 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbulence-Robust Dynamic Object Segmentation with Multi-Signal Priors and SAM2 Refinement
May 28, 2026This technical report presents our solution for the CVPR 2026 UG2+ Challenge Track 3: Dynamic Object Segmentation in Turbulence (DOST). We design a training-free multi-signal segmentation pipeline that combines pretrained motion estimation, self-supervised semantic priors, background anomaly modeling, manually calibrated proposal fusion, and SAM2-based mask refinement. The method uses RAFT for dense motion responses, DINOv2 for semantic objectness priors, ViBe for training-free background modeling, and pretrained SAM2 for box-prompt mask refinement. Instead of optimizing an end-to-end segmentation network, our system operates entirely in inference mode. This design is suitable for the DOST setting, where severe atmospheric turbulence produces pseudo-motion, blur, and intermittent target visibility, making a single motion cue unreliable. The final submitted masks are evaluated by the official leaderboard, which reports 0.425041 mIoU and 0.457206 mDice. Since no task-specific model training or fine-tuning is performed, stronger learned temporal association, adaptive proposal selection, or task-specific adaptation may further improve the system.
ThermoSplat: Cross-Modal 3D Gaussian Splatting with Feature Modulation and Geometry Decoupling
Jan 22, 2026Multi-modal scene reconstruction integrating RGB and thermal infrared data is essential for robust environmental perception across diverse lighting and weather conditions. However, extending 3D Gaussian Splatting (3DGS) to multi-spectral scenarios remains challenging. Current approaches often struggle to fully leverage the complementary information of multi-modal data, typically relying on mechanisms that either tend to neglect cross-modal correlations or leverage shared representations that fail to adaptively handle the complex structural correlations and physical discrepancies between spectrums. To address these limitations, we propose ThermoSplat, a novel framework that enables deep spectral-aware reconstruction through active feature modulation and adaptive geometry decoupling. First, we introduce a Cross-Modal FiLM Modulation mechanism that dynamically conditions shared latent features on thermal structural priors, effectively guiding visible texture synthesis with reliable cross-modal geometric cues. Second, to accommodate modality-specific geometric inconsistencies, we propose a Modality-Adaptive Geometric Decoupling scheme that learns independent opacity offsets and executes an independent rasterization pass for the thermal branch. Additionally, a hybrid rendering pipeline is employed to integrate explicit Spherical Harmonics with implicit neural decoding, ensuring both semantic consistency and high-frequency detail preservation. Extensive experiments on the RGBT-Scenes dataset demonstrate that ThermoSplat achieves state-of-the-art rendering quality across both visible and thermal spectrums.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Reconstructive Sequence-Graph Network for Video Summarization
