 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Events Like Code: A Multi-Agent Programming Framework for Zero-Shot Event Extraction
Nov 17, 2025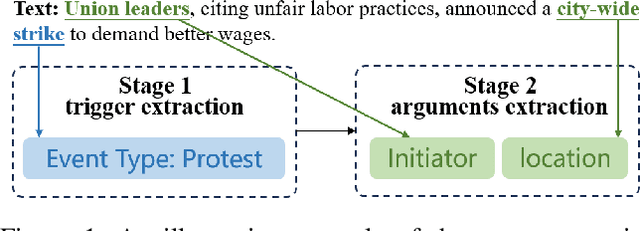
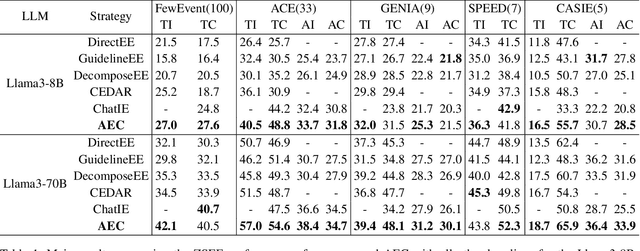
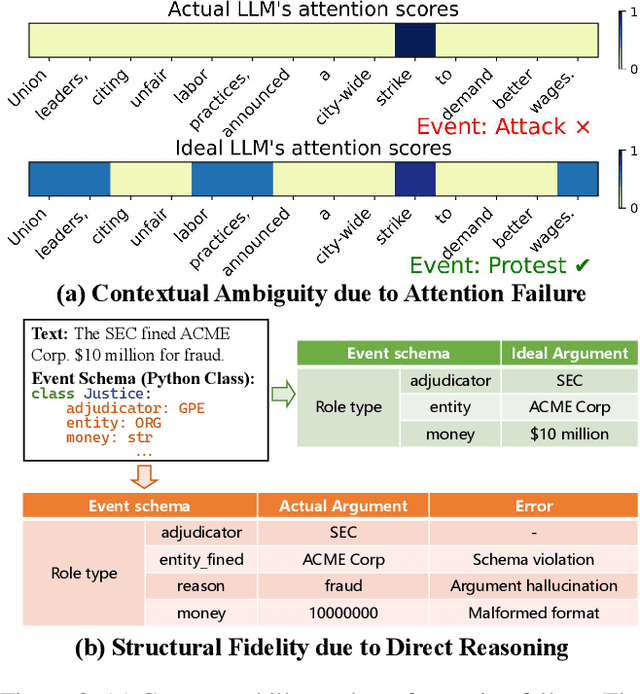
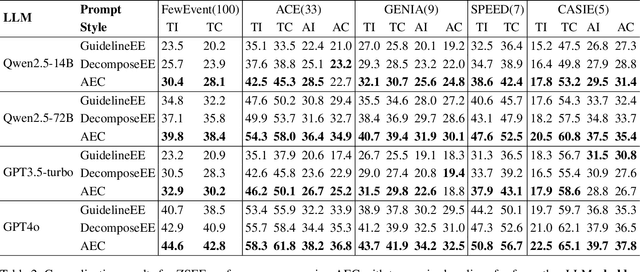
Zero-shot event extraction (ZSEE) remains a significant challenge for large language models (LLMs) due to the need for complex reasoning and domain-specific understanding. Direct prompting often yields incomplete or structurally invalid outputs--such as misclassified triggers, missing arguments, and schema violations. To address these limitations, we present Agent-Event-Coder (AEC), a novel multi-agent framework that treats event extraction like software engineering: as a structured, iterative code-generation process. AEC decomposes ZSEE into specialized subtasks--retrieval, planning, coding, and verification--each handled by a dedicated LLM agent. Event schemas are represented as executable class definitions, enabling deterministic validation and precise feedback via a verification agent. This programming-inspired approach allows for systematic disambiguation and schema enforcement through iterative refinement. By leveraging collaborative agent workflows, AEC enables LLMs to produce precise, complete, and schema-consistent extractions in zero-shot settings. Experiments across five diverse domains and six LLMs demonstrate that AEC consistently outperforms prior zero-shot baselines, showcasing the power of treating event extraction like code generation. The code and data are released on https://github.com/UESTC-GQJ/Agent-Event-Coder.
CodeBoost: Boosting Code LLMs by Squeezing Knowledge from Code Snippets with RL
Aug 07, 2025Code large language models (LLMs) have become indispensable tools for building efficient and automated coding pipelines. Existing models are typically post-trained using reinforcement learning (RL) from general-purpose LLMs using "human instruction-final answer" pairs, where the instructions are usually from manual annotations. However, collecting high-quality coding instructions is both labor-intensive and difficult to scale. On the other hand, code snippets are abundantly available from various sources. This imbalance presents a major bottleneck in instruction-based post-training. We propose CodeBoost, a post-training framework that enhances code LLMs purely from code snippets, without relying on human-annotated instructions. CodeBoost introduces the following key components: (1) maximum-clique curation, which selects a representative and diverse training corpus from code; (2) bi-directional prediction, which enables the model to learn from both forward and backward prediction objectives; (3) error-aware prediction, which incorporates learning signals from both correct and incorrect outputs; (4) heterogeneous augmentation, which diversifies the training distribution to enrich code semantics; and (5) heterogeneous rewarding, which guides model learning through multiple reward types including format correctness and execution feedback from both successes and failures. Extensive experiments across several code LLMs and benchmarks verify that CodeBoost consistently improves performance, demonstrating its effectiveness as a scalable and effective training pipeline.
