 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvSW: Overcoming Silent Weights for Accurate Binary Neural Networks
Jul 07, 2024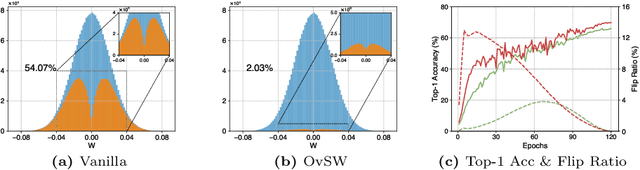

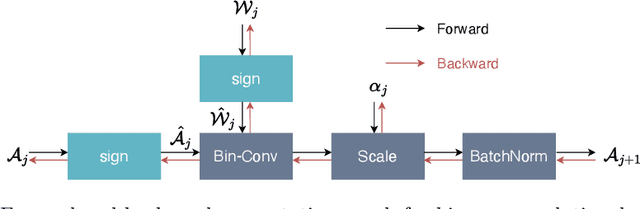

Binary Neural Networks~(BNNs) have been proven to be highly effective for deploying deep neural networks on mobile and embedded platforms. Most existing works focus on minimizing quantization errors, improving representation ability, or designing gradient approximations to alleviate gradient mismatch in BNNs, while leaving the weight sign flipping, a critical factor for achieving powerful BNNs, untouched. In this paper, we investigate the efficiency of weight sign updates in BNNs. We observe that, for vanilla BNNs, over 50\% of the weights remain their signs unchanged during training, and these weights are not only distributed at the tails of the weight distribution but also universally present in the vicinity of zero. We refer to these weights as ``silent weights'', which slow down convergence and lead to a significant accuracy degradation. Theoretically, we reveal this is due to the independence of the BNNs gradient from the latent weight distribution. To address the issue, we propose Overcome Silent Weights~(OvSW). OvSW first employs Adaptive Gradient Scaling~(AGS) to establish a relationship between the gradient and the latent weight distribution, thereby improving the overall efficiency of weight sign updates. Additionally, we design Silence Awareness Decaying~(SAD) to automatically identify ``silent weights'' by tracking weight flipping state, and apply an additional penalty to ``silent weights'' to facilitate their flipping. By efficiently updating weight signs, our method achieves faster convergence and state-of-the-art performance on CIFAR10 and ImageNet1K dataset with various architectures. For example, OvSW obtains 61.6\% and 65.5\% top-1 accuracy on the ImageNet1K using binarized ResNet18 and ResNet34 architecture respectively. Codes are available at \url{https://github.com/JingyangXiang/OvSW}.
RK-core: An Established Methodology for Exploring the Hierarchical Structure within Datasets
Oct 10, 2023



Recently, the field of machine learning has undergone a transition from model-centric to data-centric. The advancements in diverse learning tasks have been propelled by the accumulation of more extensive datasets, subsequently facilitating the training of larger models on these datasets. However, these datasets remain relatively under-explored. To this end, we introduce a pioneering approach known as RK-core, to empower gaining a deeper understanding of the intricate hierarchical structure within datasets. Across several benchmark datasets, we find that samples with low coreness values appear less representative of their respective categories, and conversely, those with high coreness values exhibit greater representativeness. Correspondingly, samples with high coreness values make a more substantial contribution to the performance in comparison to those with low coreness values. Building upon this, we further employ RK-core to analyze the hierarchical structure of samples with different coreset selection methods. Remarkably, we find that a high-quality coreset should exhibit hierarchical diversity instead of solely opting for representative samples. The code is available at https://github.com/yaolu-zjut/Kcore.
