 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-US: An Ultrasound Video Diagnosis Agent Using Video Classification Framework and LLMs
Nov 11, 2025AI-assisted ultrasound video diagnosis presents new opportunities to enhance the efficiency and accuracy of medical imaging analysis. However, existing research remains limited in terms of dataset diversity, diagnostic performance, and clinical applicability. In this study, we propose \textbf{Auto-US}, an intelligent diagnosis agent that integrates ultrasound video data with clinical diagnostic text. To support this, we constructed \textbf{CUV Dataset} of 495 ultrasound videos spanning five categories and three organs, aggregated from multiple open-access sources. We developed \textbf{CTU-Net}, which achieves state-of-the-art performance in ultrasound video classification, reaching an accuracy of 86.73\% Furthermore, by incorporating large language models, Auto-US is capable of generating clinically meaningful diagnostic suggestions. The final diagnostic scores for each case exceeded 3 out of 5 and were validated by professional clinicians. These results demonstrate the effectiveness and clinical potential of Auto-US in real-world ultrasound applications. Code and data are available at: https://github.com/Bean-Young/Auto-US.
Representation Discrepancy Bridging Method for Remote Sensing Image-Text Retrieval
May 22, 2025Remote Sensing Image-Text Retrieval (RSITR) plays a critical role in geographic information interpretation, disaster monitoring, and urban planning by establishing semantic associations between image and textual descriptions. Existing Parameter-Efficient Fine-Tuning (PEFT) methods for Vision-and-Language Pre-training (VLP) models typically adopt symmetric adapter structures for exploring cross-modal correlations. However, the strong discriminative nature of text modality may dominate the optimization process and inhibits image representation learning. The nonnegligible imbalanced cross-modal optimization remains a bottleneck to enhancing the model performance. To address this issue, this study proposes a Representation Discrepancy Bridging (RDB) method for the RSITR task. On the one hand, a Cross-Modal Asymmetric Adapter (CMAA) is designed to enable modality-specific optimization and improve feature alignment. The CMAA comprises a Visual Enhancement Adapter (VEA) and a Text Semantic Adapter (TSA). VEA mines fine-grained image features by Differential Attention (DA) mechanism, while TSA identifies key textual semantics through Hierarchical Attention (HA) mechanism. On the other hand, this study extends the traditional single-task retrieval framework to a dual-task optimization framework and develops a Dual-Task Consistency Loss (DTCL). The DTCL improves cross-modal alignment robustness through an adaptive weighted combination of cross-modal, classification, and exponential moving average consistency constraints. Experiments on RSICD and RSITMD datasets show that the proposed RDB method achieves a 6%-11% improvement in mR metrics compared to state-of-the-art PEFT methods and a 1.15%-2% improvement over the full fine-tuned GeoRSCLIP model.
Optimistic ε-Greedy Exploration for Cooperative Multi-Agent Reinforcement Learning
Feb 05, 2025The Centralized Training with Decentralized Execution (CTDE) paradigm is widely used in cooperative multi-agent reinforcement learning. However, due to the representational limitations of traditional monotonic value decomposition methods, algorithms can underestimate optimal actions, leading policies to suboptimal solutions. To address this challenge, we propose Optimistic $\epsilon$-Greedy Exploration, focusing on enhancing exploration to correct value estimations. The underestimation arises from insufficient sampling of optimal actions during exploration, as our analysis indicated. We introduce an optimistic updating network to identify optimal actions and sample actions from its distribution with a probability of $\epsilon$ during exploration, increasing the selection frequency of optimal actions. Experimental results in various environments reveal that the Optimistic $\epsilon$-Greedy Exploration effectively prevents the algorithm from suboptimal solutions and significantly improves its performance compared to other algorithms.
Double Distillation Network for Multi-Agent Reinforcement Learning
Feb 05, 2025



Multi-agent reinforcement learning typically employs a centralized training-decentralized execution (CTDE) framework to alleviate the non-stationarity in environment. However, the partial observability during execution may lead to cumulative gap errors gathered by agents, impairing the training of effective collaborative policies. To overcome this challenge, we introduce the Double Distillation Network (DDN), which incorporates two distillation modules aimed at enhancing robust coordination and facilitating the collaboration process under constrained information. The external distillation module uses a global guiding network and a local policy network, employing distillation to reconcile the gap between global training and local execution. In addition, the internal distillation module introduces intrinsic rewards, drawn from state information, to enhance the exploration capabilities of agents. Extensive experiments demonstrate that DDN significantly improves performance across multiple scenarios.
