 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConInfer: Context-Aware Inference for Training-Free Open-Vocabulary Remote Sensing Segmentation
Mar 31, 2026Training-free open-vocabulary remote sensing segmentation (OVRSS), empowered by vision-language models, has emerged as a promising paradigm for achieving category-agnostic semantic understanding in remote sensing imagery. Existing approaches mainly focus on enhancing feature representations or mitigating modality discrepancies to improve patch-level prediction accuracy. However, such independent prediction schemes are fundamentally misaligned with the intrinsic characteristics of remote sensing data. In real-world applications, remote sensing scenes are typically large-scale and exhibit strong spatial as well as semantic correlations, making isolated patch-wise predictions insufficient for accurate segmentation. To address this limitation, we propose ConInfer, a context-aware inference framework for OVRSS that performs joint prediction across multiple spatial units while explicitly modeling their inter-unit semantic dependencies. By incorporating global contextual cues, our method significantly enhances segmentation consistency, robustness, and generalization in complex remote sensing environments. Extensive experiments on multiple benchmark datasets demonstrate that our approach consistently surpasses state-of-the-art per-pixel VLM-based baselines such as SegEarth-OV, achieving average improvements of 2.80% and 6.13% on open-vocabulary semantic segmentation and object extraction tasks, respectively. The implementation code is available at: https://github.com/Dog-Yang/ConInfer
Representation Discrepancy Bridging Method for Remote Sensing Image-Text Retrieval
May 22, 2025Remote Sensing Image-Text Retrieval (RSITR) plays a critical role in geographic information interpretation, disaster monitoring, and urban planning by establishing semantic associations between image and textual descriptions. Existing Parameter-Efficient Fine-Tuning (PEFT) methods for Vision-and-Language Pre-training (VLP) models typically adopt symmetric adapter structures for exploring cross-modal correlations. However, the strong discriminative nature of text modality may dominate the optimization process and inhibits image representation learning. The nonnegligible imbalanced cross-modal optimization remains a bottleneck to enhancing the model performance. To address this issue, this study proposes a Representation Discrepancy Bridging (RDB) method for the RSITR task. On the one hand, a Cross-Modal Asymmetric Adapter (CMAA) is designed to enable modality-specific optimization and improve feature alignment. The CMAA comprises a Visual Enhancement Adapter (VEA) and a Text Semantic Adapter (TSA). VEA mines fine-grained image features by Differential Attention (DA) mechanism, while TSA identifies key textual semantics through Hierarchical Attention (HA) mechanism. On the other hand, this study extends the traditional single-task retrieval framework to a dual-task optimization framework and develops a Dual-Task Consistency Loss (DTCL). The DTCL improves cross-modal alignment robustness through an adaptive weighted combination of cross-modal, classification, and exponential moving average consistency constraints. Experiments on RSICD and RSITMD datasets show that the proposed RDB method achieves a 6%-11% improvement in mR metrics compared to state-of-the-art PEFT methods and a 1.15%-2% improvement over the full fine-tuned GeoRSCLIP model.
Lightweight Structure-aware Transformer Network for VHR Remote Sensing Image Change Detection
Jun 03, 2023



Popular Transformer networks have been successfully applied to remote sensing (RS) image change detection (CD) identifications and achieve better results than most convolutional neural networks (CNNs), but they still suffer from two main problems. First, the computational complexity of the Transformer grows quadratically with the increase of image spatial resolution, which is unfavorable to very high-resolution (VHR) RS images. Second, these popular Transformer networks tend to ignore the importance of fine-grained features, which results in poor edge integrity and internal tightness for largely changed objects and leads to the loss of small changed objects. To address the above issues, this Letter proposes a Lightweight Structure-aware Transformer (LSAT) network for RS image CD. The proposed LSAT has two advantages. First, a Cross-dimension Interactive Self-attention (CISA) module with linear complexity is designed to replace the vanilla self-attention in visual Transformer, which effectively reduces the computational complexity while improving the feature representation ability of the proposed LSAT. Second, a Structure-aware Enhancement Module (SAEM) is designed to enhance difference features and edge detail information, which can achieve double enhancement by difference refinement and detail aggregation so as to obtain fine-grained features of bi-temporal RS images. Experimental results show that the proposed LSAT achieves significant improvement in detection accuracy and offers a better tradeoff between accuracy and computational costs than most state-of-the-art CD methods for VHR RS images.
