 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Events Like Code: A Multi-Agent Programming Framework for Zero-Shot Event Extraction
Nov 17, 2025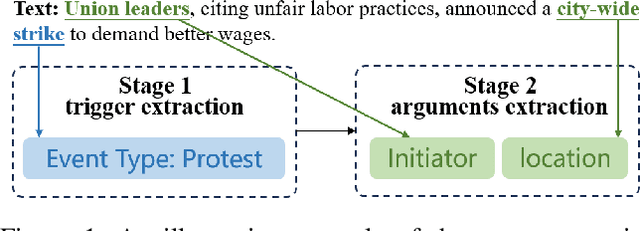
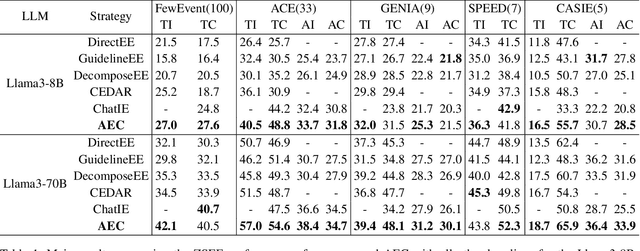
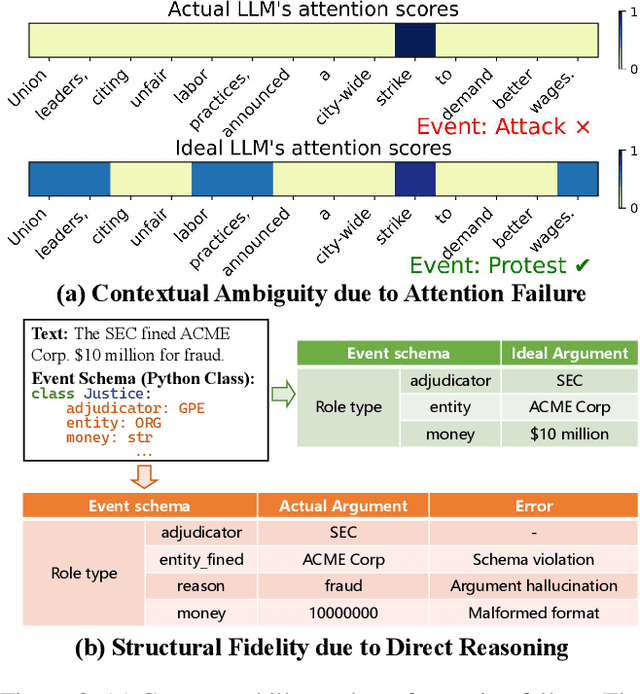
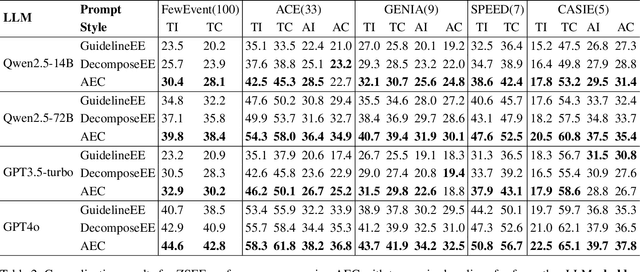
Zero-shot event extraction (ZSEE) remains a significant challenge for large language models (LLMs) due to the need for complex reasoning and domain-specific understanding. Direct prompting often yields incomplete or structurally invalid outputs--such as misclassified triggers, missing arguments, and schema violations. To address these limitations, we present Agent-Event-Coder (AEC), a novel multi-agent framework that treats event extraction like software engineering: as a structured, iterative code-generation process. AEC decomposes ZSEE into specialized subtasks--retrieval, planning, coding, and verification--each handled by a dedicated LLM agent. Event schemas are represented as executable class definitions, enabling deterministic validation and precise feedback via a verification agent. This programming-inspired approach allows for systematic disambiguation and schema enforcement through iterative refinement. By leveraging collaborative agent workflows, AEC enables LLMs to produce precise, complete, and schema-consistent extractions in zero-shot settings. Experiments across five diverse domains and six LLMs demonstrate that AEC consistently outperforms prior zero-shot baselines, showcasing the power of treating event extraction like code generation. The code and data are released on https://github.com/UESTC-GQJ/Agent-Event-Coder.
