 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePISA: Piecewise Sparse Attention Is Wiser for Efficient Diffusion Transformers
Feb 03, 2026Diffusion Transformers are fundamental for video and image generation, but their efficiency is bottlenecked by the quadratic complexity of attention. While block sparse attention accelerates computation by attending only critical key-value blocks, it suffers from degradation at high sparsity by discarding context. In this work, we discover that attention scores of non-critical blocks exhibit distributional stability, allowing them to be approximated accurately and efficiently rather than discarded, which is essentially important for sparse attention design. Motivated by this key insight, we propose PISA, a training-free Piecewise Sparse Attention that covers the full attention span with sub-quadratic complexity. Unlike the conventional keep-or-drop paradigm that directly drop the non-critical block information, PISA introduces a novel exact-or-approximate strategy: it maintains exact computation for critical blocks while efficiently approximating the remainder through block-wise Taylor expansion. This design allows PISA to serve as a faithful proxy to full attention, effectively bridging the gap between speed and quality. Experimental results demonstrate that PISA achieves 1.91 times and 2.57 times speedups on Wan2.1-14B and Hunyuan-Video, respectively, while consistently maintaining the highest quality among sparse attention methods. Notably, even for image generation on FLUX, PISA achieves a 1.2 times acceleration without compromising visual quality. Code is available at: https://github.com/xie-lab-ml/piecewise-sparse-attention.
Autoregressive Image Generation with Randomized Parallel Decoding
Mar 13, 2025We introduce ARPG, a novel visual autoregressive model that enables randomized parallel generation, addressing the inherent limitations of conventional raster-order approaches, which hinder inference efficiency and zero-shot generalization due to their sequential, predefined token generation order. Our key insight is that effective random-order modeling necessitates explicit guidance for determining the position of the next predicted token. To this end, we propose a novel guided decoding framework that decouples positional guidance from content representation, encoding them separately as queries and key-value pairs. By directly incorporating this guidance into the causal attention mechanism, our approach enables fully random-order training and generation, eliminating the need for bidirectional attention. Consequently, ARPG readily generalizes to zero-shot tasks such as image inpainting, outpainting, and resolution expansion. Furthermore, it supports parallel inference by concurrently processing multiple queries using a shared KV cache. On the ImageNet-1K 256 benchmark, our approach attains an FID of 1.94 with only 64 sampling steps, achieving over a 20-fold increase in throughput while reducing memory consumption by over 75% compared to representative recent autoregressive models at a similar scale.
Admitting Ignorance Helps the Video Question Answering Models to Answer
Jan 15, 2025
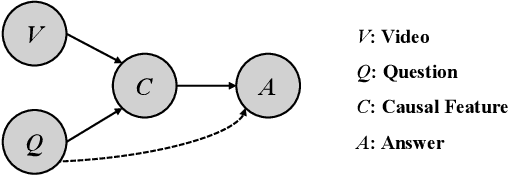
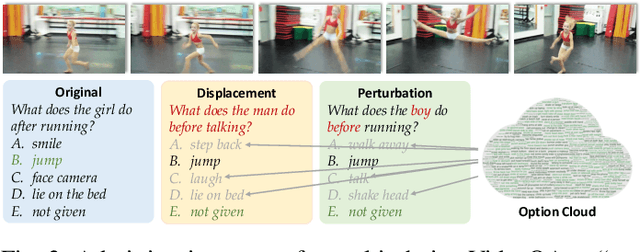
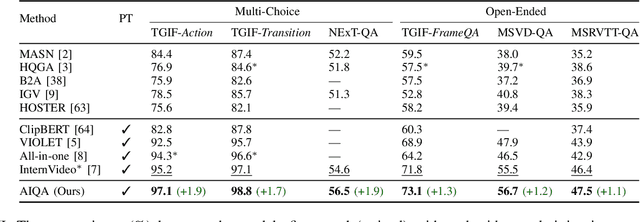
Significant progress has been made in the field of video question answering (VideoQA) thanks to deep learning and large-scale pretraining. Despite the presence of sophisticated model structures and powerful video-text foundation models, most existing methods focus solely on maximizing the correlation between answers and video-question pairs during training. We argue that these models often establish shortcuts, resulting in spurious correlations between questions and answers, especially when the alignment between video and text data is suboptimal. To address these spurious correlations, we propose a novel training framework in which the model is compelled to acknowledge its ignorance when presented with an intervened question, rather than making guesses solely based on superficial question-answer correlations. We introduce methodologies for intervening in questions, utilizing techniques such as displacement and perturbation, and design frameworks for the model to admit its lack of knowledge in both multi-choice VideoQA and open-ended settings. In practice, we integrate a state-of-the-art model into our framework to validate its effectiveness. The results clearly demonstrate that our framework can significantly enhance the performance of VideoQA models with minimal structural modifications.