Multiple Partitions Aligned Clustering
Sep 13, 2019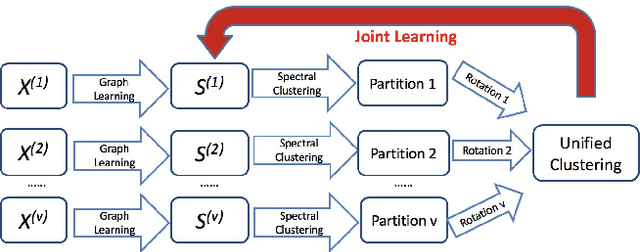

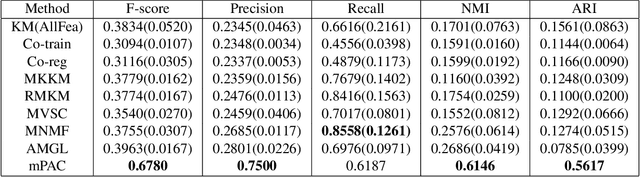
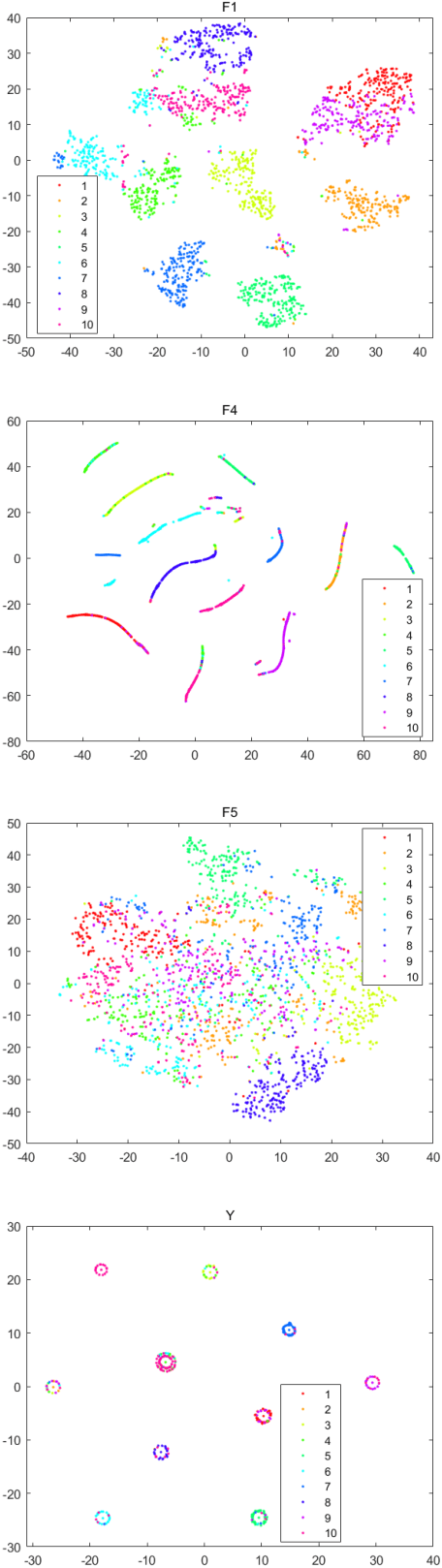
Multi-view clustering is an important yet challenging task due to the difficulty of integrating the information from multiple representations. Most existing multi-view clustering methods explore the heterogeneous information in the space where the data points lie. Such common practice may cause significant information loss because of unavoidable noise or inconsistency among views. Since different views admit the same cluster structure, the natural space should be all partitions. Orthogonal to existing techniques, in this paper, we propose to leverage the multi-view information by fusing partitions. Specifically, we align each partition to form a consensus cluster indicator matrix through a distinct rotation matrix. Moreover, a weight is assigned for each view to account for the clustering capacity differences of views. Finally, the basic partitions, weights, and consensus clustering are jointly learned in a unified framework. We demonstrate the effectiveness of our approach on several real datasets, where significant improvement is found over other state-of-the-art multi-view clustering methods.