 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Data Imbalances in Federated Semi-supervised Learning with Dual Regulators
Jul 16, 2023



Federated learning has become a popular method to learn from decentralized heterogeneous data. Federated semi-supervised learning (FSSL) emerges to train models from a small fraction of labeled data due to label scarcity on decentralized clients. Existing FSSL methods assume independent and identically distributed (IID) labeled data across clients and consistent class distribution between labeled and unlabeled data within a client. This work studies a more practical and challenging scenario of FSSL, where data distribution is different not only across clients but also within a client between labeled and unlabeled data. To address this challenge, we propose a novel FSSL framework with dual regulators, FedDure.} FedDure lifts the previous assumption with a coarse-grained regulator (C-reg) and a fine-grained regulator (F-reg): C-reg regularizes the updating of the local model by tracking the learning effect on labeled data distribution; F-reg learns an adaptive weighting scheme tailored for unlabeled instances in each client. We further formulate the client model training as bi-level optimization that adaptively optimizes the model in the client with two regulators. Theoretically, we show the convergence guarantee of the dual regulators. Empirically, we demonstrate that FedDure is superior to the existing methods across a wide range of settings, notably by more than 11% on CIFAR-10 and CINIC-10 datasets.
Exploring Inductive Biases in Contrastive Learning: A Clustering Perspective
May 17, 2023



This paper investigates the differences in data organization between contrastive and supervised learning methods, focusing on the concept of locally dense clusters. We introduce a novel metric, Relative Local Density (RLD), to quantitatively measure local density within clusters. Visual examples are provided to highlight the distinctions between locally dense clusters and globally dense ones. By comparing the clusters formed by contrastive and supervised learning, we reveal that contrastive learning generates locally dense clusters without global density, while supervised learning creates clusters with both local and global density. We further explore the use of a Graph Convolutional Network (GCN) classifier as an alternative to linear classifiers for handling locally dense clusters. Finally, we utilize t-SNE visualizations to substantiate the differences between the features generated by contrastive and supervised learning methods. We conclude by proposing future research directions, including the development of efficient classifiers tailored to contrastive learning and the creation of innovative augmentation algorithms.