Delving into Rectifiers in Style-Based Image Translation
Nov 23, 2021
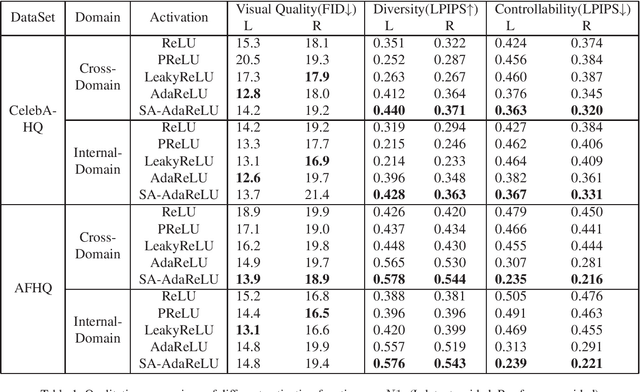
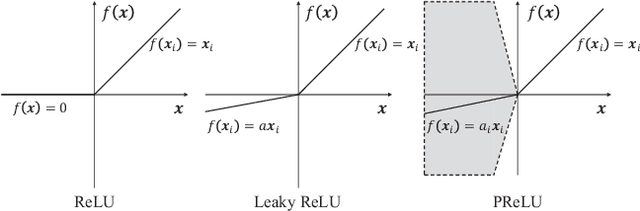
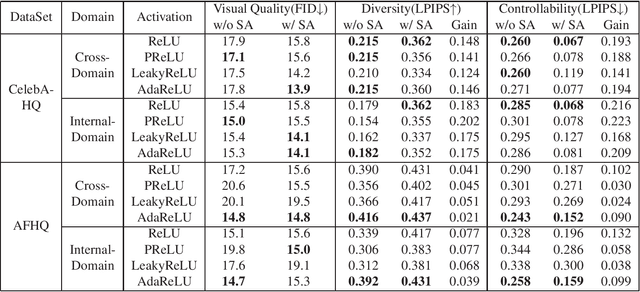
While modern image translation techniques can create photorealistic synthetic images, they have limited style controllability, thus could suffer from translation errors. In this work, we show that the activation function is one of the crucial components in controlling the direction of image synthesis. Specifically, we explicitly demonstrated that the slope parameters of the rectifier could change the data distribution and be used independently to control the direction of translation. To improve the style controllability, two simple but effective techniques are proposed, including Adaptive ReLU (AdaReLU) and structural adaptive function. The AdaReLU can dynamically adjust the slope parameters according to the target style and can be utilized to increase the controllability by combining with Adaptive Instance Normalization (AdaIN). Meanwhile, the structural adaptative function enables rectifiers to manipulate the structure of feature maps more effectively. It is composed of the proposed structural convolution (StruConv), an efficient convolutional module that can choose the area to be activated based on the mean and variance specified by AdaIN. Extensive experiments show that the proposed techniques can greatly increase the network controllability and output diversity in style-based image translation tasks.