May 10, 2021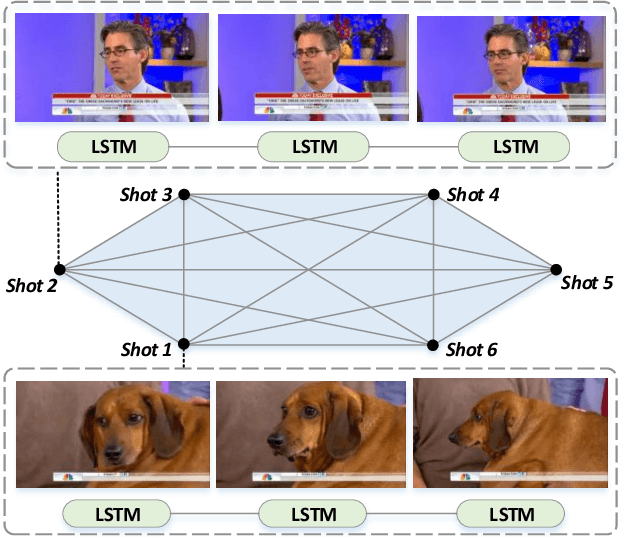
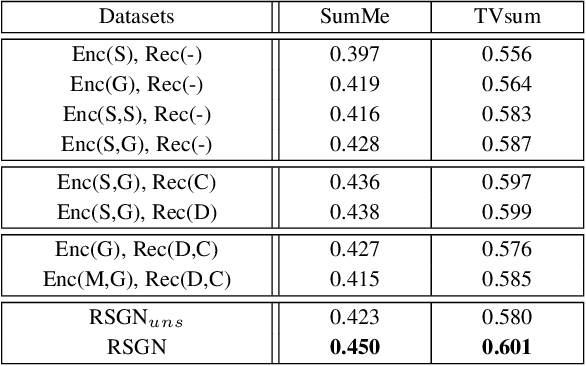
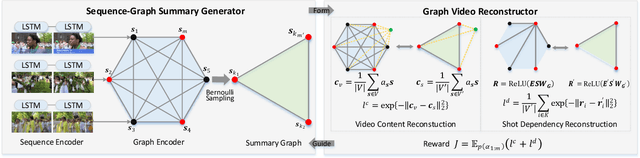
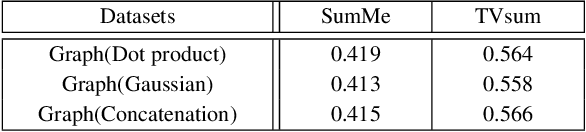
Exploiting the inner-shot and inter-shot dependencies is essential for key-shot based video summarization. Current approaches mainly devote to modeling the video as a frame sequence by recurrent neural networks. However, one potential limitation of the sequence models is that they focus on capturing local neighborhood dependencies while the high-order dependencies in long distance are not fully exploited. In general, the frames in each shot record a certain activity and vary smoothly over time, but the multi-hop relationships occur frequently among shots. In this case, both the local and global dependencies are important for understanding the video content. Motivated by this point, we propose a Reconstructive Sequence-Graph Network (RSGN) to encode the frames and shots as sequence and graph hierarchically, where the frame-level dependencies are encoded by Long Short-Term Memory (LSTM), and the shot-level dependencies are captured by the Graph Convolutional Network (GCN). Then, the videos are summarized by exploiting both the local and global dependencies among shots. Besides, a reconstructor is developed to reward the summary generator, so that the generator can be optimized in an unsupervised manner, which can avert the lack of annotated data in video summarization. Furthermore, under the guidance of reconstruction loss, the predicted summary can better preserve the main video content and shot-level dependencies. Practically, the experimental results on three popular datasets i.e., SumMe, TVsum and VTW) have demonstrated the superiority of our proposed approach to the summarization task.
Audio Description from Image by Modal Translation Network
Mar 18, 2021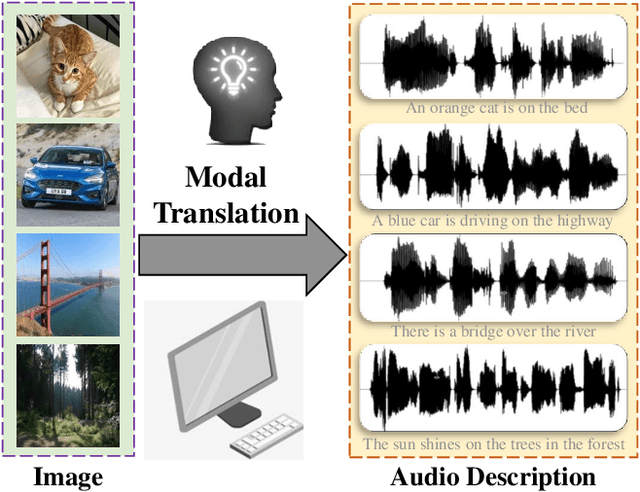
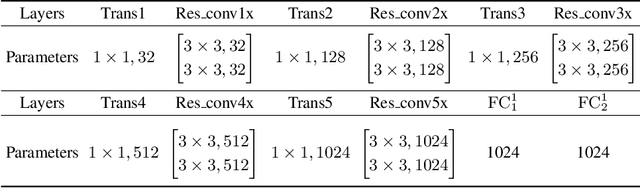
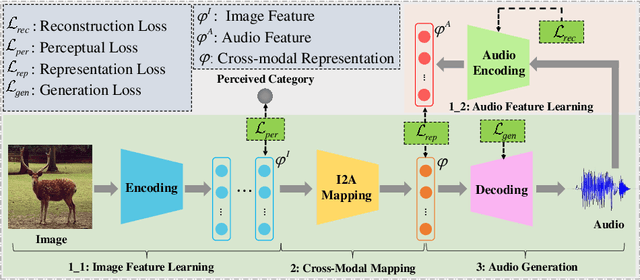

Audio is the main form for the visually impaired to obtain information. In reality, all kinds of visual data always exist, but audio data does not exist in many cases. In order to help the visually impaired people to better perceive the information around them, an image-to-audio-description (I2AD) task is proposed to generate audio descriptions from images in this paper. To complete this totally new task, a modal translation network (MT-Net) from visual to auditory sense is proposed. The