PipeDiT: Accelerating Diffusion Transformers in Video Generation with Task Pipelining and Model Decoupling
Nov 15, 2025Video generation has been advancing rapidly, and diffusion transformer (DiT) based models have demonstrated remark- able capabilities. However, their practical deployment is of- ten hindered by slow inference speeds and high memory con- sumption. In this paper, we propose a novel pipelining frame- work named PipeDiT to accelerate video generation, which is equipped with three main innovations. First, we design a pipelining algorithm (PipeSP) for sequence parallelism (SP) to enable the computation of latent generation and commu- nication among multiple GPUs to be pipelined, thus reduc- ing inference latency. Second, we propose DeDiVAE to de- couple the diffusion module and the variational autoencoder (VAE) module into two GPU groups, whose executions can also be pipelined to reduce memory consumption and infer- ence latency. Third, to better utilize the GPU resources in the VAE group, we propose an attention co-processing (Aco) method to further reduce the overall video generation latency. We integrate our PipeDiT into both OpenSoraPlan and Hun- yuanVideo, two state-of-the-art open-source video generation frameworks, and conduct extensive experiments on two 8- GPU systems. Experimental results show that, under many common resolution and timestep configurations, our PipeDiT achieves 1.06x to 4.02x speedups over OpenSoraPlan and HunyuanVideo.
CodeBoost: Boosting Code LLMs by Squeezing Knowledge from Code Snippets with RL
Aug 07, 2025Code large language models (LLMs) have become indispensable tools for building efficient and automated coding pipelines. Existing models are typically post-trained using reinforcement learning (RL) from general-purpose LLMs using "human instruction-final answer" pairs, where the instructions are usually from manual annotations. However, collecting high-quality coding instructions is both labor-intensive and difficult to scale. On the other hand, code snippets are abundantly available from various sources. This imbalance presents a major bottleneck in instruction-based post-training. We propose CodeBoost, a post-training framework that enhances code LLMs purely from code snippets, without relying on human-annotated instructions. CodeBoost introduces the following key components: (1) maximum-clique curation, which selects a representative and diverse training corpus from code; (2) bi-directional prediction, which enables the model to learn from both forward and backward prediction objectives; (3) error-aware prediction, which incorporates learning signals from both correct and incorrect outputs; (4) heterogeneous augmentation, which diversifies the training distribution to enrich code semantics; and (5) heterogeneous rewarding, which guides model learning through multiple reward types including format correctness and execution feedback from both successes and failures. Extensive experiments across several code LLMs and benchmarks verify that CodeBoost consistently improves performance, demonstrating its effectiveness as a scalable and effective training pipeline.
