 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Post-GCN Decade Revisited: Curvature-Stratified Evaluation of Relational Learning
Jun 04, 2026Current evaluation practices in relational learning rely heavily on flat leaderboards that average performance across heterogeneous datasets, implicitly assuming a uniform underlying structure. We show that this assumption introduces systematic bias: it obscures geometry-dependent performance variations and can lead to misleading conclusions about model generalization. In this work, we identify intrinsic geometry as a key latent factor governing model effectiveness. We demonstrate that conventional aggregated metrics mask critical performance trade-offs that only become visible when datasets are stratified by their geometric properties. To address this issue, we introduce a curvature-stratified evaluation framework that partitions datasets into positive, negative, and near-zero curvature regimes. Our benchmark evaluates 18 representative models including Graph Convolutional Networks (GCNs), Graph Foundation Models (GFMs), and tabular learning methods across 14 datasets. We find that model rankings are highly stable within each curvature regime but shift significantly across regimes, indicating that performance is fundamentally geometry-dependent rather than universally transferable. Notably, we identify regimes where GFMs offer diminishing returns compared to geometry-aligned GNNs. Based on these findings, we propose a geometry-aware evaluation protocol that yields more reliable and interpretable comparisons than standard aggregated benchmarks. We release all code, curvature-stratified dataset splits, and evaluation tools to support reproducible and rigorous assessment of future relational learning methods. Code and datasets are provided in our project homepage: https://sirbabbage.github.io/CurvBench_HOME/.
Rethinking Incompleteness: Formalizing Protocol Divergence and Train-Once Learning for Robust IMVC
Jun 03, 2026Standard IMVC evaluation retrains separate models for different missing-data configurations. We show that this paradigm obscures a fundamental vulnerability: missing rate alone is insufficient to characterize data incompleteness. Specifically, we show that protocols with identical nominal missing rates can differ by up to $50\times$ in their proportion of fully observed samples, inducing drastically different learning regimes. We formalize this phenomenon as incompleteness divergence, providing measures that capture structural disparities across missing-data protocols. We further prove that for a broad class of reconstruction-based objectives, learning becomes structurally ill-posed when the proportion of complete samples falls below a critical threshold, leading to near-random performance. To bypass this theoretical bound, we propose CRAFT (Complete-data Robust Attention-masked Fusion Transformer). CRAFT shifts the burden of robustness from the loss function to the architecture via two key properties: (i) per-sample independence, which removes reliance on complete-sample co-occurrence, and (ii) mask-aware variable-length fusion, which aggregates only observed views through attention masking. This design allows a single model, trained once on complete data, to generalize to diverse missing patterns at inference time without retraining. Extensive experiments on seven benchmarks show that CRAFT matches or outperforms per-configuration baselines while reducing training overhead by $8.8\times$, demonstrating that robustness to missing data can be achieved as an inherent architectural property. Code (CRAFT) and our imvc-audit toolkit are available at https://anonymous.4open.science/r/CRAFT-BF80/ and https://anonymous.4open.science/r/imvc-audit-8263/.
Clustering as Reasoning: A $k$-Means Interpretation of Chain-of-Thought Graph Learning
May 24, 2026Chain-of-Thought (CoT) prompting has shown promise in enhancing the reasoning capabilities of large language models (LLMs) on text-attributed graphs (TAGs). This work reframes CoT-based graph learning through the principle of clustering as reasoning, offering a $k$-means interpretation of how iterative reasoning operates over graph-structured data. We observe that existing graph CoT methods rely on disjoint architectures and fixed graph representations, limiting step-by-step semantic-topological interaction and interpretability. To overcome this limitation, we propose a unified framework named KCoT that integrates CoT reasoning with graph representation learning. Our key theoretical result reveals a formal mathematical correspondence between a Transformer block and the $k$-means algorithm, allowing reasoning to be interpreted as iterative assignment and update steps. Based on this insight, we introduce a Semantic Discriminating Prompt that explicitly formulates these steps as structured CoT reasoning, together with a structure-grounded alignment strategy to fuse topological priors with evolving thought-conditioned representations. Experiments on standard benchmarks demonstrate consistent improvements over state-of-the-art methods, validating clustering as a principled mechanism for CoT-based graph learning.
