 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Representation Learning for Molecular Property Prediction: Sequence, Graph, Geometry
Jan 09, 2024Molecular property prediction refers to the task of labeling molecules with some biochemical properties, playing a pivotal role in the drug discovery and design process. Recently, with the advancement of machine learning, deep learning-based molecular property prediction has emerged as a solution to the resource-intensive nature of traditional methods, garnering significant attention. Among them, molecular representation learning is the key factor for molecular property prediction performance. And there are lots of sequence-based, graph-based, and geometry-based methods that have been proposed. However, the majority of existing studies focus solely on one modality for learning molecular representations, failing to comprehensively capture molecular characteristics and information. In this paper, a novel multi-modal representation learning model, which integrates the sequence, graph, and geometry characteristics, is proposed for molecular property prediction, called SGGRL. Specifically, we design a fusion layer to fusion the representation of different modalities. Furthermore, to ensure consistency across modalities, SGGRL is trained to maximize the similarity of representations for the same molecule while minimizing similarity for different molecules. To verify the effectiveness of SGGRL, seven molecular datasets, and several baselines are used for evaluation and comparison. The experimental results demonstrate that SGGRL consistently outperforms the baselines in most cases. This further underscores the capability of SGGRL to comprehensively capture molecular information. Overall, the proposed SGGRL model showcases its potential to revolutionize molecular property prediction by leveraging multi-modal representation learning to extract diverse and comprehensive molecular insights. Our code is released at https://github.com/Vencent-Won/SGGRL.
Subgraph Networks Based Contrastive Learning
Jun 06, 2023



Graph contrastive learning (GCL), as a self-supervised learning method, can solve the problem of annotated data scarcity. It mines explicit features in unannotated graphs to generate favorable graph representations for downstream tasks. Most existing GCL methods focus on the design of graph augmentation strategies and mutual information estimation operations. Graph augmentation produces augmented views by graph perturbations. These views preserve a locally similar structure and exploit explicit features. However, these methods have not considered the interaction existing in subgraphs. To explore the impact of substructure interactions on graph representations, we propose a novel framework called subgraph network-based contrastive learning (SGNCL). SGNCL applies a subgraph network generation strategy to produce augmented views. This strategy converts the original graph into an Edge-to-Node mapping network with both topological and attribute features. The single-shot augmented view is a first-order subgraph network that mines the interaction between nodes, node-edge, and edges. In addition, we also investigate the impact of the second-order subgraph augmentation on mining graph structure interactions, and further, propose a contrastive objective that fuses the first-order and second-order subgraph information. We compare SGNCL with classical and state-of-the-art graph contrastive learning methods on multiple benchmark datasets of different domains. Extensive experiments show that SGNCL achieves competitive or better performance (top three) on all datasets in unsupervised learning settings. Furthermore, SGNCL achieves the best average gain of 6.9\% in transfer learning compared to the best method. Finally, experiments also demonstrate that mining substructure interactions have positive implications for graph contrastive learning.
Single Node Injection Label Specificity Attack on Graph Neural Networks via Reinforcement Learning
May 04, 2023



Graph neural networks (GNNs) have achieved remarkable success in various real-world applications. However, recent studies highlight the vulnerability of GNNs to malicious perturbations. Previous adversaries primarily focus on graph modifications or node injections to existing graphs, yielding promising results but with notable limitations. Graph modification attack~(GMA) requires manipulation of the original graph, which is often impractical, while graph injection attack~(GIA) necessitates training a surrogate model in the black-box setting, leading to significant performance degradation due to divergence between the surrogate architecture and the actual victim model. Furthermore, most methods concentrate on a single attack goal and lack a generalizable adversary to develop distinct attack strategies for diverse goals, thus limiting precise control over victim model behavior in real-world scenarios. To address these issues, we present a gradient-free generalizable adversary that injects a single malicious node to manipulate the classification result of a target node in the black-box evasion setting. We propose Gradient-free Generalizable Single Node Injection Attack, namely G$^2$-SNIA, a reinforcement learning framework employing Proximal Policy Optimization. By directly querying the victim model, G$^2$-SNIA learns patterns from exploration to achieve diverse attack goals with extremely limited attack budgets. Through comprehensive experiments over three acknowledged benchmark datasets and four prominent GNNs in the most challenging and realistic scenario, we demonstrate the superior performance of our proposed G$^2$-SNIA over the existing state-of-the-art baselines. Moreover, by comparing G$^2$-SNIA with multiple white-box evasion baselines, we confirm its capacity to generate solutions comparable to those of the best adversaries.