UAVScenes: A Multi-Modal Dataset for UAVs
Jul 30, 2025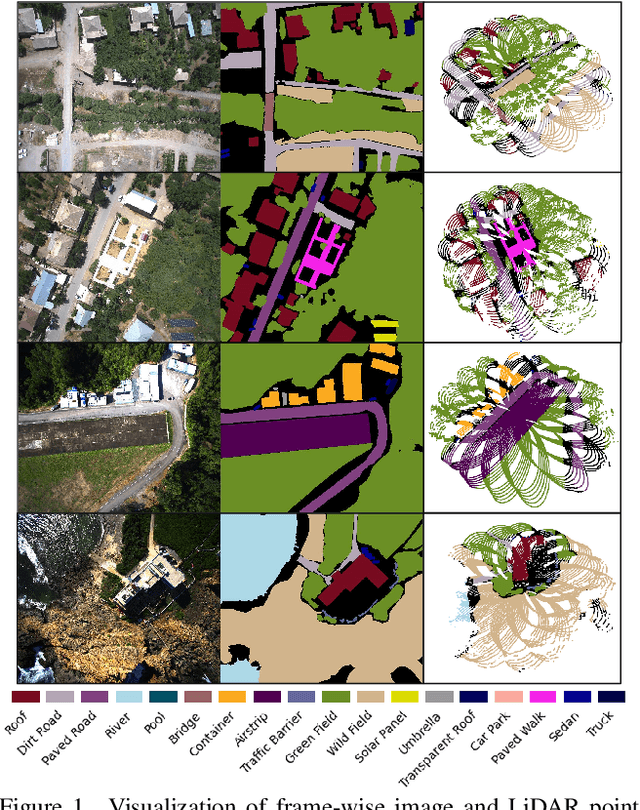
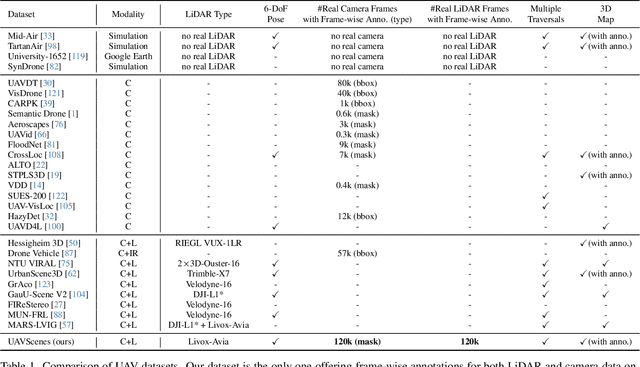
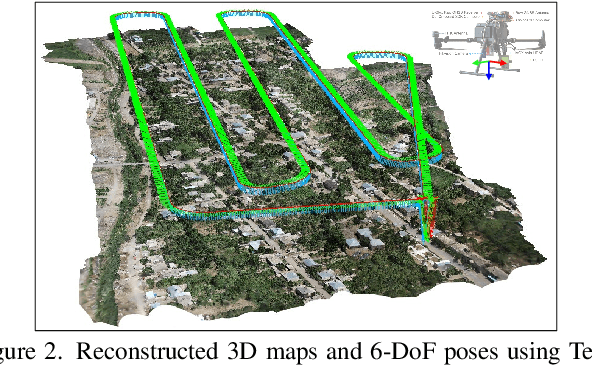
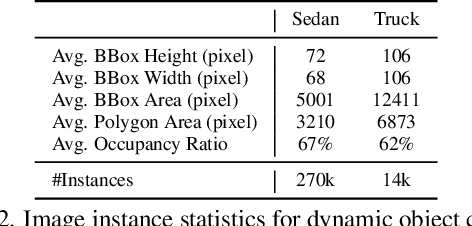
Multi-modal perception is essential for unmanned aerial vehicle (UAV) operations, as it enables a comprehensive understanding of the UAVs' surrounding environment. However, most existing multi-modal UAV datasets are primarily biased toward localization and 3D reconstruction tasks, or only support map-level semantic segmentation due to the lack of frame-wise annotations for both camera images and LiDAR point clouds. This limitation prevents them from being used for high-level scene understanding tasks. To address this gap and advance multi-modal UAV perception, we introduce UAVScenes, a large-scale dataset designed to benchmark various tasks across both 2D and 3D modalities. Our benchmark dataset is built upon the well-calibrated multi-modal UAV dataset MARS-LVIG, originally developed only for simultaneous localization and mapping (SLAM). We enhance this dataset by providing manually labeled semantic annotations for both frame-wise images and LiDAR point clouds, along with accurate 6-degree-of-freedom (6-DoF) poses. These additions enable a wide range of UAV perception tasks, including segmentation, depth estimation, 6-DoF localization, place recognition, and novel view synthesis (NVS). Our dataset is available at https://github.com/sijieaaa/UAVScenes
Bridging Generative and Discriminative Learning: Few-Shot Relation Extraction via Two-Stage Knowledge-Guided Pre-training
May 18, 2025



Few-Shot Relation Extraction (FSRE) remains a challenging task due to the scarcity of annotated data and the limited generalization capabilities of existing models. Although large language models (LLMs) have demonstrated potential in FSRE through in-context learning (ICL), their general-purpose training objectives often result in suboptimal performance for task-specific relation extraction. To overcome these challenges, we propose TKRE (Two-Stage Knowledge-Guided Pre-training for Relation Extraction), a novel framework that synergistically integrates LLMs with traditional relation extraction models, bridging generative and discriminative learning paradigms. TKRE introduces two key innovations: (1) leveraging LLMs to generate explanation-driven knowledge and schema-constrained synthetic data, addressing the issue of data scarcity; and (2) a two-stage pre-training strategy combining Masked Span Language Modeling (MSLM) and Span-Level Contrastive Learning (SCL) to enhance relational reasoning and generalization. Together, these components enable TKRE to effectively tackle FSRE tasks. Comprehensive experiments on benchmark datasets demonstrate the efficacy of TKRE, achieving new state-of-the-art performance in FSRE and underscoring its potential for broader application in low-resource scenarios. \footnote{The code and data are released on https://github.com/UESTC-GQJ/TKRE.