Extracting Events Like Code: A Multi-Agent Programming Framework for Zero-Shot Event Extraction
Nov 17, 2025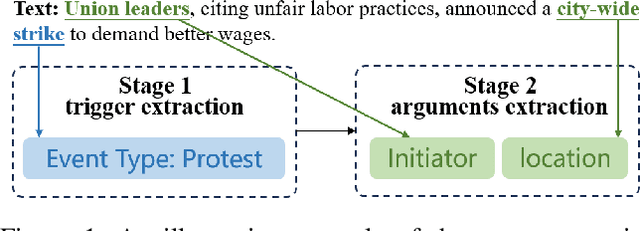
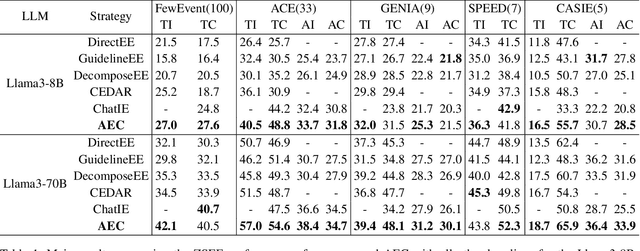
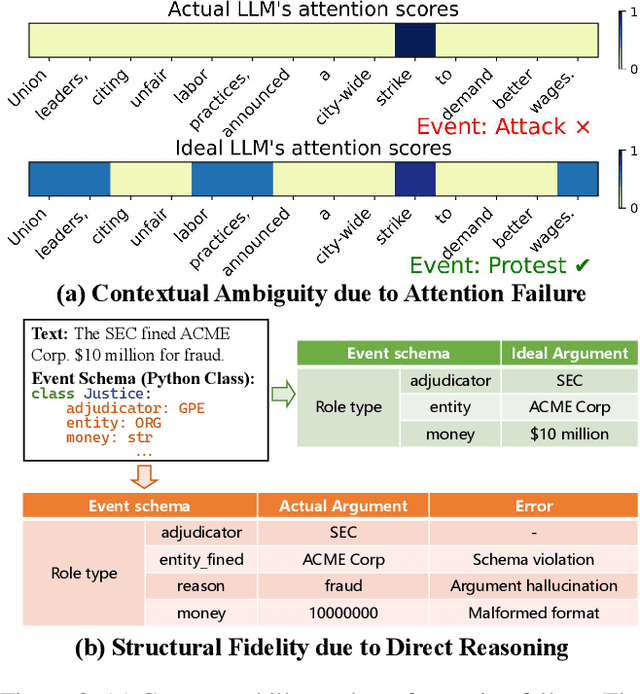
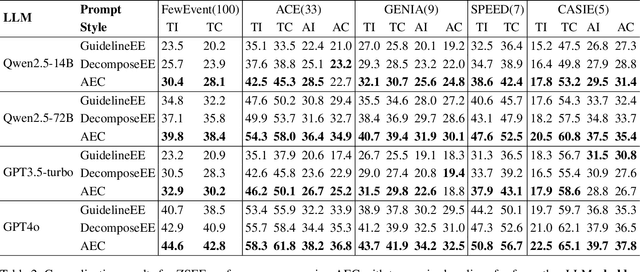
Zero-shot event extraction (ZSEE) remains a significant challenge for large language models (LLMs) due to the need for complex reasoning and domain-specific understanding. Direct prompting often yields incomplete or structurally invalid outputs--such as misclassified triggers, missing arguments, and schema violations. To address these limitations, we present Agent-Event-Coder (AEC), a novel multi-agent framework that treats event extraction like software engineering: as a structured, iterative code-generation process. AEC decomposes ZSEE into specialized subtasks--retrieval, planning, coding, and verification--each handled by a dedicated LLM agent. Event schemas are represented as executable class definitions, enabling deterministic validation and precise feedback via a verification agent. This programming-inspired approach allows for systematic disambiguation and schema enforcement through iterative refinement. By leveraging collaborative agent workflows, AEC enables LLMs to produce precise, complete, and schema-consistent extractions in zero-shot settings. Experiments across five diverse domains and six LLMs demonstrate that AEC consistently outperforms prior zero-shot baselines, showcasing the power of treating event extraction like code generation. The code and data are released on https://github.com/UESTC-GQJ/Agent-Event-Coder.