Probing Visual-Audio Representation for Video Highlight Detection via Hard-Pairs Guided Contrastive Learning
Jun 21, 2022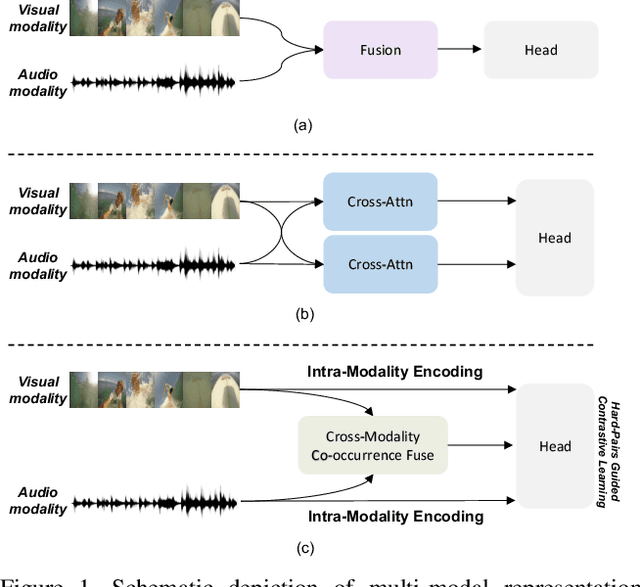

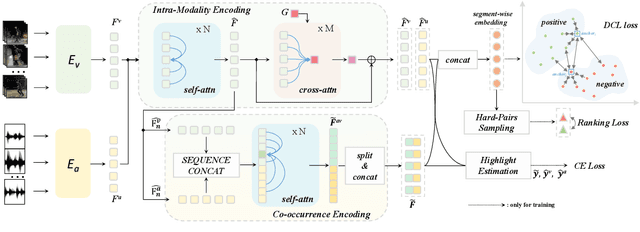
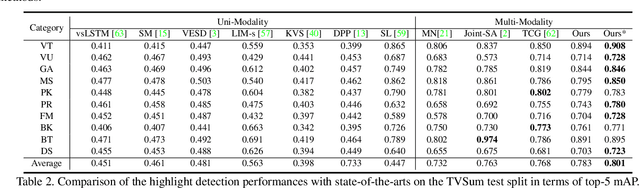
Video highlight detection is a crucial yet challenging problem that aims to identify the interesting moments in untrimmed videos. The key to this task lies in effective video representations that jointly pursue two goals, \textit{i.e.}, cross-modal representation learning and fine-grained feature discrimination. In this paper, these two challenges are tackled by not only enriching intra-modality and cross-modality relations for representation modeling but also shaping the features in a discriminative manner. Our proposed method mainly leverages the intra-modality encoding and cross-modality co-occurrence encoding for fully representation modeling. Specifically, intra-modality encoding augments the modality-wise features and dampens irrelevant modality via within-modality relation learning in both audio and visual signals. Meanwhile, cross-modality co-occurrence encoding focuses on the co-occurrence inter-modality relations and selectively captures effective information among multi-modality. The multi-modal representation is further enhanced by the global information abstracted from the local context. In addition, we enlarge the discriminative power of feature embedding with a hard-pairs guided contrastive learning (HPCL) scheme. A hard-pairs sampling strategy is further employed to mine the hard samples for improving feature discrimination in HPCL. Extensive experiments conducted on two benchmarks demonstrate the effectiveness and superiority of our proposed methods compared to other state-of-the-art methods.
Pyramid Region-based Slot Attention Network for Temporal Action Proposal Generation
Jun 21, 2022
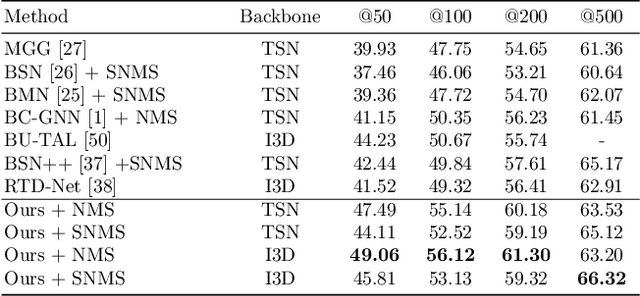
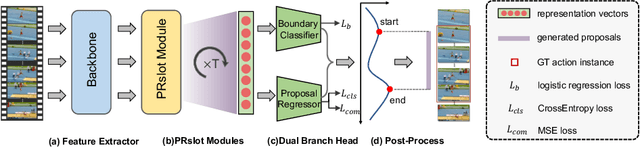

It has been found that temporal action proposal generation, which aims to discover the temporal action instances within the range of the start and end frames in the untrimmed videos, can largely benefit from proper temporal and semantic context exploitation. The latest efforts were dedicated to considering the temporal context and similarity-based semantic contexts through self-attention modules. However, they still suffer from cluttered background information and limited contextual feature learning. In this paper, we propose a novel Pyramid Region-based Slot Attention (PRSlot) module to address these issues. Instead of using the similarity computation, our PRSlot module