Can Large Language Models Analyze Graphs like Professionals? A Benchmark, Datasets and Models
Sep 29, 2024



The need to analyze graphs is ubiquitous across various fields, from social networks to biological research and recommendation systems. Therefore, enabling the ability of large language models (LLMs) to process graphs is an important step toward more advanced general intelligence. However, current LLM benchmarks on graph analysis require models to directly reason over the prompts describing graph topology, and are thus limited to small graphs with only a few dozens of nodes. In contrast, human experts typically write programs based on popular libraries for task solving, and can thus handle graphs with different scales. To this end, a question naturally arises: can LLMs analyze graphs like professionals? In this paper, we introduce ProGraph, a manually crafted benchmark containing 3 categories of graph tasks. The benchmark expects solutions based on programming instead of directly reasoning over raw inputs. Our findings reveal that the performance of current LLMs is unsatisfactory, with the best model achieving only 36% accuracy. To bridge this gap, we propose LLM4Graph datasets, which include crawled documents and auto-generated codes based on 6 widely used graph libraries. By augmenting closed-source LLMs with document retrieval and fine-tuning open-source ones on the codes, we show 11-32% absolute improvements in their accuracies. Our results underscore that the capabilities of LLMs in handling structured data are still under-explored, and show the effectiveness of LLM4Graph in enhancing LLMs' proficiency of graph analysis. The benchmark, datasets and enhanced open-source models are available at https://github.com/BUPT-GAMMA/ProGraph.
Scalable Autoregressive Image Generation with Mamba
Aug 22, 2024We introduce AiM, an autoregressive (AR) image generative model based on Mamba architecture. AiM employs Mamba, a novel state-space model characterized by its exceptional performance for long-sequence modeling with linear time complexity, to supplant the commonly utilized Transformers in AR image generation models, aiming to achieve both superior generation quality and enhanced inference speed. Unlike existing methods that adapt Mamba to handle two-dimensional signals via multi-directional scan, AiM directly utilizes the next-token prediction paradigm for autoregressive image generation. This approach circumvents the need for extensive modifications to enable Mamba to learn 2D spatial representations. By implementing straightforward yet strategically targeted modifications for visual generative tasks, we preserve Mamba's core structure, fully exploiting its efficient long-sequence modeling capabilities and scalability. We provide AiM models in various scales, with parameter counts ranging from 148M to 1.3B. On the ImageNet1K 256*256 benchmark, our best AiM model achieves a FID of 2.21, surpassing all existing AR models of comparable parameter counts and demonstrating significant competitiveness against diffusion models, with 2 to 10 times faster inference speed. Code is available at https://github.com/hp-l33/AiM
Visual-Text Cross Alignment: Refining the Similarity Score in Vision-Language Models
Jun 05, 2024It has recently been discovered that using a pre-trained vision-language model (VLM), e.g., CLIP, to align a whole query image with several finer text descriptions generated by a large language model can significantly enhance zero-shot performance. However, in this paper, we empirically find that the finer descriptions tend to align more effectively with local areas of the query image rather than the whole image, and then we theoretically validate this finding. Thus, we present a method called weighted visual-text cross alignment (WCA). This method begins with a localized visual prompting technique, designed to identify local visual areas within the query image. The local visual areas are then cross-aligned with the finer descriptions by creating a similarity matrix using the pre-trained VLM. To determine how well a query image aligns with each category, we develop a score function based on the weighted similarities in this matrix. Extensive experiments demonstrate that our method significantly improves zero-shot performance across various datasets, achieving results that are even comparable to few-shot learning methods.