ITPP: Learning Disentangled Event Dynamics in Marked Temporal Point Processes
Nov 08, 2025Marked Temporal Point Processes (MTPPs) provide a principled framework for modeling asynchronous event sequences by conditioning on the history of past events. However, most existing MTPP models rely on channel-mixing strategies that encode information from different event types into a single, fixed-size latent representation. This entanglement can obscure type-specific dynamics, leading to performance degradation and increased risk of overfitting. In this work, we introduce ITPP, a novel channel-independent architecture for MTPP modeling that decouples event type information using an encoder-decoder framework with an ODE-based backbone. Central to ITPP is a type-aware inverted self-attention mechanism, designed to explicitly model inter-channel correlations among heterogeneous event types. This architecture enhances effectiveness and robustness while reducing overfitting. Comprehensive experiments on multiple real-world and synthetic datasets demonstrate that ITPP consistently outperforms state-of-the-art MTPP models in both predictive accuracy and generalization.
Attention Beyond Neighborhoods: Reviving Transformer for Graph Clustering
Sep 18, 2025



Attention mechanisms have become a cornerstone in modern neural networks, driving breakthroughs across diverse domains. However, their application to graph structured data, where capturing topological connections is essential, remains underexplored and underperforming compared to Graph Neural Networks (GNNs), particularly in the graph clustering task. GNN tends to overemphasize neighborhood aggregation, leading to a homogenization of node representations. Conversely, Transformer tends to over globalize, highlighting distant nodes at the expense of meaningful local patterns. This dichotomy raises a key question: Is attention inherently redundant for unsupervised graph learning? To address this, we conduct a comprehensive empirical analysis, uncovering the complementary weaknesses of GNN and Transformer in graph clustering. Motivated by these insights, we propose the Attentive Graph Clustering Network (AGCN) a novel architecture that reinterprets the notion that graph is attention. AGCN directly embeds the attention mechanism into the graph structure, enabling effective global information extraction while maintaining sensitivity to local topological cues. Our framework incorporates theoretical analysis to contrast AGCN behavior with GNN and Transformer and introduces two innovations: (1) a KV cache mechanism to improve computational efficiency, and (2) a pairwise margin contrastive loss to boost the discriminative capacity of the attention space. Extensive experimental results demonstrate that AGCN outperforms state-of-the-art methods.