BANER: Boundary-Aware LLMs for Few-Shot Named Entity Recognition
Dec 03, 2024



Despite the recent success of two-stage prototypical networks in few-shot named entity recognition (NER), challenges such as over/under-detected false spans in the span detection stage and unaligned entity prototypes in the type classification stage persist. Additionally, LLMs have not proven to be effective few-shot information extractors in general. In this paper, we propose an approach called Boundary-Aware LLMs for Few-Shot Named Entity Recognition to address these issues. We introduce a boundary-aware contrastive learning strategy to enhance the LLM's ability to perceive entity boundaries for generalized entity spans. Additionally, we utilize LoRAHub to align information from the target domain to the source domain, thereby enhancing adaptive cross-domain classification capabilities. Extensive experiments across various benchmarks demonstrate that our framework outperforms prior methods, validating its effectiveness. In particular, the proposed strategies demonstrate effectiveness across a range of LLM architectures. The code and data are released on https://github.com/UESTC-GQJ/BANER.
PRFusion: Toward Effective and Robust Multi-Modal Place Recognition with Image and Point Cloud Fusion
Oct 07, 2024Place recognition plays a crucial role in the fields of robotics and computer vision, finding applications in areas such as autonomous driving, mapping, and localization. Place recognition identifies a place using query sensor data and a known database. One of the main challenges is to develop a model that can deliver accurate results while being robust to environmental variations. We propose two multi-modal place recognition models, namely PRFusion and PRFusion++. PRFusion utilizes global fusion with manifold metric attention, enabling effective interaction between features without requiring camera-LiDAR extrinsic calibrations. In contrast, PRFusion++ assumes the availability of extrinsic calibrations and leverages pixel-point correspondences to enhance feature learning on local windows. Additionally, both models incorporate neural diffusion layers, which enable reliable operation even in challenging environments. We verify the state-of-the-art performance of both models on three large-scale benchmarks. Notably, they outperform existing models by a substantial margin of +3.0 AR@1 on the demanding Boreas dataset. Furthermore, we conduct ablation studies to validate the effectiveness of our proposed methods. The codes are available at: https://github.com/sijieaaa/PRFusion
DropEdge not Foolproof: Effective Augmentation Method for Signed Graph Neural Networks
Sep 29, 2024



The paper discusses signed graphs, which model friendly or antagonistic relationships using edges marked with positive or negative signs, focusing on the task of link sign prediction. While Signed Graph Neural Networks (SGNNs) have advanced, they face challenges like graph sparsity and unbalanced triangles. The authors propose using data augmentation (DA) techniques to address these issues, although many existing methods are not suitable for signed graphs due to a lack of side information. They highlight that the random DropEdge method, a rare DA approach applicable to signed graphs, does not enhance link sign prediction performance. In response, they introduce the Signed Graph Augmentation (SGA) framework, which includes a structure augmentation module to identify candidate edges and a strategy for selecting beneficial candidates, ultimately improving SGNN training. Experimental results show that SGA significantly boosts the performance of SGNN models, with a notable 32.3% improvement in F1-micro for SGCN on the Slashdot dataset.
