 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Gymnast: Training Robots with Reinforcement Learning in a World Model
Feb 02, 2026Robot learning from interacting with the physical world is fundamentally bottlenecked by the cost of physical interaction. The two alternatives, supervised finetuning (SFT) from expert demonstrations and reinforcement learning (RL) in a software-based simulator, are limited by the amount of expert data available and the sim-to-real gap for manipulation. With the recent emergence of world models learned from real-world video-action data, we ask the question of whether training a policy in a world model can be more effective than supervised learning or software simulation in achieving better real-robot performance. We propose World-Gymnast, which performs RL finetuning of a vision-language-action (VLA) policy by rolling out the policy in an action-conditioned video world model and rewarding the rollouts with a vision-language model (VLM). On the Bridge robot setup, World-Gymnast outperforms SFT by as much as 18x and outperforms software simulator by as much as 2x. More importantly, World-Gymnast demonstrates intriguing capabilities of RL with a world model, including training on diverse language instructions and novel scenes from the world model, test-time training in a novel scene, and online iterative world model and policy improvement. Our results suggest learning a world model and training robot policies in the cloud could be the key to bridging the gap between robots that work in demonstrations and robots that can work in anyone's household.
Cross-Modality Controlled Molecule Generation with Diffusion Language Model
Aug 20, 2025



Current SMILES-based diffusion models for molecule generation typically support only unimodal constraint. They inject conditioning signals at the start of the training process and require retraining a new model from scratch whenever the constraint changes. However, real-world applications often involve multiple constraints across different modalities, and additional constraints may emerge over the course of a study. This raises a challenge: how to extend a pre-trained diffusion model not only to support cross-modality constraints but also to incorporate new ones without retraining. To tackle this problem, we propose the Cross-Modality Controlled Molecule Generation with Diffusion Language Model (CMCM-DLM), demonstrated by two distinct cross modalities: molecular structure and chemical properties. Our approach builds upon a pre-trained diffusion model, incorporating two trainable modules, the Structure Control Module (SCM) and the Property Control Module (PCM), and operates in two distinct phases during the generation process. In Phase I, we employs the SCM to inject structural constraints during the early diffusion steps, effectively anchoring the molecular backbone. Phase II builds on this by further introducing PCM to guide the later stages of inference to refine the generated molecules, ensuring their chemical properties match the specified targets. Experimental results on multiple datasets demonstrate the efficiency and adaptability of our approach, highlighting CMCM-DLM's significant advancement in molecular generation for drug discovery applications.
Semantic-Guided Global-Local Collaborative Networks for Lightweight Image Super-Resolution
Mar 20, 2025



Single-Image Super-Resolution (SISR) plays a pivotal role in enhancing the accuracy and reliability of measurement systems, which are integral to various vision-based instrumentation and measurement applications. These systems often require clear and detailed images for precise object detection and recognition. However, images captured by visual measurement tools frequently suffer from degradation, including blurring and loss of detail, which can impede measurement accuracy.As a potential remedy, we in this paper propose a Semantic-Guided Global-Local Collaborative Network (SGGLC-Net) for lightweight SISR. Our SGGLC-Net leverages semantic priors extracted from a pre-trained model to guide the super-resolution process, enhancing image detail quality effectively. Specifically,we propose a Semantic Guidance Module that seamlessly integrates the semantic priors into the super-resolution network, enabling the network to more adeptly capture and utilize semantic priors, thereby enhancing image details. To further explore both local and non-local interactions for improved detail rendition,we propose a Global-Local Collaborative Module, which features three Global and Local Detail Enhancement Modules, as well as a Hybrid Attention Mechanism to work together to efficiently learn more useful features. Our extensive experiments show that SGGLC-Net achieves competitive PSNR and SSIM values across multiple benchmark datasets, demonstrating higher performance with the multi-adds reduction of 12.81G compared to state-of-the-art lightweight super-resolution approaches. These improvements underscore the potential of our approach to enhance the precision and effectiveness of visual measurement systems. Codes are at https://github.com/fanamber831/SGGLC-Net.
* 14 pages,13 figures, 9 tables
DexCatch: Learning to Catch Arbitrary Objects with Dexterous Hands
Oct 13, 2023



Achieving human-like dexterous manipulation remains a crucial area of research in robotics. Current research focuses on improving the success rate of pick-and-place tasks. Compared with pick-and-place, throw-catching behavior has the potential to increase picking speed without transporting objects to their destination. However, dynamic dexterous manipulation poses a major challenge for stable control due to a large number of dynamic contacts. In this paper, we propose a Stability-Constrained Reinforcement Learning (SCRL) algorithm to learn to catch diverse objects with dexterous hands. The SCRL algorithm outperforms baselines by a large margin, and the learned policies show strong zero-shot transfer performance on unseen objects. Remarkably, even though the object in a hand facing sideward is extremely unstable due to the lack of support from the palm, our method can still achieve a high level of success in the most challenging task. Video demonstrations of learned behaviors and the code can be found on the supplementary website.
Exploring Inductive Biases in Contrastive Learning: A Clustering Perspective
May 17, 2023