UAVScenes: A Multi-Modal Dataset for UAVs
Jul 30, 2025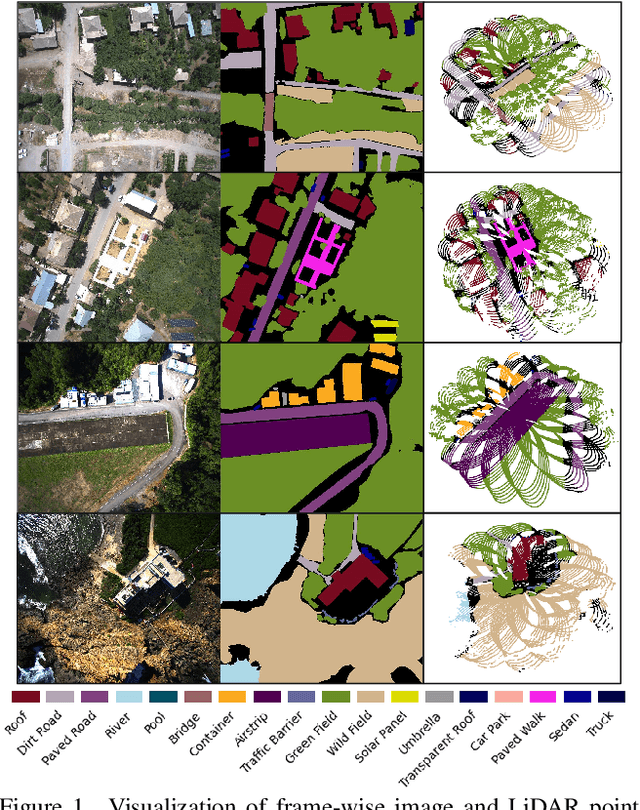
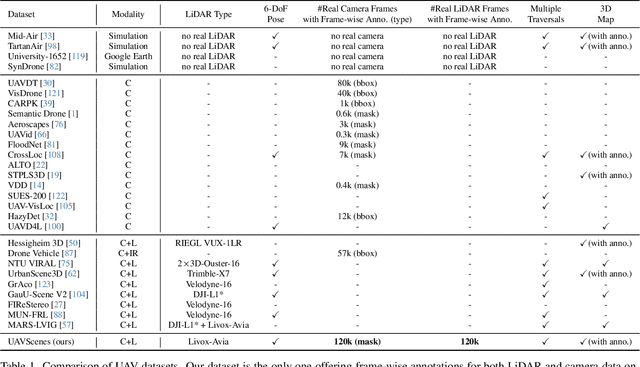
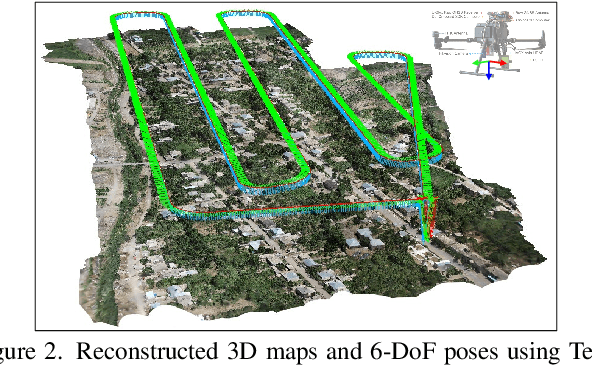
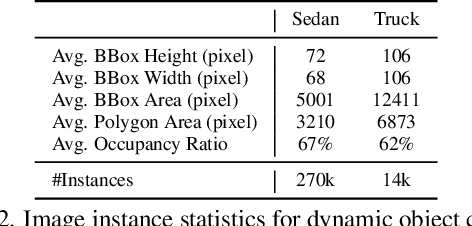
Multi-modal perception is essential for unmanned aerial vehicle (UAV) operations, as it enables a comprehensive understanding of the UAVs' surrounding environment. However, most existing multi-modal UAV datasets are primarily biased toward localization and 3D reconstruction tasks, or only support map-level semantic segmentation due to the lack of frame-wise annotations for both camera images and LiDAR point clouds. This limitation prevents them from being used for high-level scene understanding tasks. To address this gap and advance multi-modal UAV perception, we introduce UAVScenes, a large-scale dataset designed to benchmark various tasks across both 2D and 3D modalities. Our benchmark dataset is built upon the well-calibrated multi-modal UAV dataset MARS-LVIG, originally developed only for simultaneous localization and mapping (SLAM). We enhance this dataset by providing manually labeled semantic annotations for both frame-wise images and LiDAR point clouds, along with accurate 6-degree-of-freedom (6-DoF) poses. These additions enable a wide range of UAV perception tasks, including segmentation, depth estimation, 6-DoF localization, place recognition, and novel view synthesis (NVS). Our dataset is available at https://github.com/sijieaaa/UAVScenes
Bridging Generative and Discriminative Learning: Few-Shot Relation Extraction via Two-Stage Knowledge-Guided Pre-training
May 18, 2025Few-Shot Relation Extraction (FSRE) remains a challenging task due to the scarcity of annotated data and the limited generalization capabilities of existing models. Although large language models (LLMs) have demonstrated potential in FSRE through in-context learning (ICL), their general-purpose training objectives often result in suboptimal performance for task-specific relation extraction. To overcome these challenges, we propose TKRE (Two-Stage Knowledge-Guided Pre-training for Relation Extraction), a novel framework that synergistically integrates LLMs with traditional relation extraction models, bridging generative and discriminative learning paradigms. TKRE introduces two key innovations: (1) leveraging LLMs to generate explanation-driven knowledge and schema-constrained synthetic data, addressing the issue of data scarcity; and (2) a two-stage pre-training strategy combining Masked Span Language Modeling (MSLM) and Span-Level Contrastive Learning (SCL) to enhance relational reasoning and generalization. Together, these components enable TKRE to effectively tackle FSRE tasks. Comprehensive experiments on benchmark datasets demonstrate the efficacy of TKRE, achieving new state-of-the-art performance in FSRE and underscoring its potential for broader application in low-resource scenarios. \footnote{The code and data are released on https://github.com/UESTC-GQJ/TKRE.
BANER: Boundary-Aware LLMs for Few-Shot Named Entity Recognition
Dec 03, 2024



