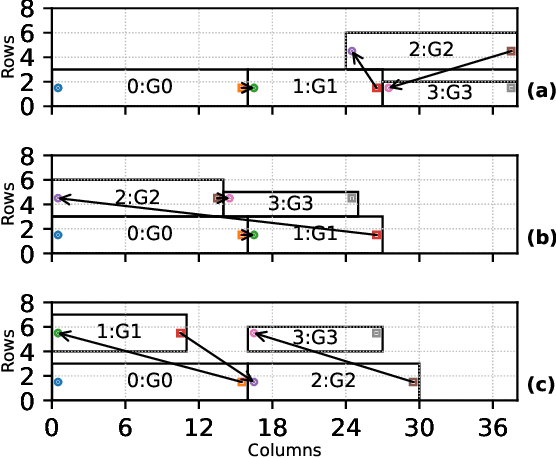
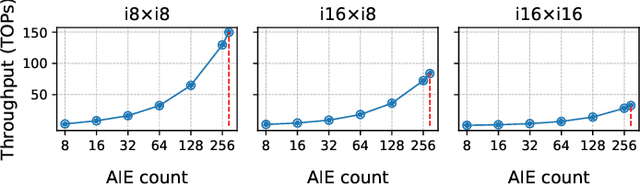
Efficient AI inference on AMD's Versal AI Engine (AIE) is challenging due to tightly coupled VLIW execution, explicit datapaths, and local memory management. Prior work focused on first-generation AIE kernel optimizations, without tackling full neural network execution across the 2D array. In this work, we present AIE4ML, the first comprehensive framework for converting AI models automatically into optimized firmware targeting the AIE-ML generation devices, also with forward compatibility for the newer AIE-MLv2 architecture. At the single-kernel level, we attain performance close to the architectural peak. At the graph and system levels, we provide a structured parallelization method that can scale across the 2D AIE-ML fabric and exploit its dedicated memory tiles to stay entirely on-chip throughout the model execution. As a demonstration, we designed a generalized and highly efficient linear-layer implementation with intrinsic support for fused bias addition and ReLU activation. Also, as our framework necessitates the generation of multi-layer implementations, our approach systematically derives deterministic, compact, and topology-optimized placements tailored to the physical 2D grid of the device through a novel graph placement and search algorithm. Finally, the framework seamlessly accepts quantized models imported from high-level tools such as hls4ml or PyTorch while preserving bit-exactness. In layer scaling benchmarks, we achieve up to 98.6% efficiency relative to the single-kernel baseline, utilizing 296 of 304 AIE tiles (97.4%) of the device with entirely on-chip data movement. With evaluations across real-world model topologies, we demonstrate that AIE4ML delivers GPU-class throughput under microsecond latency constraints, making it a practical companion for ultra-low-latency environments such as trigger systems in particle physics experiments.
Neuromorphic Readout for Hadron Calorimeters
Feb 18, 2025We simulate hadrons impinging on a homogeneous lead-tungstate (PbWO4) calorimeter to investigate how the resulting light yield and its temporal structure, as detected by an array of light-sensitive sensors, can be processed by a neuromorphic computing system. Our model encodes temporal photon distributions as spike trains and employs a fully connected spiking neural network to estimate the total deposited energy, as well as the position and spatial distribution of the light emissions within the sensitive material. The extracted primitives offer valuable topological information about the shower development in the material, achieved without requiring a segmentation of the active medium. A potential nanophotonic implementation using III-V semiconductor nanowires is discussed. It can be both fast and energy efficient.
Unsupervised Particle Tracking with Neuromorphic Computing
Feb 10, 2025



We study the application of a neural network architecture for identifying charged particle trajectories via unsupervised learning of delays and synaptic weights using a spike-time-dependent plasticity rule. In the considered model, the neurons receive time-encoded information on the position of particle hits in a tracking detector for a particle collider, modeled according to the geometry of the Compact Muon Solenoid Phase II detector. We show how a spiking neural network is capable of successfully identifying in a completely unsupervised way the signal left by charged particles in the presence of conspicuous noise from accidental or combinatorial hits. These results open the way to applications of neuromorphic computing to particle tracking, motivating further studies into its potential for real-time, low-power particle tracking in future high-energy physics experiments.