 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Digital Twin Framework for Metamorphic Testing of Autonomous Driving Systems Using Generative Model
Oct 08, 2025Ensuring the safety of self-driving cars remains a major challenge due to the complexity and unpredictability of real-world driving environments. Traditional testing methods face significant limitations, such as the oracle problem, which makes it difficult to determine whether a system's behavior is correct, and the inability to cover the full range of scenarios an autonomous vehicle may encounter. In this paper, we introduce a digital twin-driven metamorphic testing framework that addresses these challenges by creating a virtual replica of the self-driving system and its operating environment. By combining digital twin technology with AI-based image generative models such as Stable Diffusion, our approach enables the systematic generation of realistic and diverse driving scenes. This includes variations in weather, road topology, and environmental features, all while maintaining the core semantics of the original scenario. The digital twin provides a synchronized simulation environment where changes can be tested in a controlled and repeatable manner. Within this environment, we define three metamorphic relations inspired by real-world traffic rules and vehicle behavior. We validate our framework in the Udacity self-driving simulator and demonstrate that it significantly enhances test coverage and effectiveness. Our method achieves the highest true positive rate (0.719), F1 score (0.689), and precision (0.662) compared to baseline approaches. This paper highlights the value of integrating digital twins with AI-powered scenario generation to create a scalable, automated, and high-fidelity testing solution for autonomous vehicle safety.
TARDIS STRIDE: A Spatio-Temporal Road Image Dataset for Exploration and Autonomy
Jun 12, 2025World models aim to simulate environments and enable effective agent behavior. However, modeling real-world environments presents unique challenges as they dynamically change across both space and, crucially, time. To capture these composed dynamics, we introduce a Spatio-Temporal Road Image Dataset for Exploration (STRIDE) permuting 360-degree panoramic imagery into rich interconnected observation, state and action nodes. Leveraging this structure, we can simultaneously model the relationship between egocentric views, positional coordinates, and movement commands across both space and time. We benchmark this dataset via TARDIS, a transformer-based generative world model that integrates spatial and temporal dynamics through a unified autoregressive framework trained on STRIDE. We demonstrate robust performance across a range of agentic tasks such as controllable photorealistic image synthesis, instruction following, autonomous self-control, and state-of-the-art georeferencing. These results suggest a promising direction towards sophisticated generalist agents--capable of understanding and manipulating the spatial and temporal aspects of their material environments--with enhanced embodied reasoning capabilities. Training code, datasets, and model checkpoints are made available at https://huggingface.co/datasets/Tera-AI/STRIDE.
InhibiDistilbert: Knowledge Distillation for a ReLU and Addition-based Transformer
Mar 20, 2025This work explores optimizing transformer-based language models by integrating model compression techniques with inhibitor attention, a novel alternative attention mechanism. Inhibitor attention employs Manhattan distances and ReLU activations instead of the matrix multiplications and softmax activation of the conventional scaled dot-product attention. This shift offers potential computational and energy savings while maintaining model effectiveness. We propose further adjustments to improve the inhibitor mechanism's training efficiency and evaluate its performance on the DistilBERT architecture. Our knowledge distillation experiments indicate that the modified inhibitor transformer model can achieve competitive performance on standard NLP benchmarks, including General Language Understanding Evaluation (GLUE) and sentiment analysis tasks.
Semi-Supervised Audio Representation Learning for Modeling Beehive Strengths
May 21, 2021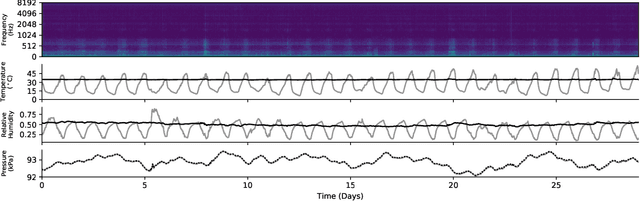

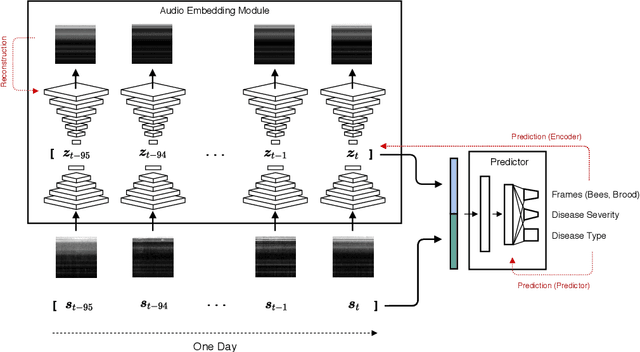

Honey bees are critical to our ecosystem and food security as a pollinator, contributing 35% of our global agriculture yield. In spite of their importance, beekeeping is exclusively dependent on human labor and experience-derived heuristics, while requiring frequent human checkups to ensure the colony is healthy, which can disrupt the colony. Increasingly, pollinator populations are declining due to threats from climate change, pests, environmental toxicity, making their management even more critical than ever before in order to ensure sustained global food security. To start addressing this pressing challenge, we developed an integrated hardware sensing system for beehive monitoring through audio and environment measurements, and a hierarchical semi-supervised deep learning model, composed of an audio modeling module and a predictor, to model the strength of beehives. The model is trained jointly on audio reconstruction and prediction losses based on human inspections, in order to model both low-level audio features and circadian temporal dynamics. We show that this model performs well despite limited labels, and can learn an audio embedding that is useful for characterizing different sound profiles of beehives. This is the first instance to our knowledge of applying audio-based deep learning to model beehives and population size in an observational setting across a large number of hives.
HVAQ: A High-Resolution Vision-Based Air Quality Dataset
Feb 18, 2021



Air pollutants, such as particulate matter, strongly impact human health. Most existing pollution monitoring techniques use stationary sensors, which are typically sparsely deployed. However, real-world pollution distributions vary rapidly in space and the visual effects of air pollutant can be used to estimate concentration, potentially at high spatial resolution. Accurate pollution monitoring requires either densely deployed conventional point sensors, at-a-distance vision-based pollution monitoring, or a combination of both. This paper makes the following contributions: (1) we present a high temporal and spatial resolution air quality dataset consisting of PM2.5, PM10, temperature, and humidity data; (2) we simultaneously take images covering the locations of the particle counters; and (3) we evaluate several vision-based state-of-art PM concentration prediction algorithms on our dataset and demonstrate that prediction accuracy increases with sensor density and image. It is our intent and belief that this dataset can enable advances by other research teams working on air quality estimation.