Hyperspectral Imaging for cherry tomato
Mar 10, 2022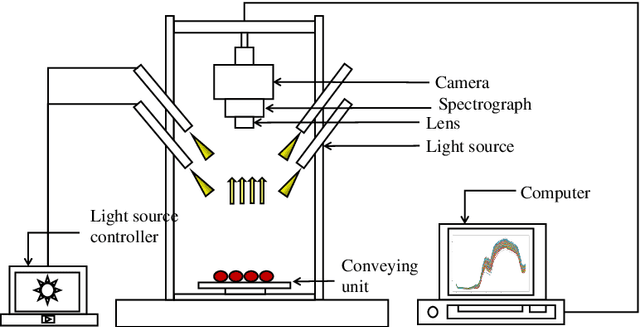
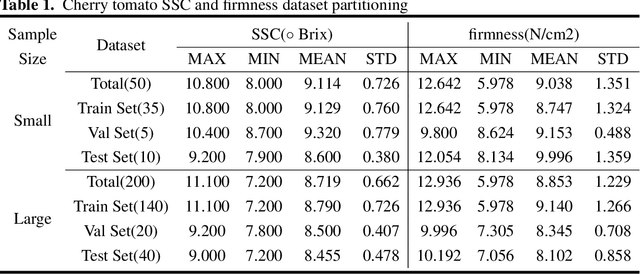
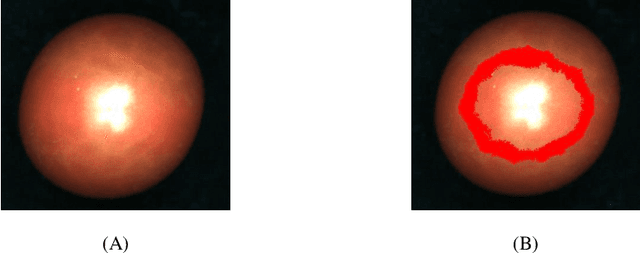
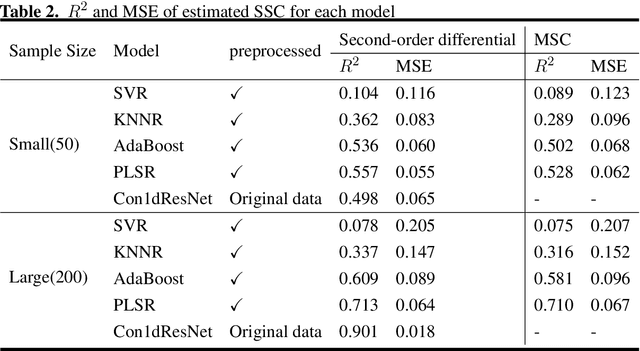
Cherry tomato (Solanum Lycopersicum) is popular with consumers over the world due to its special flavor. Soluble solids content (SSC) and firmness are two key metrics for evaluating the product qualities. In this work, we develop non-destructive testing techniques for SSC and fruit firmness based on hyperspectral images and a corresponding deep learning regression model. Hyperspectral reflectance images of over 200 tomato fruits are derived with spectrum ranging from 400 to 1000 nm. The acquired hyperspectral images are corrected and the spectral information is extracted. A novel one-dimensional(1D) convolutional ResNet (Con1dResNet) based regression model is prosed and compared with the state of art techniques. Experimental results show that, with a relatively large number of samples our technique is 26.4\% better than state of art technique for SSC and 33.7\% for firmness. The results of this study indicate the application potential of hyperspectral imaging technique in the SSC and firmness detection, which provides a new option for non-destructive testing of cherry tomato fruit quality in the future.
Graph Modularity: Towards Understanding the Cross-Layer Transition of Feature Representations in Deep Neural Networks
Nov 24, 2021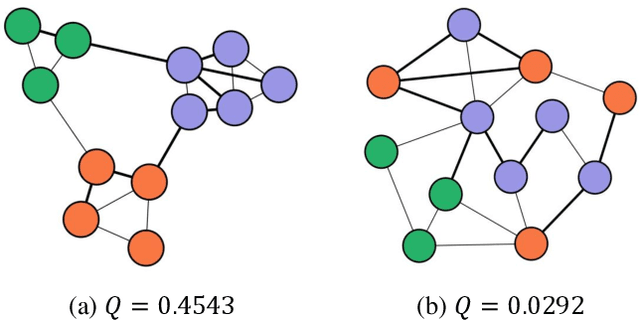
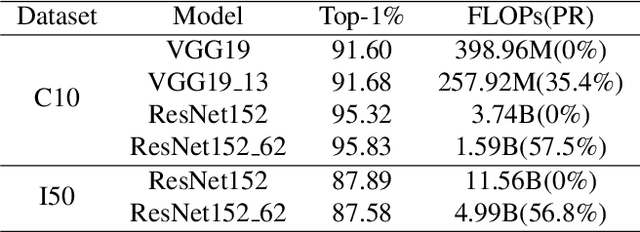
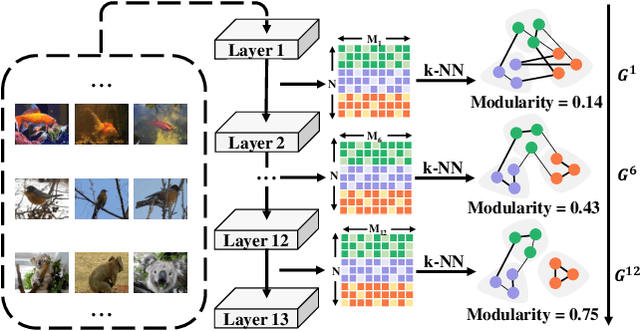
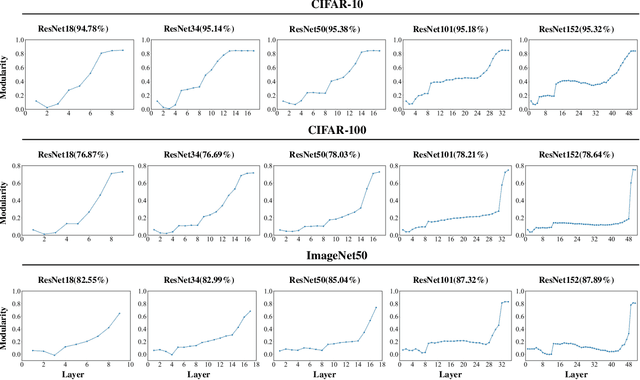
There are good arguments to support the claim that feature representations eventually transition from general to specific in deep neural networks (DNNs), but this transition remains relatively underexplored. In this work, we move a tiny step towards understanding the transition of feature representations. We first characterize this transition by analyzing the class separation in intermediate layers, and next model the process of class separation