Aggregation-aware MLP: An Unsupervised Approach for Graph Message-passing
Jul 27, 2025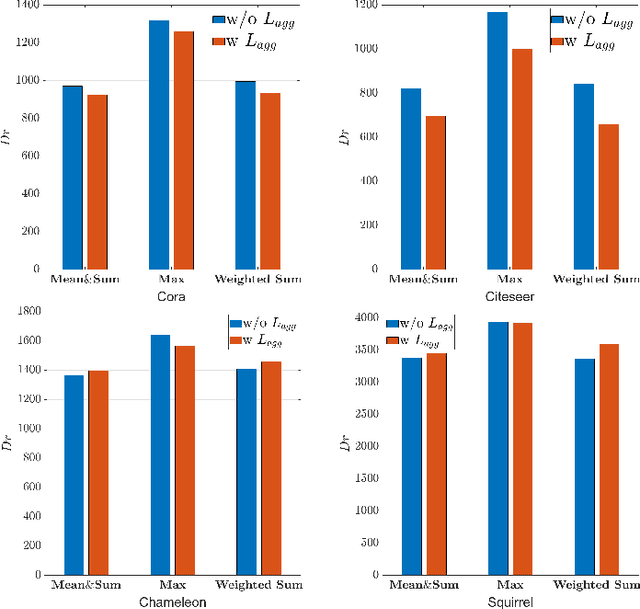

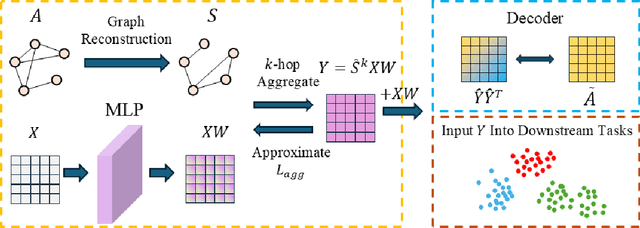
Graph Neural Networks (GNNs) have become a dominant approach to learning graph representations, primarily because of their message-passing mechanisms. However, GNNs typically adopt a fixed aggregator function such as Mean, Max, or Sum without principled reasoning behind the selection. This rigidity, especially in the presence of heterophily, often leads to poor, problem dependent performance. Although some attempts address this by designing more sophisticated aggregation functions, these methods tend to rely heavily on labeled data, which is often scarce in real-world tasks. In this work, we propose a novel unsupervised framework, "Aggregation-aware Multilayer Perceptron" (AMLP), which shifts the paradigm from directly crafting aggregation functions to making MLP adaptive to aggregation. Our lightweight approach consists of two key steps: First, we utilize a graph reconstruction method that facilitates high-order grouping effects, and second, we employ a single-layer network to encode varying degrees of heterophily, thereby improving the capacity and applicability of the model. Extensive experiments on node clustering and classification demonstrate the superior performance of AMLP, highlighting its potential for diverse graph learning scenarios.
Cooperation of Experts: Fusing Heterogeneous Information with Large Margin
May 28, 2025Fusing heterogeneous information remains a persistent challenge in modern data analysis. While significant progress has been made, existing approaches often fail to account for the inherent heterogeneity of object patterns across different semantic spaces. To address this limitation, we propose the Cooperation of Experts (CoE) framework, which encodes multi-typed information into unified heterogeneous multiplex networks. By overcoming modality and connection differences, CoE provides a powerful and flexible model for capturing the intricate structures of real-world complex data. In our framework, dedicated encoders act as domain-specific experts, each specializing in learning distinct relational patterns in specific semantic spaces. To enhance robustness and extract complementary knowledge, these experts collaborate through a novel large margin mechanism supported by a tailored optimization strategy. Rigorous theoretical analyses guarantee the framework's feasibility and stability, while extensive experiments across diverse benchmarks demonstrate its superior performance and broad applicability. Our code is available at https://github.com/strangeAlan/CoE.
Bridging Generative and Discriminative Learning: Few-Shot Relation Extraction via Two-Stage Knowledge-Guided Pre-training
May 18, 2025



Few-Shot Relation Extraction (FSRE) remains a challenging task due to the scarcity of annotated data and the limited generalization capabilities of existing models. Although large language models (LLMs) have demonstrated potential in FSRE through in-context learning (ICL), their general-purpose training objectives often result in suboptimal performance for task-specific relation extraction. To overcome these challenges, we propose TKRE (Two-Stage Knowledge-Guided Pre-training for Relation Extraction), a novel framework that synergistically integrates LLMs with traditional relation extraction models, bridging generative and discriminative learning paradigms. TKRE introduces two key innovations: (1) leveraging LLMs to generate explanation-driven knowledge and schema-constrained synthetic data, addressing the issue of data scarcity; and (2) a two-stage pre-training strategy combining Masked Span Language Modeling (MSLM) and Span-Level Contrastive Learning (SCL) to enhance relational reasoning and generalization. Together, these components enable TKRE to effectively tackle FSRE tasks. Comprehensive experiments on benchmark datasets demonstrate the efficacy of TKRE, achieving new state-of-the-art performance in FSRE and underscoring its potential for broader application in low-resource scenarios. \footnote{The code and data are released on https://github.com/UESTC-GQJ/TKRE.