directly learns the local relations in an encoder-decoder manner and generates the representation of a local region enhanced based on the attention over input features called \textit{slot}. Specifically, upon the input snippet-level features, PRSlot module takes the target snippet as \textit{query}, its surrounding region as \textit{key} and then generates slot representations for each \textit{query-key} slot by aggregating the local snippet context with a parallel pyramid strategy. Based on PRSlot modules, we present a novel Pyramid Region-based Slot Attention Network termed PRSA-Net to learn a unified visual representation with rich temporal and semantic context for better proposal generation. Extensive experiments are conducted on two widely adopted THUMOS14 and ActivityNet-1.3 benchmarks. Our PRSA-Net outperforms other state-of-the-art methods. In particular, we improve the AR@100 from the previous best 50.67% to 56.12% for proposal generation and raise the mAP under 0.5 tIoU from 51.9\% to 58.7\% for action detection on THUMOS14. \textit{Code is available at} \url{https://github.com/handhand123/PRSA-Net}
Better Teacher Better Student: Dynamic Prior Knowledge for Knowledge Distillation
Jun 14, 2022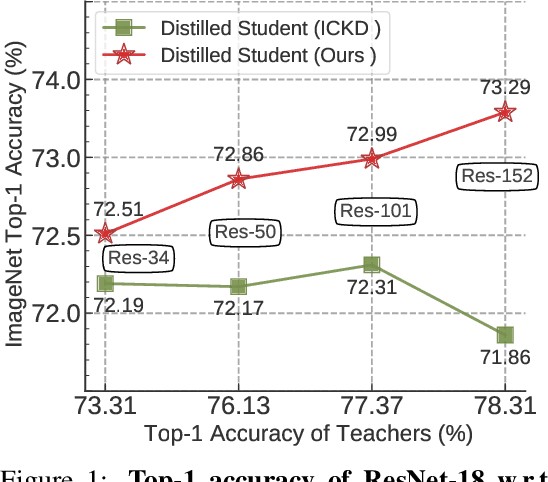
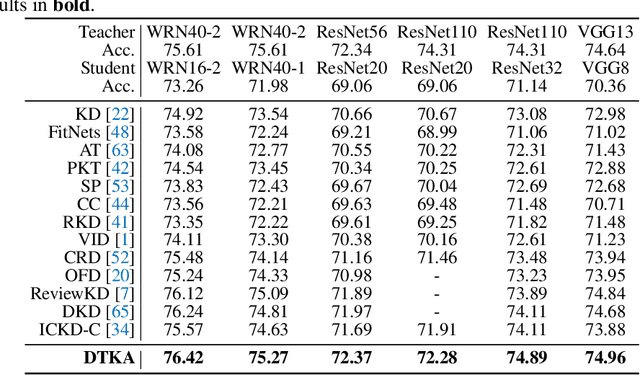
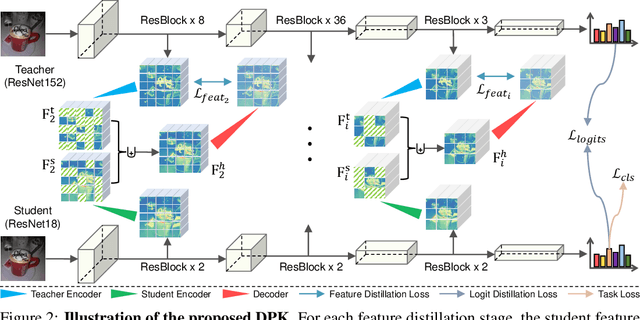

Knowledge distillation (KD) has shown very promising capabilities in transferring learning representations from large models (teachers) to small models (students). However, as the capacity gap between students and teachers becomes larger, existing KD methods fail to achieve better results. Our work shows that the 'prior knowledge' is vital to KD, especially when applying large teachers. Particularly, we propose the dynamic prior knowledge (DPK), which integrates part of the teacher's features as the prior knowledge before the feature distillation. This means that our method also takes the teacher's feature as `input', not just `target'. Besides, we dynamically adjust the ratio of the prior knowledge during the training phase according to the feature gap, thus guiding the student in an appropriate difficulty. To evaluate the proposed method, we conduct extensive experiments on two image classification benchmarks (i.e. CIFAR100 and ImageNet) and an object detection benchmark (i.e. MS COCO). The results demonstrate the superiority of our method in performance under varying settings. More importantly, our DPK makes the performance of the student model is positively correlated with that of the teacher model, which means that we can further boost the accuracy of students by applying larger teachers. Our codes will be publicly available for the reproducibility.