This paper investigates the differences in data organization between contrastive and supervised learning methods, focusing on the concept of locally dense clusters. We introduce a novel metric, Relative Local Density (RLD), to quantitatively measure local density within clusters. Visual examples are provided to highlight the distinctions between locally dense clusters and globally dense ones. By comparing the clusters formed by contrastive and supervised learning, we reveal that contrastive learning generates locally dense clusters without global density, while supervised learning creates clusters with both local and global density. We further explore the use of a Graph Convolutional Network (GCN) classifier as an alternative to linear classifiers for handling locally dense clusters. Finally, we utilize t-SNE visualizations to substantiate the differences between the features generated by contrastive and supervised learning methods. We conclude by proposing future research directions, including the development of efficient classifiers tailored to contrastive learning and the creation of innovative augmentation algorithms.
Graph Modularity: Towards Understanding the Cross-Layer Transition of Feature Representations in Deep Neural Networks
Nov 24, 2021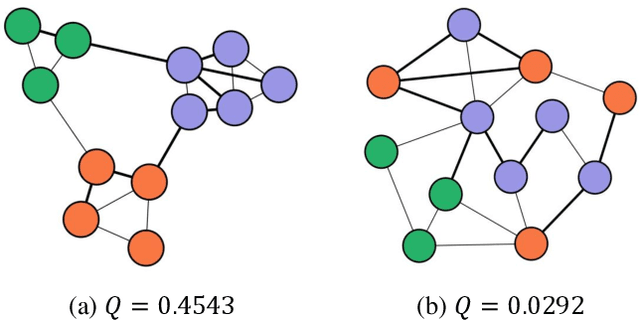
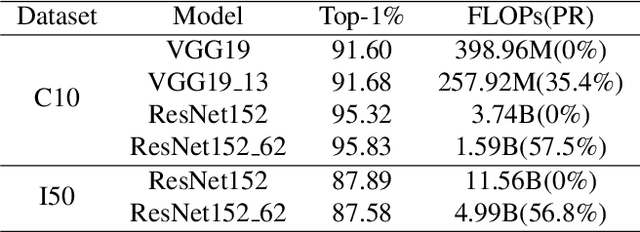
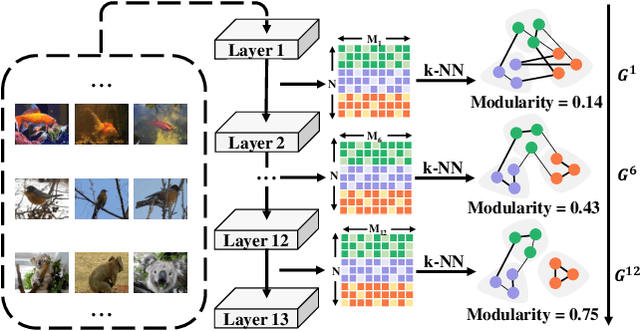
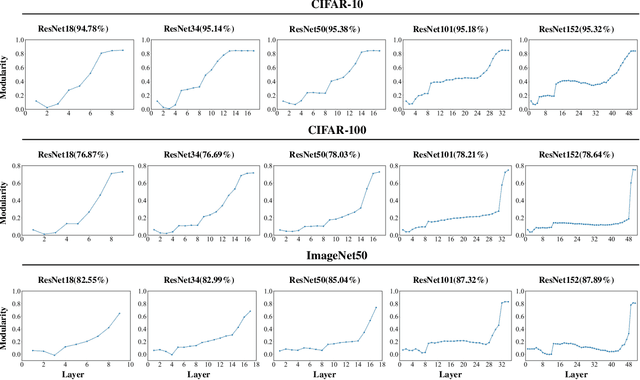
There are good arguments to support the claim that feature representations eventually transition from general to specific in deep neural networks (DNNs), but this transition remains relatively underexplored. In this work, we move a tiny step towards understanding the transition of feature representations. We first characterize this transition by analyzing the class separation in intermediate layers, and next model the process of class separation as community evolution in dynamic graphs. Then, we introduce modularity, a common metric in graph theory, to quantify the evolution of communities. We find that modularity tends to rise as the layer goes deeper, but descends or reaches a plateau at particular layers. Through an asymptotic analysis, we show that modularity can provide quantitative analysis of the transition of the feature representations. With the insight on feature representations, we demonstrate that modularity can also be used to identify and locate redundant layers in DNNs, which provides theoretical guidance for layer pruning. Based on this inspiring finding, we propose a layer-wise pruning method based on modularity. Further experiments show that our method can prune redundant layers with minimal impact on performance. The codes are available at https://github.com/yaolu-zjut/Dynamic-Graphs-Construction.