PointDifformer: Robust Point Cloud Registration With Neural Diffusion and Transformer
Apr 22, 2024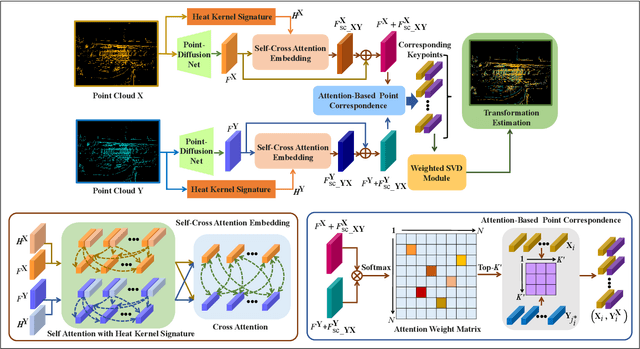
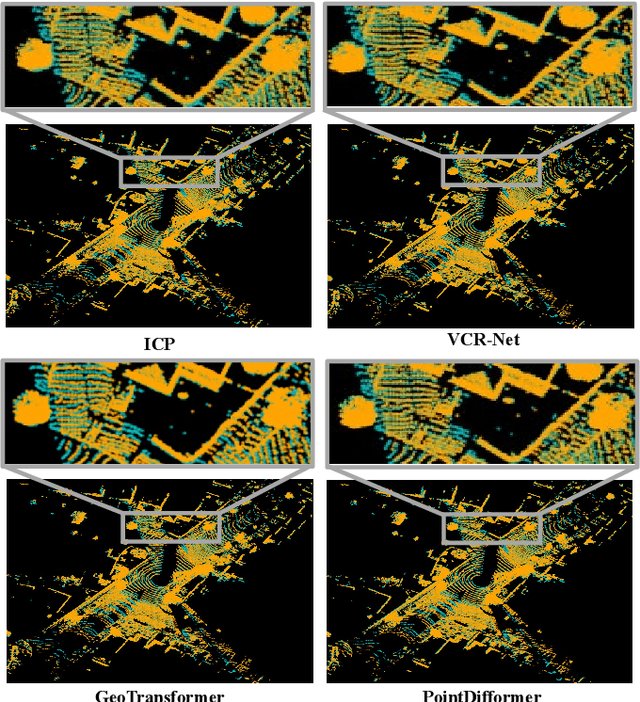
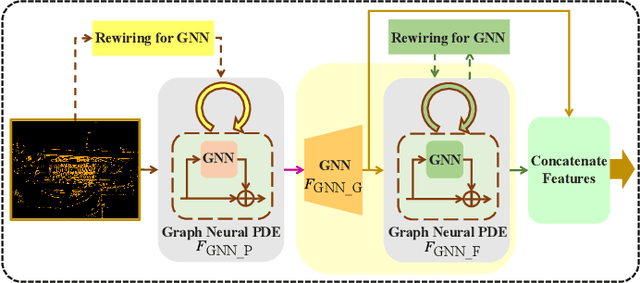
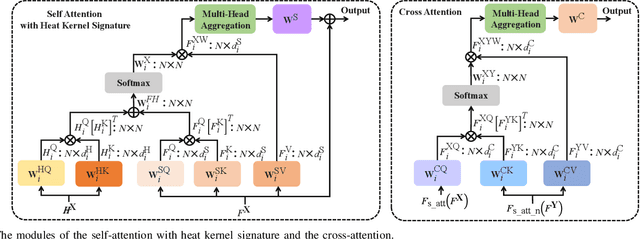
Point cloud registration is a fundamental technique in 3-D computer vision with applications in graphics, autonomous driving, and robotics. However, registration tasks under challenging conditions, under which noise or perturbations are prevalent, can be difficult. We propose a robust point cloud registration approach that leverages graph neural partial differential equations (PDEs) and heat kernel signatures. Our method first uses graph neural PDE modules to extract high dimensional features from point clouds by aggregating information from the 3-D point neighborhood, thereby enhancing the robustness of the feature representations. Then, we incorporate heat kernel signatures into an attention mechanism to efficiently obtain corresponding keypoints. Finally, a singular value decomposition (SVD) module with learnable weights is used to predict the transformation between two point clouds. Empirical experiments on a 3-D point cloud dataset demonstrate that our approach not only achieves state-of-the-art performance for point cloud registration but also exhibits better robustness to additive noise or 3-D shape perturbations.
Coupling Graph Neural Networks with Fractional Order Continuous Dynamics: A Robustness Study
Jan 09, 2024



In this work, we rigorously investigate the robustness of graph neural fractional-order differential equation (FDE) models. This framework extends beyond traditional graph neural (integer-order) ordinary differential equation (ODE) models by implementing the time-fractional Caputo derivative. Utilizing fractional calculus allows our model to consider long-term memory during the feature updating process, diverging from the memoryless Markovian updates seen in traditional graph neural ODE models. The superiority of graph neural FDE models over graph neural ODE models has been established in environments free from attacks or perturbations. While traditional graph neural ODE models have been verified to possess a degree of stability and resilience in the presence of adversarial attacks in existing literature, the robustness of graph neural FDE models, especially under adversarial conditions, remains largely unexplored. This paper undertakes a detailed assessment of the robustness of graph neural FDE models. We establish a theoretical foundation outlining the robustness characteristics of graph neural FDE models, highlighting that they maintain more stringent output perturbation bounds in the face of input and graph topology disturbances, compared to their integer-order counterparts. Our empirical evaluations further confirm the enhanced robustness of graph neural FDE models, highlighting their potential in adversarially robust applications.