proposed MT-Net includes three progressive sub-networks: 1) feature learning, 2) cross-modal mapping, and 3) audio generation. First, the feature learning sub-network aims to learn semantic features from image and audio, including image feature learning and audio feature learning. Second, the cross-modal mapping sub-network transforms the image feature into a cross-modal representation with the same semantic concept as the audio feature. In this way, the correlation of inter-modal data is effectively mined for easing the heterogeneous gap between image and audio. Finally, the audio generation sub-network is designed to generate the audio waveform from the cross-modal representation. The generated audio waveform is interpolated to obtain the corresponding audio file according to the sample frequency. Being the first attempt to explore the I2AD task, three large-scale datasets with plenty of manual audio descriptions are built. Experiments on the datasets verify the feasibility of generating intelligible audio from an image directly and the effectiveness of proposed method.
Bio-Inspired Representation Learning for Visual Attention Prediction
Mar 09, 2021
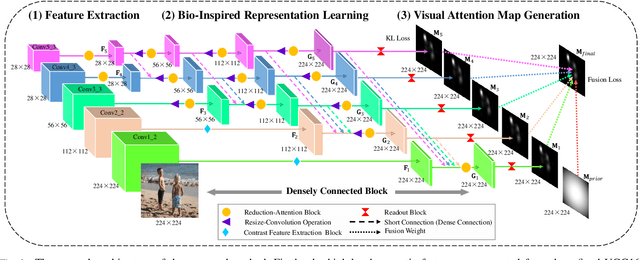
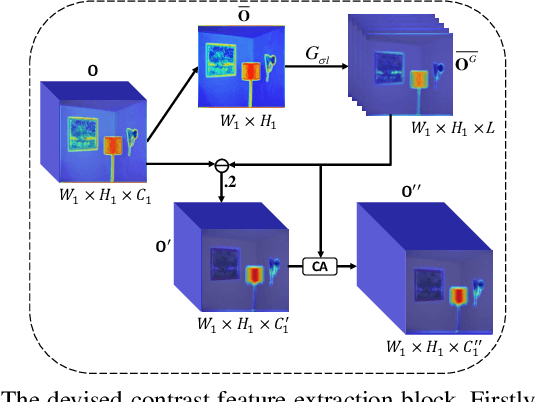
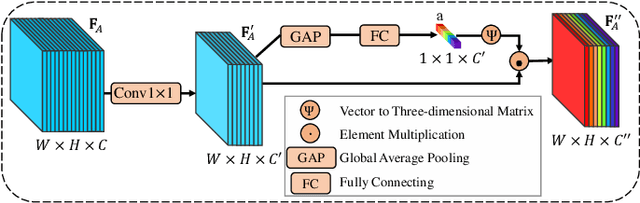
Visual Attention Prediction (VAP) is a significant and imperative issue in the field of computer vision. Most of existing VAP methods are based on deep learning. However, they do not fully take advantage of the low-level contrast features while generating the visual attention map. In this paper, a novel VAP method is proposed to generate visual attention map via bio-inspired representation learning. The bio-inspired representation learning combines both low-level contrast and high-level semantic features simultaneously, which are developed by the fact that human eye is sensitive to the patches with high contrast and objects with high semantics. The proposed method is composed of three main steps: 1) feature extraction, 2) bio-inspired representation learning and 3) visual attention map generation. Firstly, the high-level semantic feature is extracted from the refined VGG16, while the low-level contrast feature is extracted by the proposed contrast feature extraction block in a deep network. Secondly, during bio-inspired representation learning, both the extracted low-level contrast and high-level semantic features are combined by the designed densely connected block, which is proposed to concatenate various features scale by scale. Finally, the weighted-fusion layer is exploited to generate the ultimate visual attention map based on the obtained representations after bio-inspired representation learning. Extensive experiments are performed to demonstrate the effectiveness of the proposed method.