Multi-Domain Graph Foundation Models: Robust Knowledge Transfer via Topology Alignment
Feb 04, 2025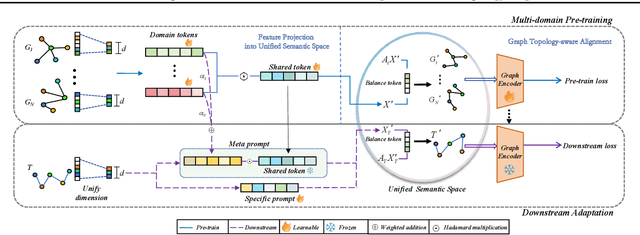
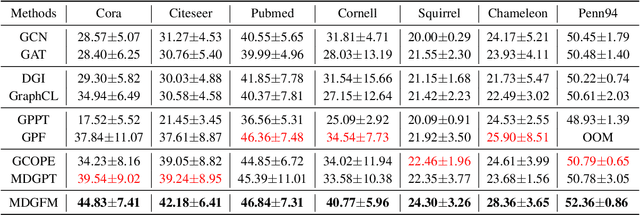
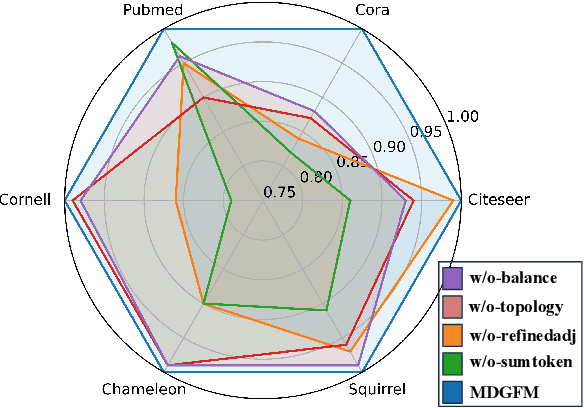
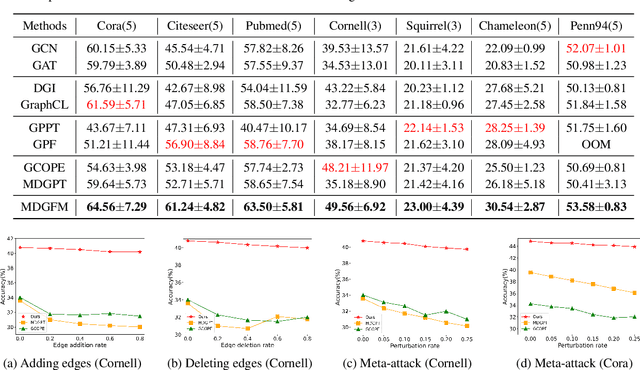
Recent advances in CV and NLP have inspired researchers to develop general-purpose graph foundation models through pre-training across diverse domains. However, a fundamental challenge arises from the substantial differences in graph topologies across domains. Additionally, real-world graphs are often sparse and prone to noisy connections and adversarial attacks. To address these issues, we propose the Multi-Domain Graph Foundation Model (MDGFM), a unified framework that aligns and leverages cross-domain topological information to facilitate robust knowledge transfer. MDGFM bridges different domains by adaptively balancing features and topology while refining original graphs to eliminate noise and align topological structures. To further enhance knowledge transfer, we introduce an efficient prompt-tuning approach. By aligning topologies, MDGFM not only improves multi-domain pre-training but also enables robust knowledge transfer to unseen domains. Theoretical analyses provide guarantees of MDGFM's effectiveness and domain generalization capabilities. Extensive experiments on both homophilic and heterophilic graph datasets validate the robustness and efficacy of our method.