Graph Modularity: Towards Understanding the Cross-Layer Transition of Feature Representations in Deep Neural Networks
Nov 24, 2021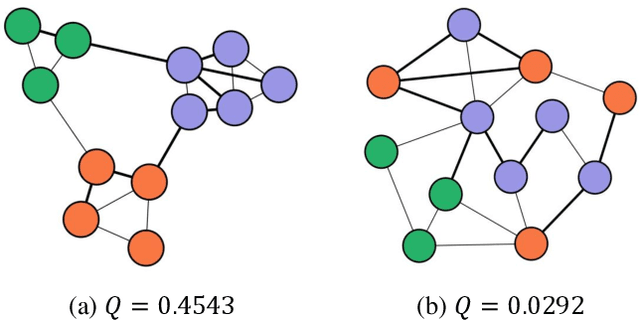
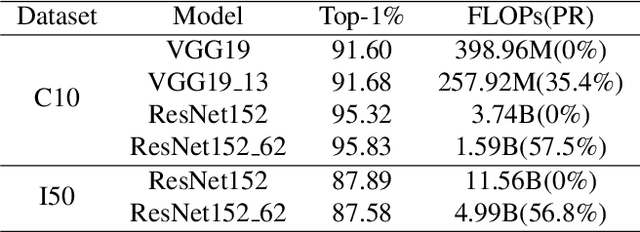
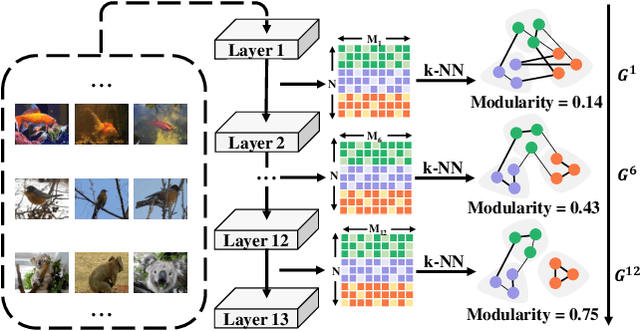
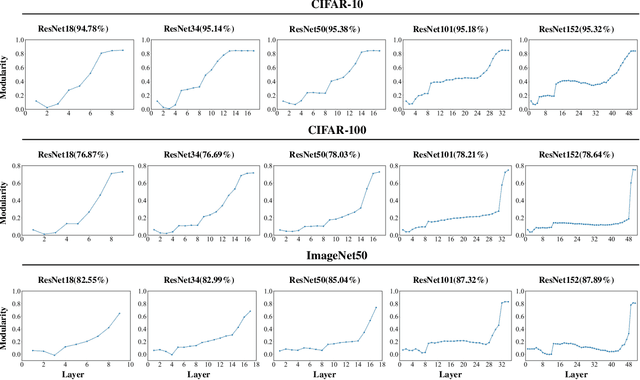
There are good arguments to support the claim that feature representations eventually transition from general to specific in deep neural networks (DNNs), but this transition remains relatively underexplored. In this work, we move a tiny step towards understanding the transition of feature representations. We first characterize this transition by analyzing the class separation in intermediate layers, and next model the process of class separation as community evolution in dynamic graphs. Then, we introduce modularity, a common metric in graph theory, to quantify the evolution of communities. We find that modularity tends to rise as the layer goes deeper, but descends or reaches a plateau at particular layers. Through an asymptotic analysis, we show that modularity can provide quantitative analysis of the transition of the feature representations. With the insight on feature representations, we demonstrate that modularity can also be used to identify and locate redundant layers in DNNs, which provides theoretical guidance for layer pruning. Based on this inspiring finding, we propose a layer-wise pruning method based on modularity. Further experiments show that our method can prune redundant layers with minimal impact on performance. The codes are available at https://github.com/yaolu-zjut/Dynamic-Graphs-Construction.