Vision-to-Language Tasks Based on Attributes and Attention Mechanism
May 29, 2019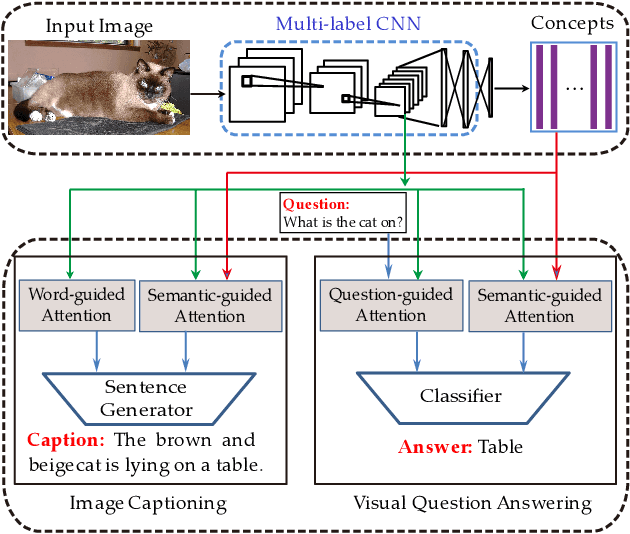
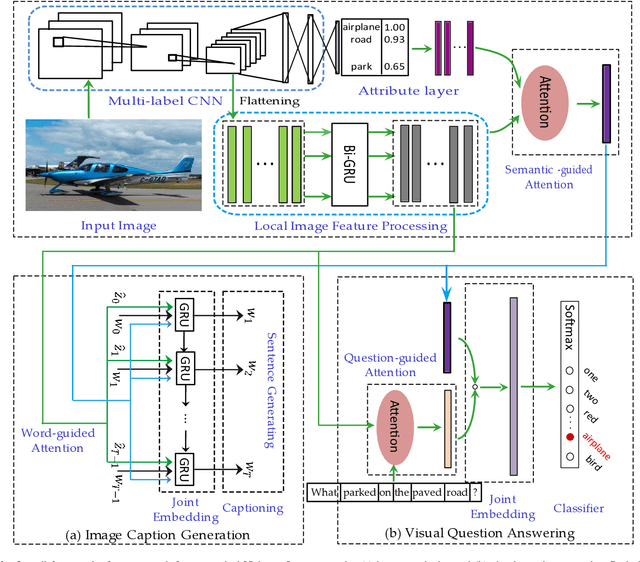
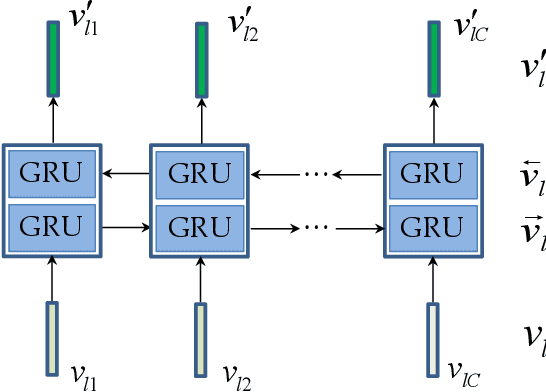
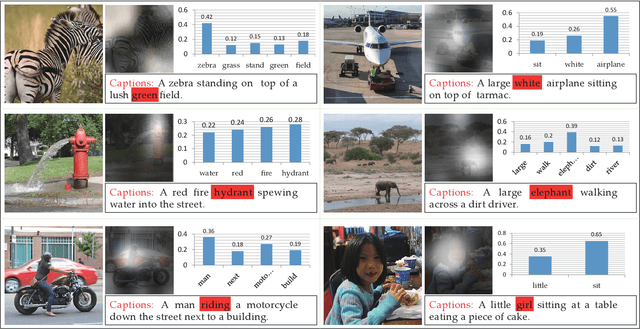
Vision-to-language tasks aim to integrate computer vision and natural language processing together, which has attracted the attention of many researchers. For typical approaches, they encode image into feature representations and decode it into natural language sentences. While they neglect high-level semantic concepts and subtle relationships between image regions and natural language elements. To make full use of these information, this paper attempt to exploit the text guided attention and semantic-guided attention (SA) to find the more correlated spatial information and reduce the semantic gap between vision and language. Our method includes two level attention networks. One is the text-guided attention network which is used to select the text-related regions. The other is SA network which is used to highlight the concept-related regions and the region-related concepts. At last, all these information are incorporated to generate captions or answers. Practically, image captioning and visual question answering experiments have been carried out, and the experimental results have shown the excellent performance of the proposed approach.