Bio-Inspired Audio-Visual Cues Integration for Visual Attention Prediction
Sep 17, 2021

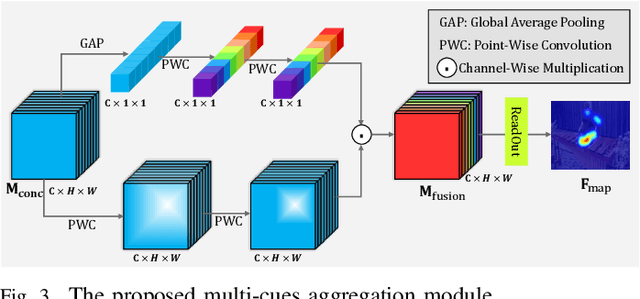
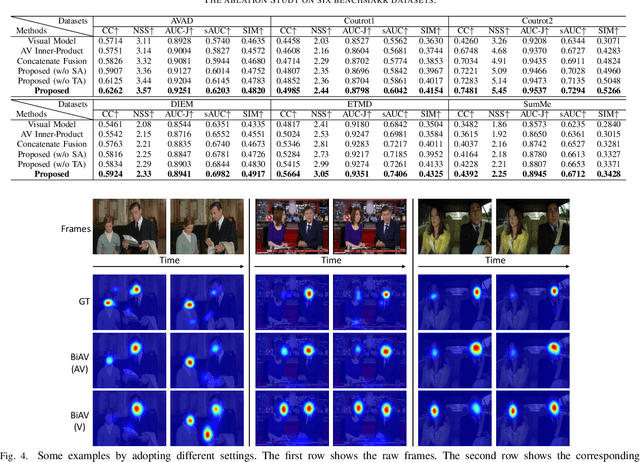
Visual Attention Prediction (VAP) methods simulates the human selective attention mechanism to perceive the scene, which is significant and imperative in many vision tasks. Most existing methods only consider visual cues, while neglect the accompanied audio information, which can provide complementary information for the scene understanding. In fact, there exists a strong relation between auditory and visual cues, and humans generally perceive the surrounding scene by simultaneously sensing these cues. Motivated by this, a bio-inspired audio-visual cues integration method is proposed for the VAP task, which explores the audio modality to better predict the visual attention map by assisting vision modality. The proposed method consists of three parts: 1) audio-visual encoding, 2) audio-visual location, and 3) multi-cues aggregation parts. Firstly, a refined SoundNet architecture is adopted to encode audio modality for obtaining corresponding features, and a modified 3D ResNet-50 architecture is employed to learn visual features, containing both spatial location and temporal motion information. Secondly, an audio-visual location part is devised to locate the sound source in the visual scene by learning the correspondence between audio-visual information. Thirdly, a multi-cues aggregation part is devised to adaptively aggregate audio-visual information and center-bias prior to generate the final visual attention map. Extensive experiments are conducted on six challenging audiovisual eye-tracking datasets, including DIEM, AVAD, Coutrot1, Coutrot2, SumMe, and ETMD, which shows significant superiority over state-of-the-art visual attention models.
Audio Description from Image by Modal Translation Network
Mar 18, 2021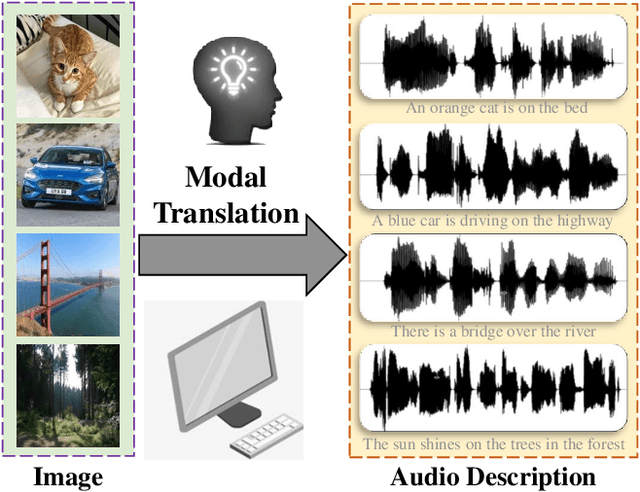
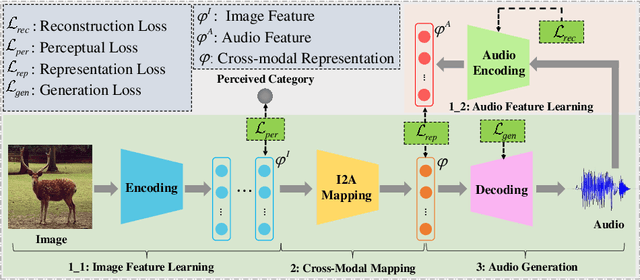

Audio is the main form for the visually impaired to obtain information. In reality, all kinds of visual data always exist, but audio data does not exist in many cases. In order to help the visually impaired people to better perceive the information around them, an image-to-audio-description (I2AD) task is proposed to generate audio descriptions from images in this paper. To complete this totally new task, a modal translation network (MT-Net) from visual to auditory sense is proposed. The proposed MT-Net includes three progressive sub-networks: 1) feature learning, 2) cross-modal mapping, and 3) audio generation. First, the feature learning sub-network aims to learn semantic features from image and audio, including image feature learning and audio feature learning. Second, the cross-modal mapping sub-network transforms the image feature into a cross-modal representation with the same semantic concept as the audio feature. In this way, the correlation of inter-modal data is effectively mined for easing the heterogeneous gap between image and audio. Finally, the audio generation sub-network is designed to generate the audio waveform from the cross-modal representation. The generated audio waveform is interpolated to obtain the corresponding audio file according to the sample frequency. Being the first attempt to explore the I2AD task, three large-scale datasets with plenty of manual audio descriptions are built. Experiments on the datasets verify the feasibility of generating intelligible audio from an image directly and the effectiveness of proposed method.