as community evolution in dynamic graphs. Then, we introduce modularity, a common metric in graph theory, to quantify the evolution of communities. We find that modularity tends to rise as the layer goes deeper, but descends or reaches a plateau at particular layers. Through an asymptotic analysis, we show that modularity can provide quantitative analysis of the transition of the feature representations. With the insight on feature representations, we demonstrate that modularity can also be used to identify and locate redundant layers in DNNs, which provides theoretical guidance for layer pruning. Based on this inspiring finding, we propose a layer-wise pruning method based on modularity. Further experiments show that our method can prune redundant layers with minimal impact on performance. The codes are available at https://github.com/yaolu-zjut/Dynamic-Graphs-Construction.
Graph-Based Similarity of Neural Network Representations
Nov 22, 2021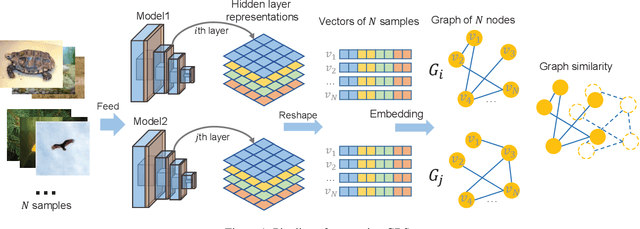

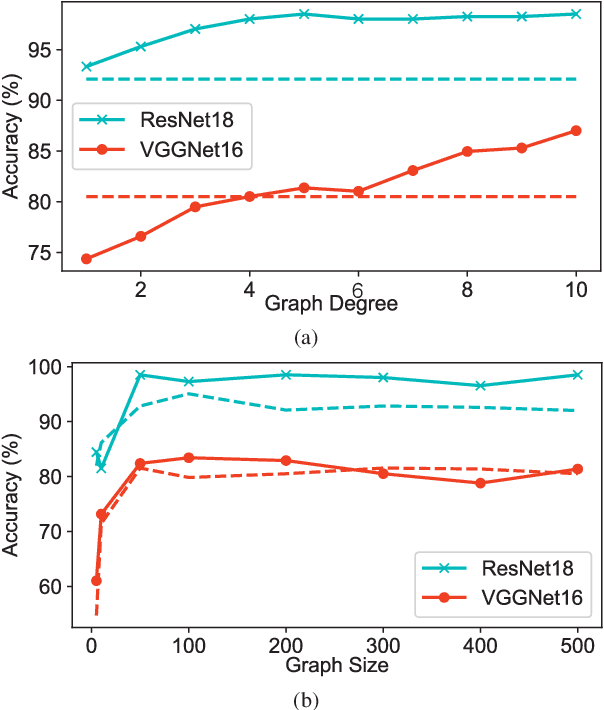

Understanding the black-box representations in Deep Neural Networks (DNN) is an essential problem in deep learning. In this work, we propose Graph-Based Similarity (GBS) to measure the similarity of layer features. Contrary to previous works that compute the similarity directly on the feature maps, GBS measures the correlation based on the graph constructed with hidden layer outputs. By treating each input sample as a node and the corresponding layer output similarity as edges, we construct the graph of DNN representations for each layer. The similarity between graphs of layers identifies the correspondences between representations of models trained in different datasets and initializations. We demonstrate and prove the invariance property of GBS, including invariance to orthogonal transformation and invariance to isotropic scaling, and compare GBS with CKA. GBS shows state-of-the-art performance in reflecting the similarity and provides insights on explaining the adversarial sample behavior on the hidden layer space.