Hierarchical Recurrent Neural Network for Video Summarization
Apr 28, 2019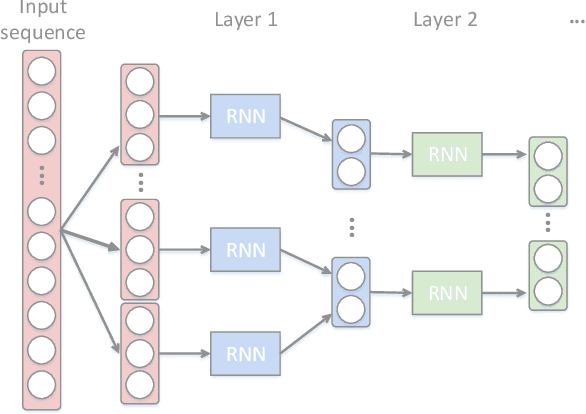

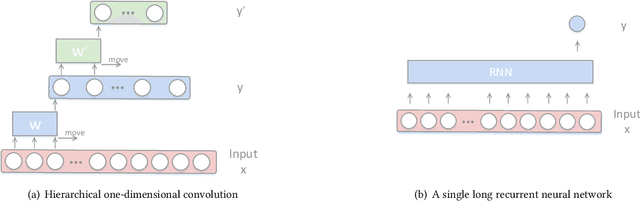
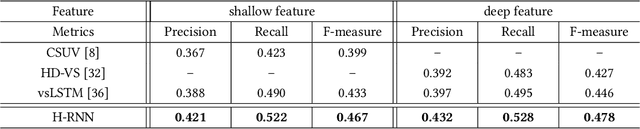
Exploiting the temporal dependency among video frames or subshots is very important for the task of video summarization. Practically, RNN is good at temporal dependency modeling, and has achieved overwhelming performance in many video-based tasks, such as video captioning and classification. However, RNN is not capable enough to handle the video summarization task, since traditional RNNs, including LSTM, can only deal with short videos, while the videos in the summarization task are usually in longer duration. To address this problem, we propose a hierarchical recurrent neural network for video summarization, called H-RNN in this paper. Specifically, it has two layers, where the first layer is utilized to encode short video subshots cut from the original video, and the final hidden state of each subshot is input to the second layer for calculating its confidence to be a key subshot. Compared to traditional RNNs, H-RNN is more suitable to video summarization, since it can exploit long temporal dependency among frames, meanwhile, the computation operations are significantly lessened. The results on two popular datasets, including the Combined dataset and VTW dataset, have demonstrated that the proposed H-RNN outperforms the state-of-the-arts.
A CNN-RNN Architecture for Multi-Label Weather Recognition
Apr 24, 2019


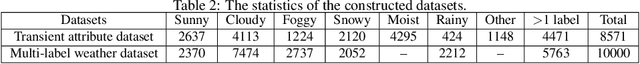
Weather Recognition plays an important role in our daily lives and many computer vision applications. However, recognizing the weather conditions from a single image remains challenging and has not been studied thoroughly. Generally, most previous works treat weather recognition as a single-label classification task, namely, determining whether an image belongs to a specific weather class or not. This treatment is not always appropriate, since more than one weather conditions may appear simultaneously in a single image. To address this problem, we make the first attempt to view weather recognition as a multi-label classification task, i.e., assigning an image more than one labels according to the displayed weather conditions. Specifically, a CNN-RNN based multi-label classification approach is proposed in this paper. The convolutional neural network (CNN) is extended with a channel-wise attention model to extract the most correlated visual features. The Recurrent Neural Network (RNN) further processes the features and excavates the dependencies among weather classes. Finally, the weather labels are predicted step by step. Besides, we construct two datasets for the weather recognition task and explore the relationships among different weather conditions. Experimental results demonstrate the superiority and effectiveness of the proposed approach. The new constructed datasets will be available at https://github.com/wzgwzg/Multi-Label-Weather-Recognition.