Bio-Inspired Representation Learning for Visual Attention Prediction
Mar 09, 2021
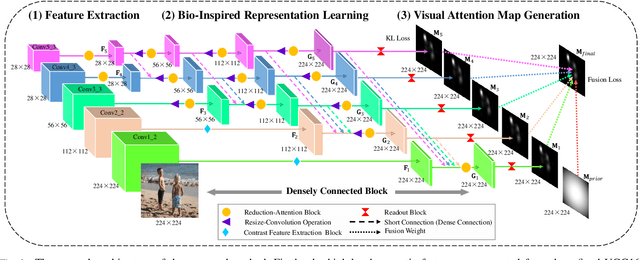
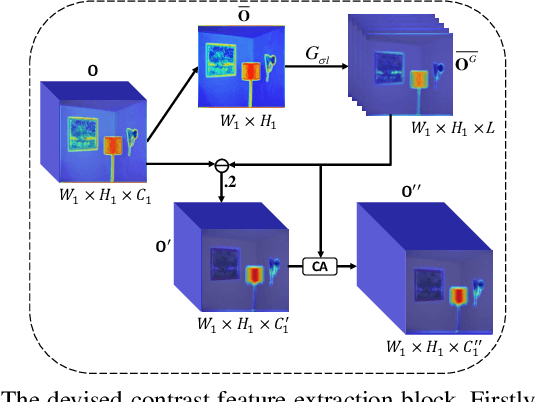
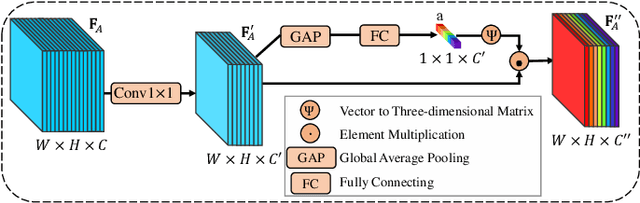
Visual Attention Prediction (VAP) is a significant and imperative issue in the field of computer vision. Most of existing VAP methods are based on deep learning. However, they do not fully take advantage of the low-level contrast features while generating the visual attention map. In this paper, a novel VAP method is proposed to generate visual attention map via bio-inspired representation learning. The bio-inspired representation learning combines both low-level contrast and high-level semantic features simultaneously, which are developed by the fact that human eye is sensitive to the patches with high contrast and objects with high semantics. The proposed method is composed of three main steps: 1) feature extraction, 2) bio-inspired representation learning and 3) visual attention map generation. Firstly, the high-level semantic feature is extracted from the refined VGG16, while the low-level contrast feature is extracted by the proposed contrast feature extraction block in a deep network. Secondly, during bio-inspired representation learning, both the extracted low-level contrast and high-level semantic features are combined by the designed densely connected block, which is proposed to concatenate various features scale by scale. Finally, the weighted-fusion layer is exploited to generate the ultimate visual attention map based on the obtained representations after bio-inspired representation learning. Extensive experiments are performed to demonstrate the effectiveness of the proposed method.