GGT: Graph-Guided Testing for Adversarial Sample Detection of Deep Neural Network
Jul 09, 2021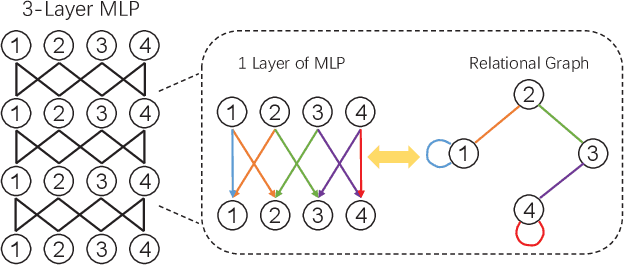
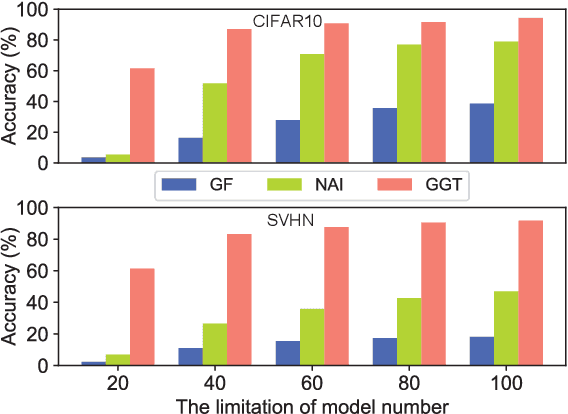
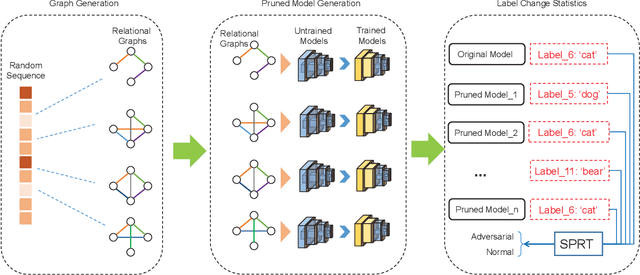
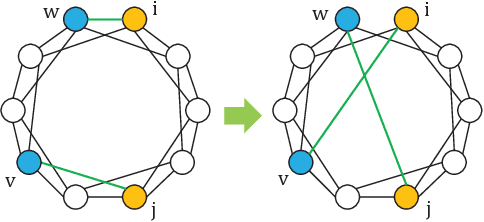
Deep Neural Networks (DNN) are known to be vulnerable to adversarial samples, the detection of which is crucial for the wide application of these DNN models. Recently, a number of deep testing methods in software engineering were proposed to find the vulnerability of DNN systems, and one of them, i.e., Model Mutation Testing (MMT), was used to successfully detect various adversarial samples generated by different kinds of adversarial attacks. However, the mutated models in MMT are always huge in number (e.g., over 100 models) and lack diversity (e.g., can be easily circumvented by high-confidence adversarial samples), which makes it less efficient in real applications and less effective in detecting high-confidence adversarial samples. In this study, we propose Graph-Guided Testing (GGT) for adversarial sample detection to overcome these aforementioned challenges. GGT generates pruned models with the guide of graph characteristics, each of them has only about 5% parameters of the mutated model in MMT, and graph guided models have higher diversity. The experiments on CIFAR10 and SVHN validate that GGT performs much better than MMT with respect to both effectiveness and efficiency.