Despite the recent success of two-stage prototypical networks in few-shot named entity recognition (NER), challenges such as over/under-detected false spans in the span detection stage and unaligned entity prototypes in the type classification stage persist. Additionally, LLMs have not proven to be effective few-shot information extractors in general. In this paper, we propose an approach called Boundary-Aware LLMs for Few-Shot Named Entity Recognition to address these issues. We introduce a boundary-aware contrastive learning strategy to enhance the LLM's ability to perceive entity boundaries for generalized entity spans. Additionally, we utilize LoRAHub to align information from the target domain to the source domain, thereby enhancing adaptive cross-domain classification capabilities. Extensive experiments across various benchmarks demonstrate that our framework outperforms prior methods, validating its effectiveness. In particular, the proposed strategies demonstrate effectiveness across a range of LLM architectures. The code and data are released on https://github.com/UESTC-GQJ/BANER.
Question-guided Knowledge Graph Re-scoring and Injection for Knowledge Graph Question Answering
Oct 02, 2024



Knowledge graph question answering (KGQA) involves answering natural language questions by leveraging structured information stored in a knowledge graph. Typically, KGQA initially retrieve a targeted subgraph from a large-scale knowledge graph, which serves as the basis for reasoning models to address queries. However, the retrieved subgraph inevitably brings distraction information for knowledge utilization, impeding the model's ability to perform accurate reasoning. To address this issue, we propose a Question-guided Knowledge Graph Re-scoring method (Q-KGR) to eliminate noisy pathways for the input question, thereby focusing specifically on pertinent factual knowledge. Moreover, we introduce Knowformer, a parameter-efficient method for injecting the re-scored knowledge graph into large language models to enhance their ability to perform factual reasoning. Extensive experiments on multiple KGQA benchmarks demonstrate the superiority of our method over existing systems.
TieFake: Title-Text Similarity and Emotion-Aware Fake News Detection
Apr 19, 2023



Fake news detection aims to detect fake news widely spreading on social media platforms, which can negatively influence the public and the government. Many approaches have been developed to exploit relevant information from news images, text, or videos. However, these methods may suffer from the following limitations: (1) ignore the inherent emotional information of the news, which could be beneficial since it contains the subjective intentions of the authors; (2) pay little attention to the relation (similarity) between the title and textual information in news articles, which often use irrelevant title to attract reader' attention. To this end, we propose a novel Title-Text similarity and emotion-aware Fake news detection (TieFake) method by jointly modeling the multi-modal context information and the author sentiment in a unified framework. Specifically, we respectively employ BERT and ResNeSt to learn the representations for text and images, and utilize publisher emotion extractor to capture the author's subjective emotion in the news content. We also propose a scale-dot product attention mechanism to capture the similarity between title features and textual features. Experiments are conducted on two publicly available multi-modal datasets, and the results demonstrate that our proposed method can significantly improve the performance of fake news detection. Our code is available at https://github.com/UESTC-GQJ/TieFake.