Sports-QA: A Large-Scale Video Question Answering Benchmark for Complex and Professional Sports
Jan 07, 2024Reasoning over sports videos for question answering is an important task with numerous applications, such as player training and information retrieval. However, this task has not been explored due to the lack of relevant datasets and the challenging nature it presents. Most datasets for video question answering (VideoQA) focus mainly on general and coarse-grained understanding of daily-life videos, which is not applicable to sports scenarios requiring professional action understanding and fine-grained motion analysis. In this paper, we introduce the first dataset, named Sports-QA, specifically designed for the sports VideoQA task. The Sports-QA dataset includes various types of questions, such as descriptions, chronologies, causalities, and counterfactual conditions, covering multiple sports. Furthermore, to address the characteristics of the sports VideoQA task, we propose a new Auto-Focus Transformer (AFT) capable of automatically focusing on particular scales of temporal information for question answering. We conduct extensive experiments on Sports-QA, including baseline studies and the evaluation of different methods. The results demonstrate that our AFT achieves state-of-the-art performance.
Answering from Sure to Uncertain: Uncertainty-Aware Curriculum Learning for Video Question Answering
Jan 03, 2024While significant advancements have been made in video question answering (VideoQA), the potential benefits of enhancing model generalization through tailored difficulty scheduling have been largely overlooked in existing research. This paper seeks to bridge that gap by incorporating VideoQA into a curriculum learning (CL) framework that progressively trains models from simpler to more complex data. Recognizing that conventional self-paced CL methods rely on training loss for difficulty measurement, which might not accurately reflect the intricacies of video-question pairs, we introduce the concept of uncertainty-aware CL. Here, uncertainty serves as the guiding principle for dynamically adjusting the difficulty. Furthermore, we address the challenge posed by uncertainty by presenting a probabilistic modeling approach for VideoQA. Specifically, we conceptualize VideoQA as a stochastic computation graph, where the hidden representations are treated as stochastic variables. This yields two distinct types of uncertainty: one related to the inherent uncertainty in the data and another pertaining to the model's confidence. In practice, we seamlessly integrate the VideoQA model into our framework and conduct comprehensive experiments. The findings affirm that our approach not only achieves enhanced performance but also effectively quantifies uncertainty in the context of VideoQA.