HVAQ: A High-Resolution Vision-Based Air Quality Dataset
Feb 18, 2021



Air pollutants, such as particulate matter, strongly impact human health. Most existing pollution monitoring techniques use stationary sensors, which are typically sparsely deployed. However, real-world pollution distributions vary rapidly in space and the visual effects of air pollutant can be used to estimate concentration, potentially at high spatial resolution. Accurate pollution monitoring requires either densely deployed conventional point sensors, at-a-distance vision-based pollution monitoring, or a combination of both. This paper makes the following contributions: (1) we present a high temporal and spatial resolution air quality dataset consisting of PM2.5, PM10, temperature, and humidity data; (2) we simultaneously take images covering the locations of the particle counters; and (3) we evaluate several vision-based state-of-art PM concentration prediction algorithms on our dataset and demonstrate that prediction accuracy increases with sensor density and image. It is our intent and belief that this dataset can enable advances by other research teams working on air quality estimation.
MITNet: GAN Enhanced Magnetic Induction Tomography Based on Complex CNN
Feb 16, 2021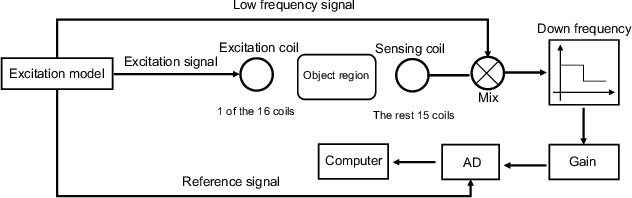
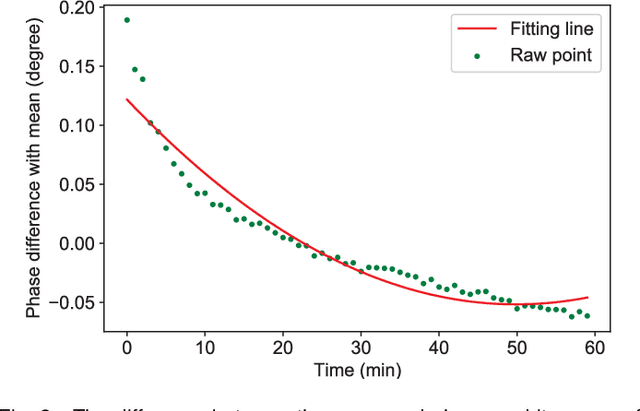
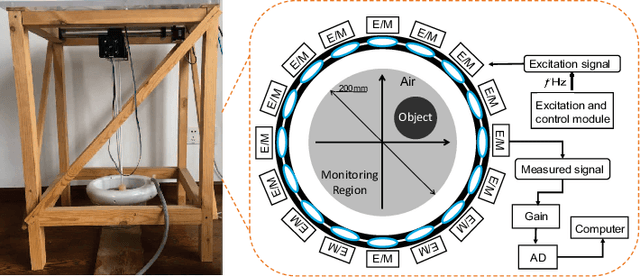
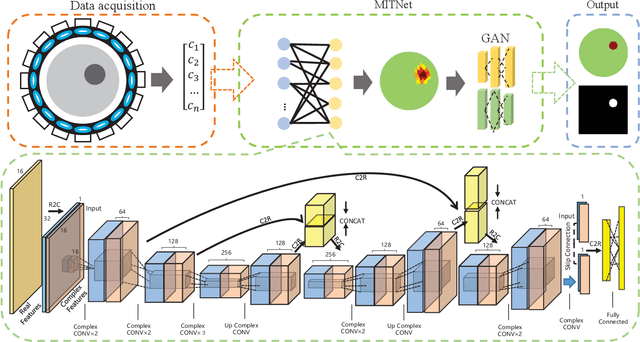
Magnetic induction tomography (MIT) is an efficient solution for long-term brain disease monitoring, which focuses on reconstructing bio-impedance distribution inside the human brain using non-intrusive electromagnetic fields. However, high-quality brain image reconstruction remains challenging since reconstructing images from the measured weak signals is a highly non-linear and ill-conditioned problem. In this work, we propose a generative adversarial network (GAN) enhanced MIT technique, named MITNet, based on a complex convolutional neural network (CNN). The experimental results on the real-world dataset validate the performance of our technique, which outperforms the state-of-art method by 25.27%.
