 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInhibiDistilbert: Knowledge Distillation for a ReLU and Addition-based Transformer
Mar 20, 2025This work explores optimizing transformer-based language models by integrating model compression techniques with inhibitor attention, a novel alternative attention mechanism. Inhibitor attention employs Manhattan distances and ReLU activations instead of the matrix multiplications and softmax activation of the conventional scaled dot-product attention. This shift offers potential computational and energy savings while maintaining model effectiveness. We propose further adjustments to improve the inhibitor mechanism's training efficiency and evaluate its performance on the DistilBERT architecture. Our knowledge distillation experiments indicate that the modified inhibitor transformer model can achieve competitive performance on standard NLP benchmarks, including General Language Understanding Evaluation (GLUE) and sentiment analysis tasks.
Technical Report for the Forgotten-by-Design Project: Targeted Obfuscation for Machine Learning
Jan 20, 2025The right to privacy, enshrined in various human rights declarations, faces new challenges in the age of artificial intelligence (AI). This paper explores the concept of the Right to be Forgotten (RTBF) within AI systems, contrasting it with traditional data erasure methods. We introduce Forgotten by Design, a proactive approach to privacy preservation that integrates instance-specific obfuscation techniques during the AI model training process. Unlike machine unlearning, which modifies models post-training, our method prevents sensitive data from being embedded in the first place. Using the LIRA membership inference attack, we identify vulnerable data points and propose defenses that combine additive gradient noise and weighting schemes. Our experiments on the CIFAR-10 dataset demonstrate that our techniques reduce privacy risks by at least an order of magnitude while maintaining model accuracy (at 95% significance). Additionally, we present visualization methods for the privacy-utility trade-off, providing a clear framework for balancing privacy risk and model accuracy. This work contributes to the development of privacy-preserving AI systems that align with human cognitive processes of motivated forgetting, offering a robust framework for safeguarding sensitive information and ensuring compliance with privacy regulations.
The Inhibitor: ReLU and Addition-Based Attention for Efficient Transformers
Oct 03, 2023


To enhance the computational efficiency of quantized Transformers, we replace the dot-product and Softmax-based attention with an alternative mechanism involving addition and ReLU activation only. This side-steps the expansion to double precision often required by matrix multiplication and avoids costly Softmax evaluations but maintains much of the core functionality of conventional dot-product attention. It can enable more efficient execution and support larger quantized Transformer models on resource-constrained hardware or alternative arithmetic systems like homomorphic encryption. Training experiments on four common benchmark tasks show test set prediction scores comparable to those of conventional Transformers with dot-product attention. Our scaling experiments also suggest significant computational savings, both in plaintext and under encryption. In particular, we believe that the ReLU and addition-based attention mechanism introduced in this paper may enable privacy-preserving AI applications operating under homomorphic encryption by avoiding the costly multiplication of encrypted variables.
ReLU and Addition-based Gated RNN
Aug 10, 2023We replace the multiplication and sigmoid function of the conventional recurrent gate with addition and ReLU activation. This mechanism is designed to maintain long-term memory for sequence processing but at a reduced computational cost, thereby opening up for more efficient execution or larger models on restricted hardware. Recurrent Neural Networks (RNNs) with gating mechanisms such as LSTM and GRU have been widely successful in learning from sequential data due to their ability to capture long-term dependencies. Conventionally, the update based on current inputs and the previous state history is each multiplied with dynamic weights and combined to compute the next state. However, multiplication can be computationally expensive, especially for certain hardware architectures or alternative arithmetic systems such as homomorphic encryption. It is demonstrated that the novel gating mechanism can capture long-term dependencies for a standard synthetic sequence learning task while significantly reducing computational costs such that execution time is reduced by half on CPU and by one-third under encryption. Experimental results on handwritten text recognition tasks furthermore show that the proposed architecture can be trained to achieve comparable accuracy to conventional GRU and LSTM baselines. The gating mechanism introduced in this paper may enable privacy-preserving AI applications operating under homomorphic encryption by avoiding the multiplication of encrypted variables. It can also support quantization in (unencrypted) plaintext applications, with the potential for substantial performance gains since the addition-based formulation can avoid the expansion to double precision often required for multiplication.
Småprat: DialoGPT for Natural Language Generation of Swedish Dialogue by Transfer Learning
Oct 12, 2021

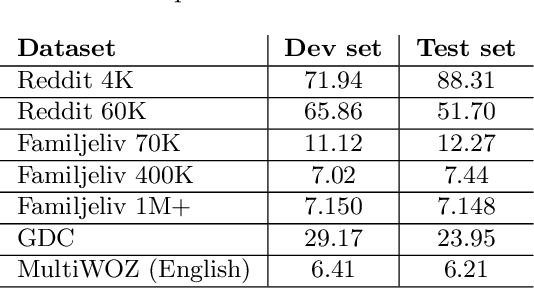
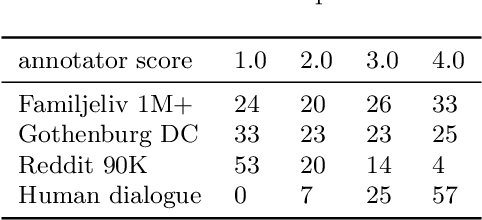
Building open-domain conversational systems (or chatbots) that produce convincing responses is a recognized challenge. Recent state-of-the-art (SoTA) transformer-based models for the generation of natural language dialogue have demonstrated impressive performance in simulating human-like, single-turn conversations in English. This work investigates, by an empirical study, the potential for transfer learning of such models to Swedish language. DialoGPT, an English language pre-trained model, is adapted by training on three different Swedish language conversational datasets obtained from publicly available sources. Perplexity score (an automated intrinsic language model metric) and surveys by human evaluation were used to assess the performances of the fine-tuned models, with results that indicate that the capacity for transfer learning can be exploited with considerable success. Human evaluators asked to score the simulated dialogue judged over 57% of the chatbot responses to be human-like for the model trained on the largest (Swedish) dataset. We provide the demos and model checkpoints of our English and Swedish chatbots on the HuggingFace platform for public use.