TSGN: Transaction Subgraph Networks for Identifying Ethereum Phishing Accounts
Apr 20, 2021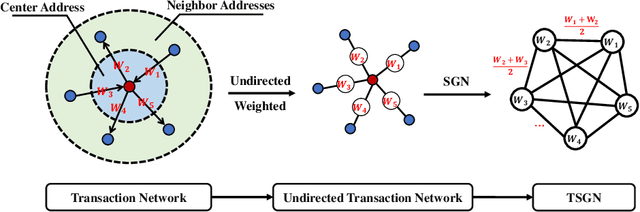
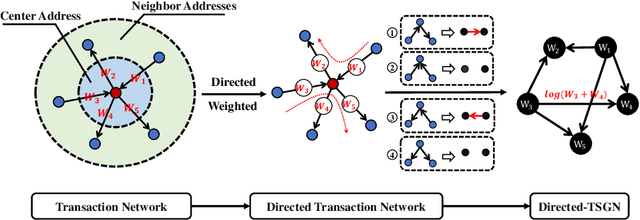
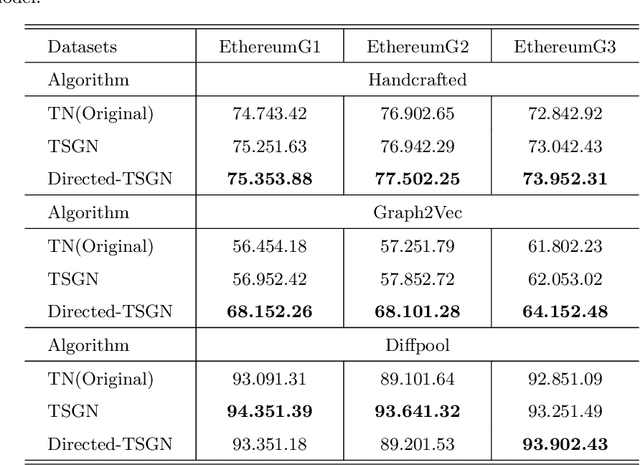
Blockchain technology and, in particular, blockchain-based transaction offers us information that has never been seen before in the financial world. In contrast to fiat currencies, transactions through virtual currencies like Bitcoin are completely public. And these transactions of cryptocurrencies are permanently recorded on Blockchain and are available at any time. Therefore, this allows us to build transaction networks (TN) to analyze illegal phenomenons such as phishing scams in blockchain from a network perspective. In this paper, we propose a Transaction SubGraph Network (TSGN) based classification model to identify phishing accounts in Ethereum. Firstly we extract transaction subgraphs for each address and then expand these subgraphs into corresponding TSGNs based on the different mapping mechanisms. We find that TSGNs can provide more potential information to benefit the identification of phishing accounts. Moreover, Directed-TSGNs, by introducing direction attributes, can retain the transaction flow information that captures the significant topological pattern of phishing scams. By comparing with the TSGN, Directed-TSGN indeed has much lower time complexity, benefiting the graph representation learning. Experimental results demonstrate that, combined with network representation algorithms, the TSGN model can capture more features to enhance the classification algorithm and improve phishing nodes' identification accuracy in the Ethereum networks.