Open DNN Box by Power Side-Channel Attack
Jul 21, 2019
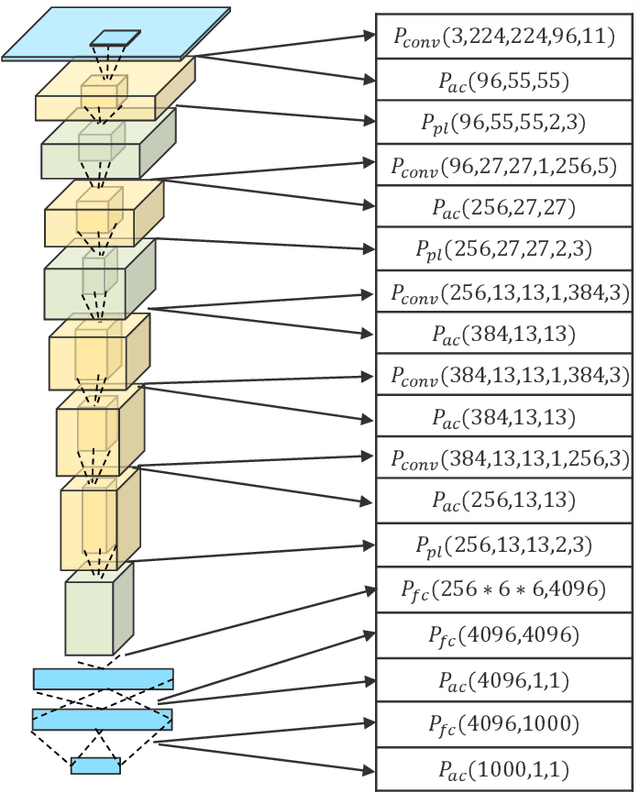
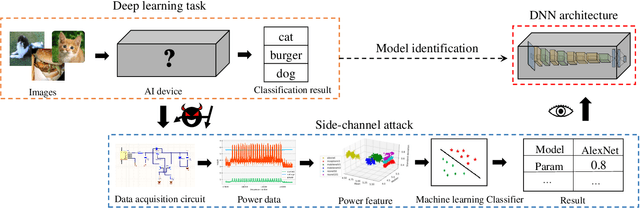
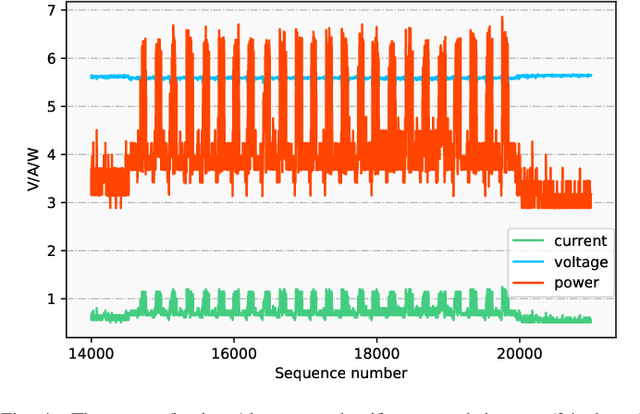
Deep neural networks are becoming popular and important assets of many AI companies. However, recent studies indicate that they are also vulnerable to adversarial attacks. Adversarial attacks can be either white-box or black-box. The white-box attacks assume full knowledge of the models while the black-box ones assume none. In general, revealing more internal information can enable much more powerful and efficient attacks. However, in most real-world applications, the internal information of embedded AI devices is unavailable, i.e., they are black-box. Therefore, in this work, we propose a side-channel information based technique to reveal the internal information of black-box models. Specifically, we have made the following contributions: (1) we are the first to use side-channel information to reveal internal network architecture in embedded devices; (2) we are the first to construct models for internal parameter estimation; and (3) we validate our methods on real-world devices and applications. The experimental results show that our method can achieve 96.50\% accuracy on average. Such results suggest that we should pay strong attention to the security problem of many AI applications, and further propose corresponding defensive strategies in the future.