GroupFormer: Group Activity Recognition with Clustered Spatial-Temporal Transformer
Aug 28, 2021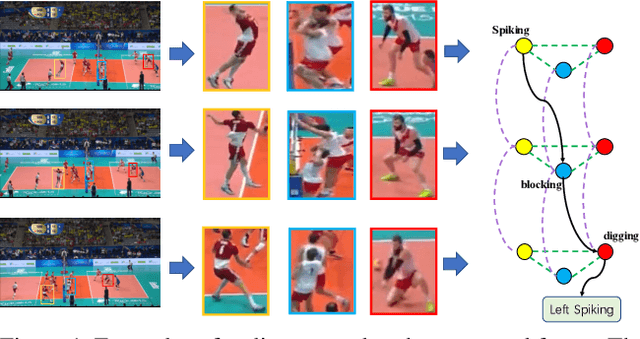
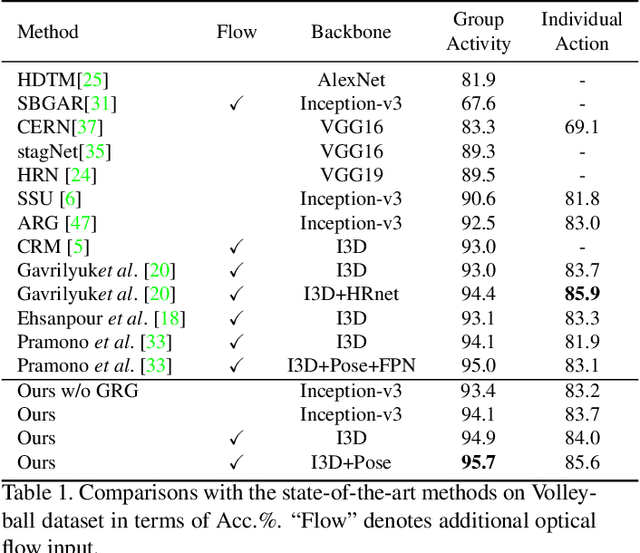
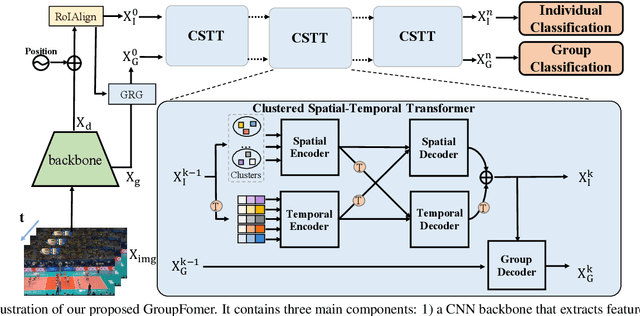
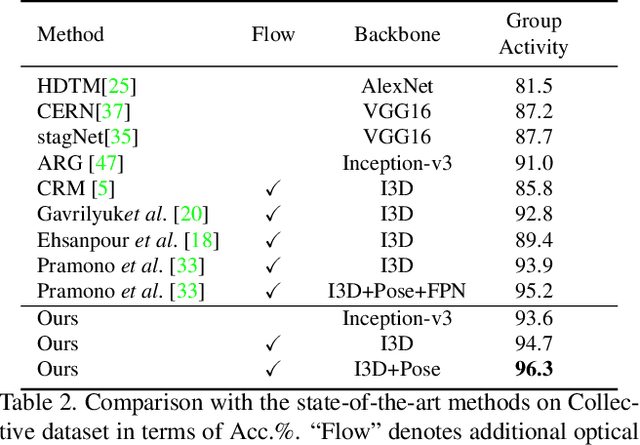
Group activity recognition is a crucial yet challenging problem, whose core lies in fully exploring spatial-temporal interactions among individuals and generating reasonable group representations. However, previous methods either model spatial and temporal information separately, or directly aggregate individual features to form group features. To address these issues, we propose a novel group activity recognition network termed GroupFormer. It captures spatial-temporal contextual information jointly to augment the individual and group representations effectively with a clustered spatial-temporal transformer. Specifically, our GroupFormer has three appealing advantages: (1) A tailor-modified Transformer, Clustered Spatial-Temporal Transformer, is proposed to enhance the individual representation and group representation. (2) It models the spatial and temporal dependencies integrally and utilizes decoders to build the bridge between the spatial and temporal information. (3) A clustered attention mechanism is utilized to dynamically divide individuals into multiple clusters for better learning activity-aware semantic representations. Moreover, experimental results show that the proposed framework outperforms state-of-the-art methods on the Volleyball dataset and Collective Activity dataset. Code is available at https://github.com/xueyee/GroupFormer.