Subgraph Networks with Application to Structural Feature Space Expansion
Apr 01, 2019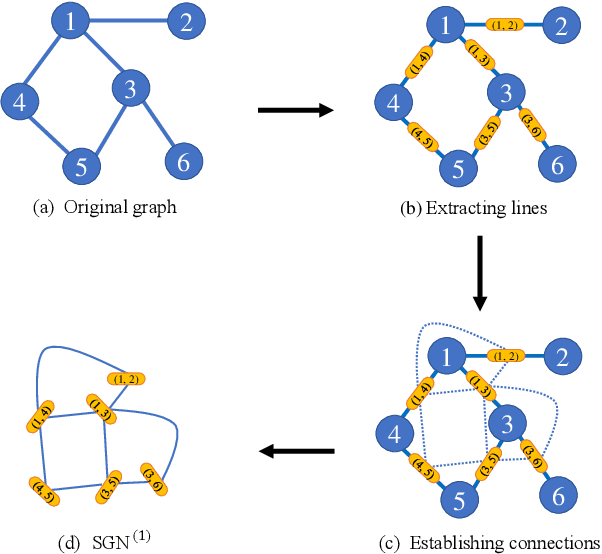
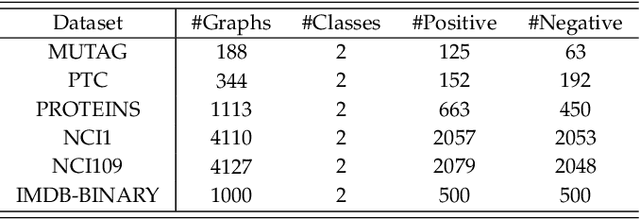
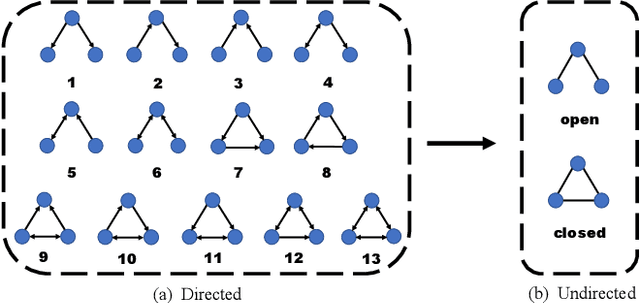
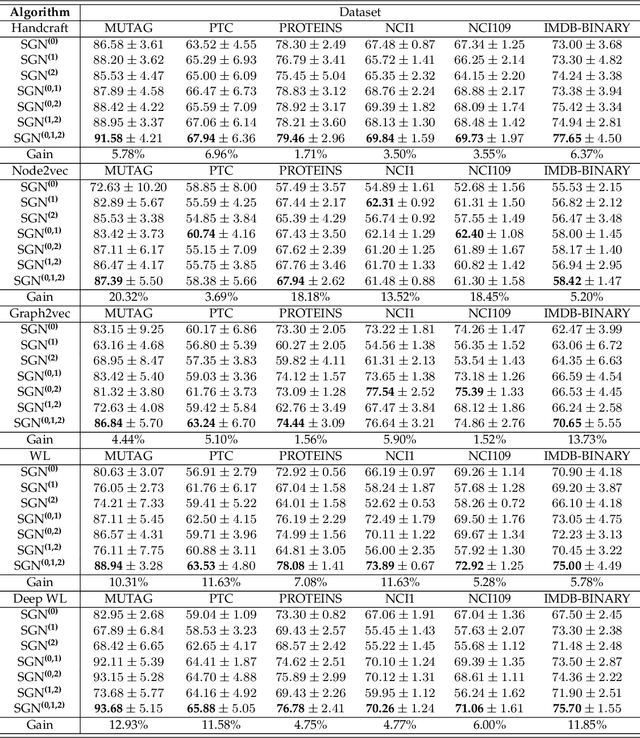
In this paper, the concept of subgraph network (SGN) is introduced and then applied to network models, with algorithms designed for constructing the 1st-order and 2nd-order SGNs, which can be easily extended to build higher-order ones. Furthermore, these SGNs are used to expand the structural feature space of the underlying network, beneficial for network classification. Numerical experiments demonstrate that the network classification model based on the structural features of the original network together with the 1st-order and 2nd-order SGNs always performs the best as compared to the models based only on one or two of such networks. In other words, the structural features of SGNs can complement that of the original network for better network classification, regardless of the feature extraction method used, such as the handcrafted, network embedding and kernel-based methods. More interestingly, it is found that the model based on the handcrafted feature performs even better than those based on automatically generated features, at least for most datasets tested in the present investigation. This indicates that, in general, properly chosen structural features are not only more interpretable due to their clear physical meanings, but also effective in designing structure-based algorithms for network classification.
