 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Description from Image by Modal Translation Network
Paper and Code
Mar 18, 2021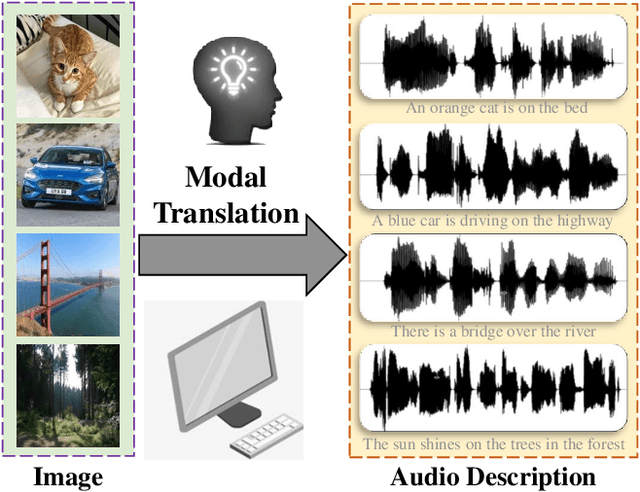
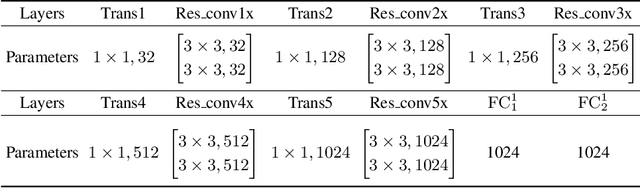
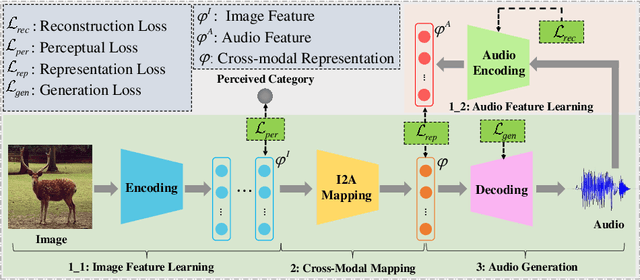

Audio is the main form for the visually impaired to obtain information. In reality, all kinds of visual data always exist, but audio data does not exist in many cases. In order to help the visually impaired people to better perceive the information around them, an image-to-audio-description (I2AD) task is proposed to generate audio descriptions from images in this paper. To complete this totally new task, a modal translation network (MT-Net) from visual to auditory sense is proposed. The proposed MT-Net includes three progressive sub-networks: 1) feature learning, 2) cross-modal mapping, and 3) audio generation. First, the feature learning sub-network aims to learn semantic features from image and audio, including image feature learning and audio feature learning. Second, the cross-modal mapping sub-network transforms the image feature into a cross-modal representation with the same semantic concept as the audio feature. In this way, the correlation of inter-modal data is effectively mined for easing the heterogeneous gap between image and audio. Finally, the audio generation sub-network is designed to generate the audio waveform from the cross-modal representation. The generated audio waveform is interpolated to obtain the corresponding audio file according to the sample frequency. Being the first attempt to explore the I2AD task, three large-scale datasets with plenty of manual audio descriptions are built. Experiments on the datasets verify the feasibility of generating intelligible audio from an image directly and the effectiveness of proposed method.