A General Framework for Edited Video and Raw Video Summarization
Apr 24, 2019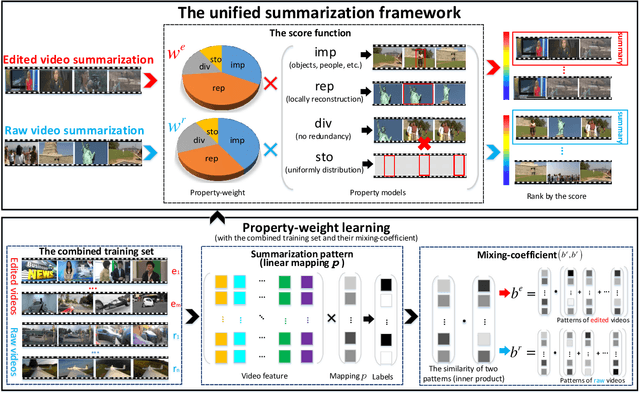
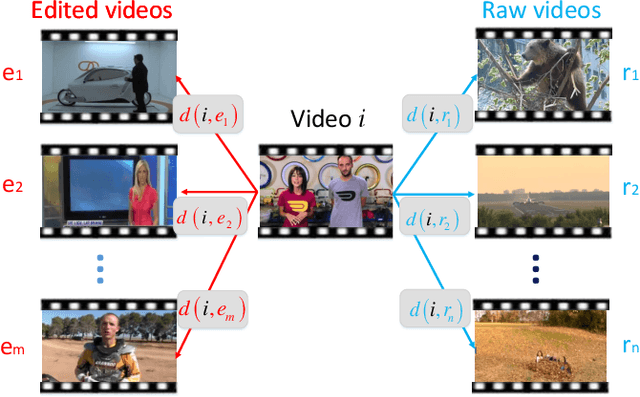
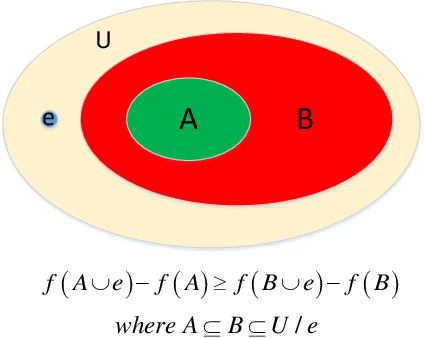
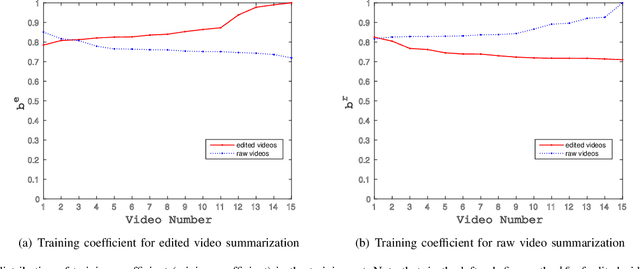
In this paper, we build a general summarization framework for both of edited video and raw video summarization. Overall, our work can be divided into three folds: 1) Four models are designed to capture the properties of video summaries, i.e., containing important people and objects (importance), representative to the video content (representativeness), no similar key-shots (diversity) and smoothness of the storyline (storyness). Specifically, these models are applicable to both edited videos and raw videos. 2) A comprehensive score function is built with the weighted combination of the aforementioned four models. Note that the weights of the four models in the score function, denoted as property-weight, are learned in a supervised manner. Besides, the property-weights are learned for edited videos and raw videos, respectively. 3) The training set is constructed with both edited videos and raw videos in order to make up the lack of training data. Particularly, each training video is equipped with a pair of mixing-coefficients which can reduce the structure mess in the training set caused by the rough mixture. We test our framework on three datasets, including edited videos, short raw videos and long raw videos. Experimental results have verified the effectiveness of the proposed framework.