Distributed sampled-data control of nonholonomic multi-robot systems with proximity networks
Sep 07, 2016
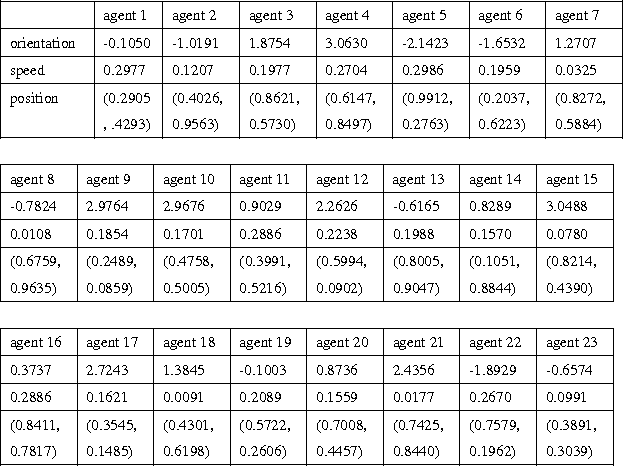
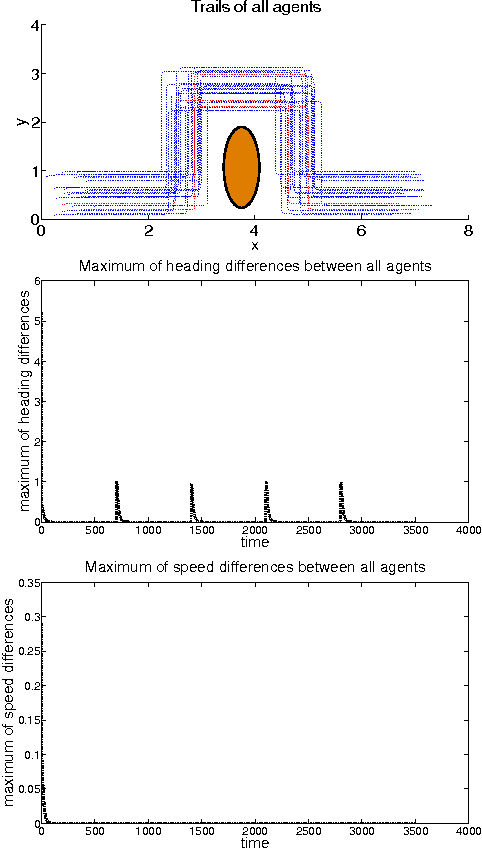
This paper considers the distributed sampled-data control problem of a group of mobile robots connected via distance-induced proximity networks. A dwell time is assumed in order to avoid chattering in the neighbor relations that may be caused by abrupt changes of positions when updating information from neighbors. Distributed sampled-data control laws are designed based on nearest neighbour rules, which in conjunction with continuous-time dynamics results in hybrid closed-loop systems. For uniformly and independently initial states, a sufficient condition is provided to guarantee synchronization for the system without leaders. In order to steer all robots to move with the desired orientation and speed, we then introduce a number of leaders into the system, and quantitatively establish the proportion of leaders needed to track either constant or time-varying signals. All these conditions depend only on the neighborhood radius, the maximum initial moving speed and the dwell time, without assuming a prior properties of the neighbor graphs as are used in most of the existing literature.
* 15 pages, 3 figures