 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUM-Text: A Unified Multimodal Model for Image Understanding
Jan 13, 2026With the rapid advancement of image generation, visual text editing using natural language instructions has received increasing attention. The main challenge of this task is to fully understand the instruction and reference image, and thus generate visual text that is style-consistent with the image. Previous methods often involve complex steps of specifying the text content and attributes, such as font size, color, and layout, without considering the stylistic consistency with the reference image. To address this, we propose UM-Text, a unified multimodal model for context understanding and visual text editing by natural language instructions. Specifically, we introduce a Visual Language Model (VLM) to process the instruction and reference image, so that the text content and layout can be elaborately designed according to the context information. To generate an accurate and harmonious visual text image, we further propose the UM-Encoder to combine the embeddings of various condition information, where the combination is automatically configured by VLM according to the input instruction. During training, we propose a regional consistency loss to offer more effective supervision for glyph generation on both latent and RGB space, and design a tailored three-stage training strategy to further enhance model performance. In addition, we contribute the UM-DATA-200K, a large-scale visual text image dataset on diverse scenes for model training. Extensive qualitative and quantitative results on multiple public benchmarks demonstrate that our method achieves state-of-the-art performance.
RePainter: Empowering E-commerce Object Removal via Spatial-matting Reinforcement Learning
Oct 09, 2025In web data, product images are central to boosting user engagement and advertising efficacy on e-commerce platforms, yet the intrusive elements such as watermarks and promotional text remain major obstacles to delivering clear and appealing product visuals. Although diffusion-based inpainting methods have advanced, they still face challenges in commercial settings due to unreliable object removal and limited domain-specific adaptation. To tackle these challenges, we propose Repainter, a reinforcement learning framework that integrates spatial-matting trajectory refinement with Group Relative Policy Optimization (GRPO). Our approach modulates attention mechanisms to emphasize background context, generating higher-reward samples and reducing unwanted object insertion. We also introduce a composite reward mechanism that balances global, local, and semantic constraints, effectively reducing visual artifacts and reward hacking. Additionally, we contribute EcomPaint-100K, a high-quality, large-scale e-commerce inpainting dataset, and a standardized benchmark EcomPaint-Bench for fair evaluation. Extensive experiments demonstrate that Repainter significantly outperforms state-of-the-art methods, especially in challenging scenes with intricate compositions. We will release our code and weights upon acceptance.
Multiple Partitions Aligned Clustering
Sep 13, 2019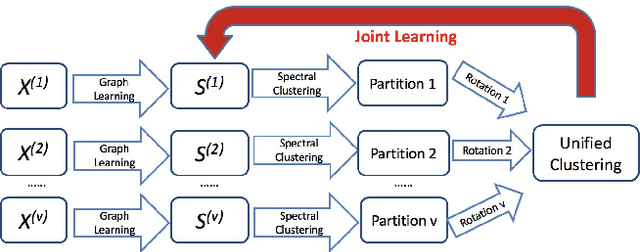

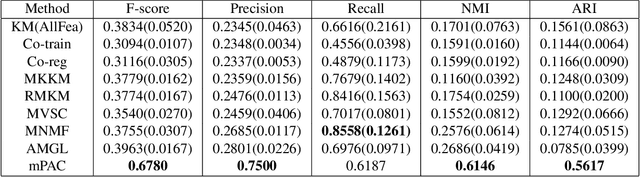
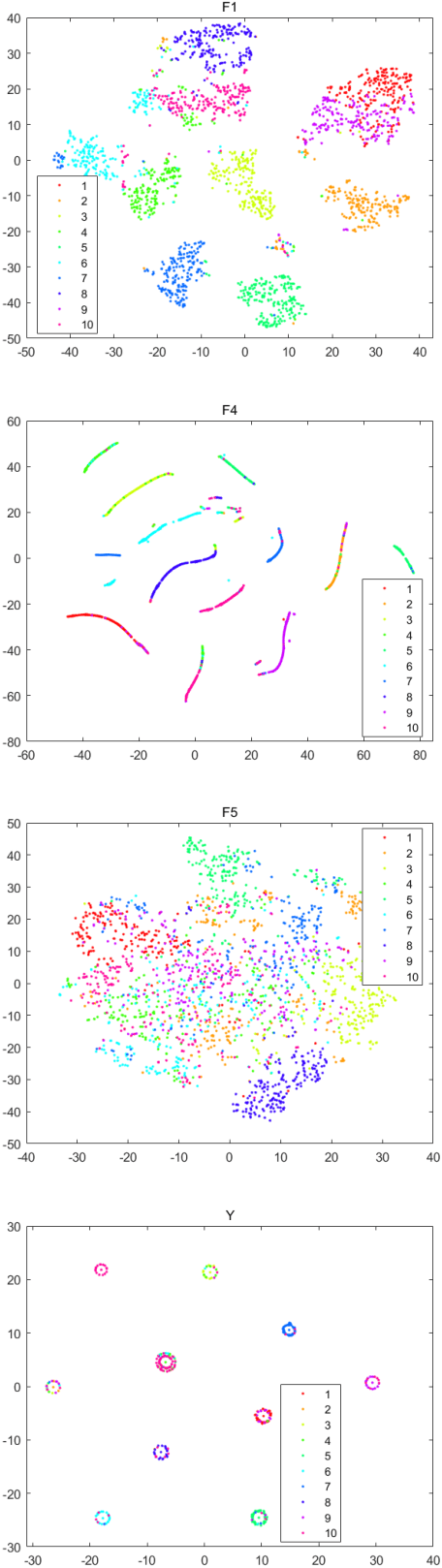
Multi-view clustering is an important yet challenging task due to the difficulty of integrating the information from multiple representations. Most existing multi-view clustering methods explore the heterogeneous information in the space where the data points lie. Such common practice may cause significant information loss because of unavoidable noise or inconsistency among views. Since different views admit the same cluster structure, the natural space should be all partitions. Orthogonal to existing techniques, in this paper, we propose to leverage the multi-view information by fusing partitions. Specifically, we align each partition to form a consensus cluster indicator matrix through a distinct rotation matrix. Moreover, a weight is assigned for each view to account for the clustering capacity differences of views. Finally, the basic partitions, weights, and consensus clustering are jointly learned in a unified framework. We demonstrate the effectiveness of our approach on several real datasets, where significant improvement is found over other state-of-the-art multi-view clustering methods.