Video Crowd Localization with Multi-focus Gaussian Neighbor Attention and a Large-Scale Benchmark
Jul 20, 2021
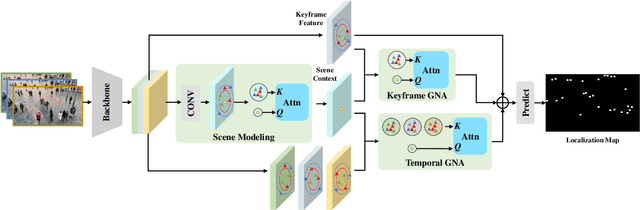

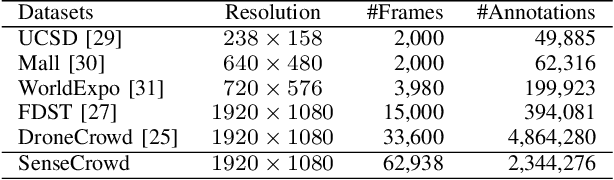
Video crowd localization is a crucial yet challenging task, which aims to estimate exact locations of human heads in the given crowded videos. To model spatial-temporal dependencies of human mobility, we propose a multi-focus Gaussian neighbor attention (GNA), which can effectively exploit long-range correspondences while maintaining the spatial topological structure of the input videos. In particular, our GNA can also capture the scale variation of human heads well using the equipped multi-focus mechanism. Based on the multi-focus GNA, we develop a unified neural network called GNANet to accurately locate head centers in video clips by fully aggregating spatial-temporal information via a scene modeling module and a context cross-attention module. Moreover, to facilitate future researches in this field, we introduce a large-scale crowded video benchmark named SenseCrowd, which consists of 60K+ frames captured in various surveillance scenarios and 2M+ head annotations. Finally, we conduct extensive experiments on three datasets including our SenseCrowd, and the experiment results show that the proposed method is capable to achieve state-of-the-art performance for both video crowd localization and counting. The code and the dataset will be released.
Differentially-private Federated Neural Architecture Search
Jun 22, 2020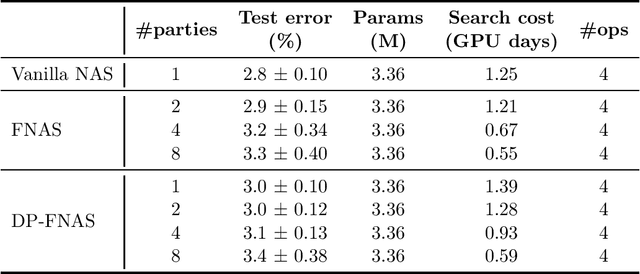
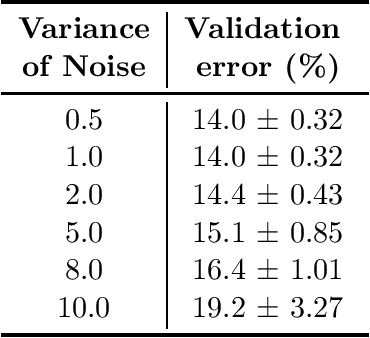
Neural architecture search, which aims to automatically search for architectures (e.g., convolution, max pooling) of neural networks that maximize validation performance, has achieved remarkable progress recently. In many application scenarios, several parties would like to collaboratively search for a shared neural architecture by leveraging data from all parties. However, due to privacy concerns, no party wants its data to be seen by other parties. To address this problem, we propose federated neural architecture search (FNAS), where different parties collectively search for a differentiable architecture by exchanging gradients of architecture variables without exposing their data to other parties. To further preserve privacy, we study differentially-private FNAS (DP-FNAS), which adds random noise to the gradients of architecture variables. We provide theoretical guarantees of DP-FNAS in achieving differential privacy. Experiments show that DP-FNAS can search highly-performant neural architectures while protecting the privacy of individual parties. The code is available at https://github.com/UCSD-AI4H/DP-FNAS