Doubly Deformable Aggregation of Covariance Matrices for Few-shot Segmentation
Jul 30, 2022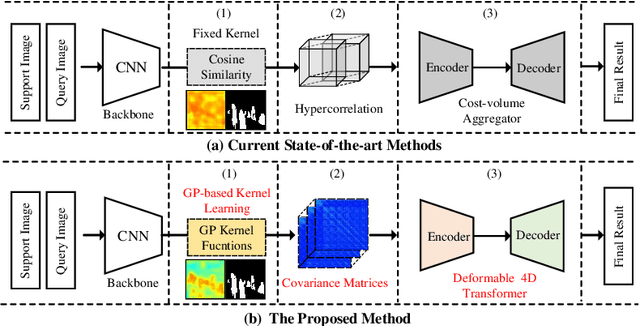
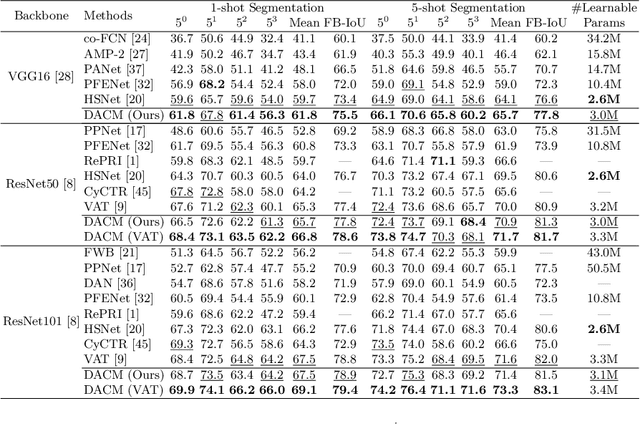

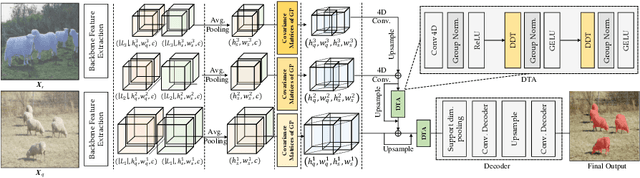
Training semantic segmentation models with few annotated samples has great potential in various real-world applications. For the few-shot segmentation task, the main challenge is how to accurately measure the semantic correspondence between the support and query samples with limited training data. To address this problem, we propose to aggregate the learnable covariance matrices with a deformable 4D Transformer to effectively predict the segmentation map. Specifically, in this work, we first devise a novel hard example mining mechanism to learn covariance kernels for the Gaussian process. The learned covariance kernel functions have great advantages over existing cosine similarity-based methods in correspondence measurement. Based on the learned covariance kernels, an efficient doubly deformable 4D Transformer module is designed to adaptively aggregate feature similarity maps into segmentation results. By combining these two designs, the proposed method can not only set new state-of-the-art performance on public benchmarks, but also converge extremely faster than existing methods. Experiments on three public datasets have demonstrated the effectiveness of our method.
Video Crowd Localization with Multi-focus Gaussian Neighbor Attention and a Large-Scale Benchmark
Jul 20, 2021
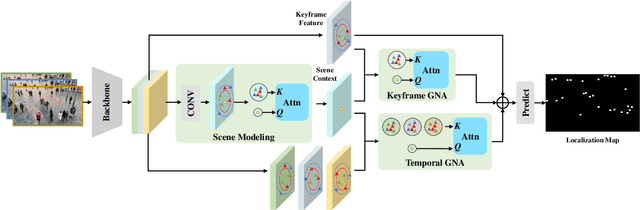

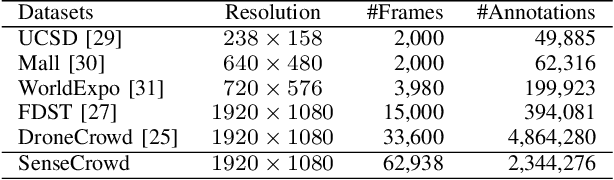
Video crowd localization is a crucial yet challenging task, which aims to estimate exact locations of human heads in the given crowded videos. To model spatial-temporal dependencies of human mobility, we propose a multi-focus Gaussian neighbor attention (GNA), which can effectively exploit long-range correspondences while maintaining the spatial topological structure of the input videos. In particular, our GNA can also capture the scale variation of human heads well using the equipped multi-focus mechanism. Based on the multi-focus GNA, we develop a unified neural network called GNANet to accurately locate head centers in video clips by fully aggregating spatial-temporal information via a scene modeling module and a context cross-attention module. Moreover, to facilitate future researches in this field, we introduce a large-scale crowded video benchmark named SenseCrowd, which consists of 60K+ frames captured in various surveillance scenarios and 2M+ head annotations. Finally, we conduct extensive experiments on three datasets including our SenseCrowd, and the experiment results show that the proposed method is capable to achieve state-of-the-art performance for both video crowd localization and counting. The code and the dataset will be released.